 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Privacy Risks of Algorithmic Fairness
Paper and Code

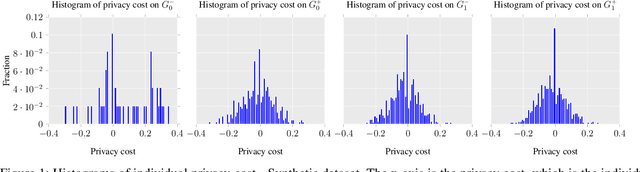

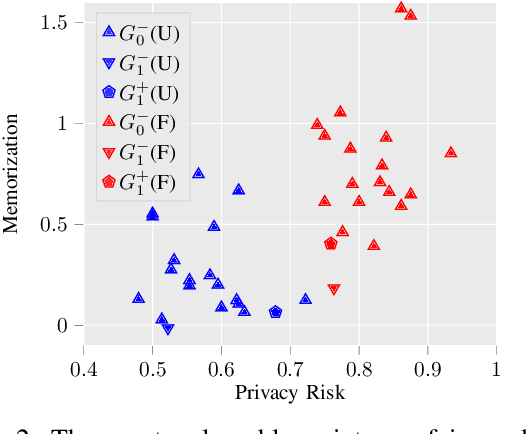
Algorithmic fairness and privacy are essential elements of trustworthy machine learning for critical decision making processes. Fair machine learning algorithms are developed to minimize discrimination against protected groups in machine learning. This is achieved, for example, by imposing a constraint on the model to equalize its behavior across different groups. This can significantly increase the influence of some training data points on the fair model. We study how this change in influence can change the information leakage of the model about its training data. We analyze the privacy risks of statistical notions of fairness (i.e., equalized odds) through the lens of membership inference attacks: inferring whether a data point was used for training a model. We show that fairness comes at the cost of privacy. However, this privacy cost is not distributed equally: the information leakage of fair models increases significantly on the unprivileged subgroups, which suffer from the discrimination in regular models. Furthermore, the more biased the underlying data is, the higher the privacy cost of achieving fairness for the unprivileged subgroups is. We demonstrate this effect on multiple datasets and explain how fairness-aware learning impacts privacy.