 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding how Differentially Private Generative Models Spend their Privacy Budget
Paper and Code
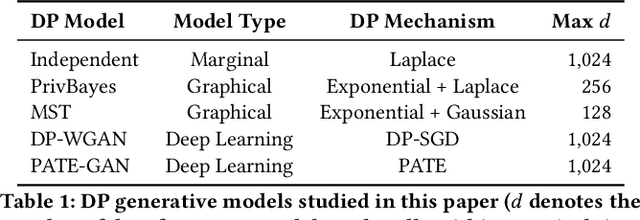
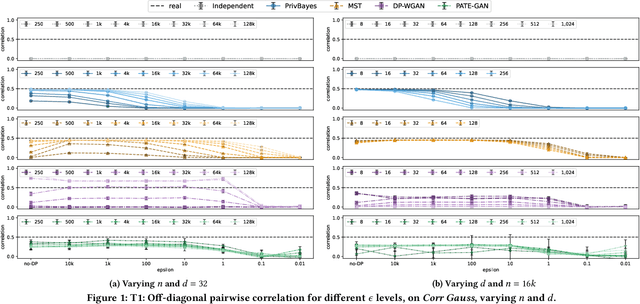
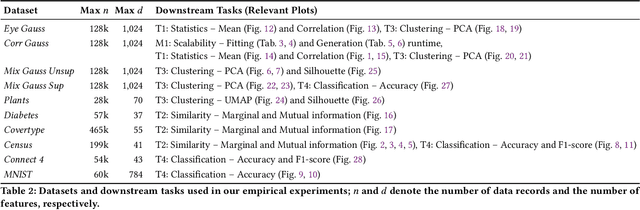
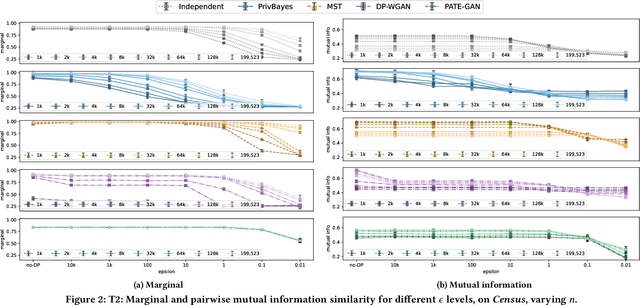
Generative models trained with Differential Privacy (DP) are increasingly used to produce synthetic data while reducing privacy risks. Navigating their specific privacy-utility tradeoffs makes it challenging to determine which models would work best for specific settings/tasks. In this paper, we fill this gap in the context of tabular data by analyzing how DP generative models distribute privacy budgets across rows and columns, arguably the main source of utility degradation. We examine the main factors contributing to how privacy budgets are spent, including underlying modeling techniques, DP mechanisms, and data dimensionality. Our extensive evaluation of both graphical and deep generative models sheds light on the distinctive features that render them suitable for different settings and tasks. We show that graphical models distribute the privacy budget horizontally and thus cannot handle relatively wide datasets while the performance on the task they were optimized for monotonically increases with more data. Deep generative models spend their budget per iteration, so their behavior is less predictable with varying dataset dimensions but could perform better if trained on more features. Also, low levels of privacy ($\epsilon\geq100$) could help some models generalize, achieving better results than without applying DP.