 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Contextual Soft Moderation on Social Media through Contrastive Textual Deviation
Jul 30, 2024Automated soft moderation systems are unable to ascertain if a post supports or refutes a false claim, resulting in a large number of contextual false positives. This limits their effectiveness, for example undermining trust in health experts by adding warnings to their posts or resorting to vague warnings instead of granular fact-checks, which result in desensitizing users. In this paper, we propose to incorporate stance detection into existing automated soft-moderation pipelines, with the goal of ruling out contextual false positives and providing more precise recommendations for social media content that should receive warnings. We develop a textual deviation task called Contrastive Textual Deviation (CTD) and show that it outperforms existing stance detection approaches when applied to soft moderation.We then integrate CTD into the stateof-the-art system for automated soft moderation Lambretta, showing that our approach can reduce contextual false positives from 20% to 2.1%, providing another important building block towards deploying reliable automated soft moderation tools on social media.
PIXELMOD: Improving Soft Moderation of Visual Misleading Information on Twitter
Jul 30, 2024

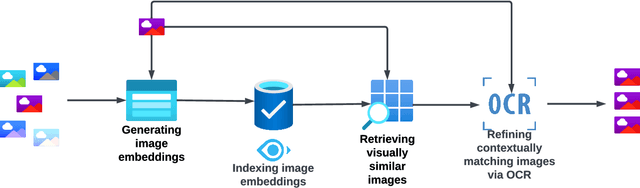
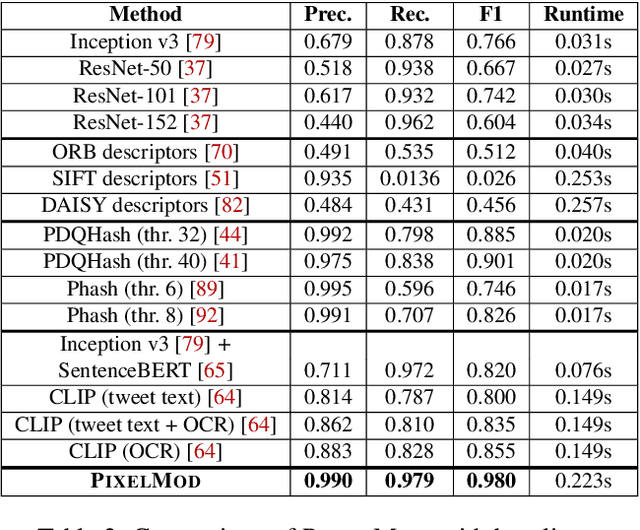
Images are a powerful and immediate vehicle to carry misleading or outright false messages, yet identifying image-based misinformation at scale poses unique challenges. In this paper, we present PIXELMOD, a system that leverages perceptual hashes, vector databases, and optical character recognition (OCR) to efficiently identify images that are candidates to receive soft moderation labels on Twitter. We show that PIXELMOD outperforms existing image similarity approaches when applied to soft moderation, with negligible performance overhead. We then test PIXELMOD on a dataset of tweets surrounding the 2020 US Presidential Election, and find that it is able to identify visually misleading images that are candidates for soft moderation with 0.99% false detection and 2.06% false negatives.
iDRAMA-Scored-2024: A Dataset of the Scored Social Media Platform from 2020 to 2023
May 16, 2024
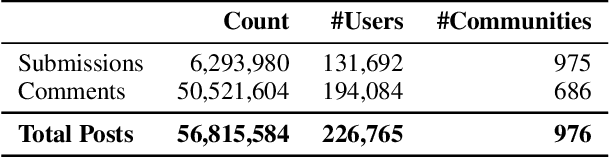
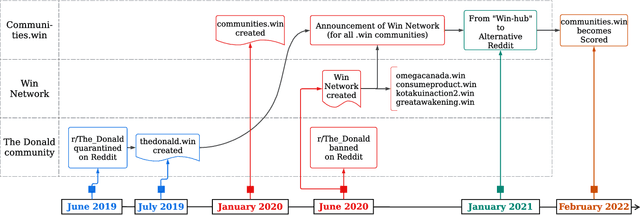

Online web communities often face bans for violating platform policies, encouraging their migration to alternative platforms. This migration, however, can result in increased toxicity and unforeseen consequences on the new platform. In recent years, researchers have collected data from many alternative platforms, indicating coordinated efforts leading to offline events, conspiracy movements, hate speech propagation, and harassment. Thus, it becomes crucial to characterize and understand these alternative platforms. To advance research in this direction, we collect and release a large-scale dataset from Scored -- an alternative Reddit platform that sheltered banned fringe communities, for example, c/TheDonald (a prominent right-wing community) and c/GreatAwakening (a conspiratorial community). Over four years, we collected approximately 57M posts from Scored, with at least 58 communities identified as migrating from Reddit and over 950 communities created since the platform's inception. Furthermore, we provide sentence embeddings of all posts in our dataset, generated through a state-of-the-art model, to further advance the field in characterizing the discussions within these communities. We aim to provide these resources to facilitate their investigations without the need for extensive data collection and processing efforts.