 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn RFP dataset for Real, Fake, and Partially fake audio detection
Apr 26, 2024



Recent advances in deep learning have enabled the creation of natural-sounding synthesised speech. However, attackers have also utilised these tech-nologies to conduct attacks such as phishing. Numerous public datasets have been created to facilitate the development of effective detection models. How-ever, available datasets contain only entirely fake audio; therefore, detection models may miss attacks that replace a short section of the real audio with fake audio. In recognition of this problem, the current paper presents the RFP da-taset, which comprises five distinct audio types: partial fake (PF), audio with noise, voice conversion (VC), text-to-speech (TTS), and real. The data are then used to evaluate several detection models, revealing that the available detec-tion models incur a markedly higher equal error rate (EER) when detecting PF audio instead of entirely fake audio. The lowest EER recorded was 25.42%. Therefore, we believe that creators of detection models must seriously consid-er using datasets like RFP that include PF and other types of fake audio.
Starlit: Privacy-Preserving Federated Learning to Enhance Financial Fraud Detection
Jan 22, 2024Federated Learning (FL) is a data-minimization approach enabling collaborative model training across diverse clients with local data, avoiding direct data exchange. However, state-of-the-art FL solutions to identify fraudulent financial transactions exhibit a subset of the following limitations. They (1) lack a formal security definition and proof, (2) assume prior freezing of suspicious customers' accounts by financial institutions (limiting the solutions' adoption), (3) scale poorly, involving either $O(n^2)$ computationally expensive modular exponentiation (where $n$ is the total number of financial institutions) or highly inefficient fully homomorphic encryption, (4) assume the parties have already completed the identity alignment phase, hence excluding it from the implementation, performance evaluation, and security analysis, and (5) struggle to resist clients' dropouts. This work introduces Starlit, a novel scalable privacy-preserving FL mechanism that overcomes these limitations. It has various applications, such as enhancing financial fraud detection, mitigating terrorism, and enhancing digital health. We implemented Starlit and conducted a thorough performance analysis using synthetic data from a key player in global financial transactions. The evaluation indicates Starlit's scalability, efficiency, and accuracy.
Ultimate Power of Inference Attacks: Privacy Risks of High-Dimensional Models
May 29, 2019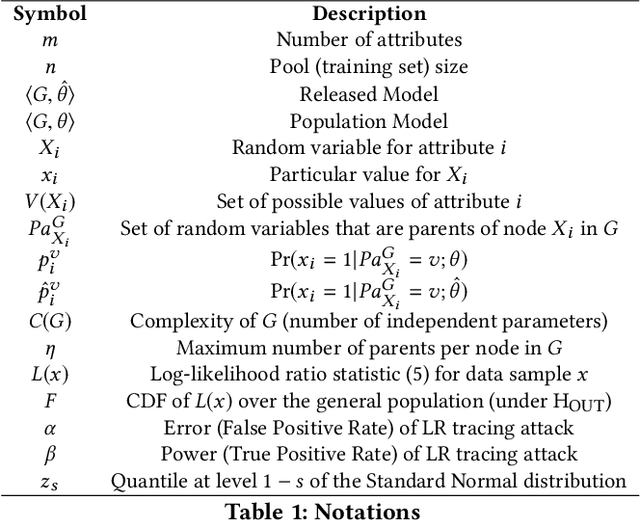
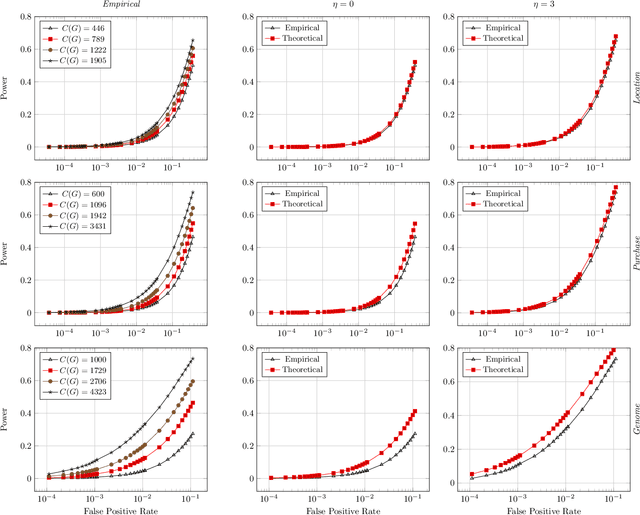
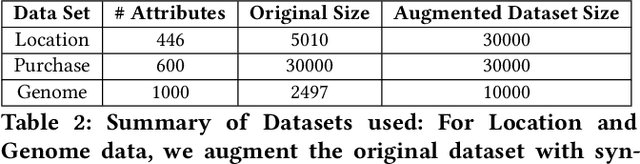
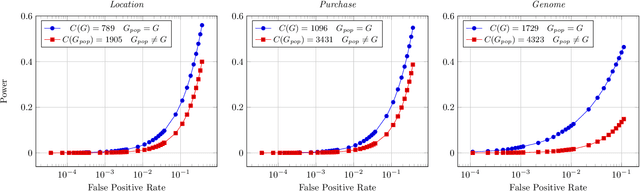
Models leak information about their training data. This enables attackers to infer sensitive information about their training sets, notably determine if a data sample was part of the model's training set. The existing works empirically show the possibility of these tracing (membership inference) attacks against complex models with a large number of parameters. However, the attack results are dependent on the specific training data, can be obtained only after the tedious process of training the model and performing the attack, and are missing any measure of the confidence and unused potential power of the attack. A model designer is interested in identifying which model structures leak more information, how adding new parameters to the model increases its privacy risk, and what is the gain of adding new data points to decrease the overall information leakage. The privacy analysis should also enable designing the most powerful inference attack. In this paper, we design a theoretical framework to analyze the maximum power of tracing attacks against high-dimensional models, with the focus on probabilistic graphical models. We provide a tight upper-bound on the power (true positive rate) of these attacks, with respect to their error (false positive rate). The bound, as it should be, is independent of the knowledge and algorithm of any specific attack, as well as the values of particular samples in the training set. It provides a measure of the potential leakage of a model given its structure, as a function of the structure complexity and the size of training set.