 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Contextual Soft Moderation on Social Media through Contrastive Textual Deviation
Jul 30, 2024Automated soft moderation systems are unable to ascertain if a post supports or refutes a false claim, resulting in a large number of contextual false positives. This limits their effectiveness, for example undermining trust in health experts by adding warnings to their posts or resorting to vague warnings instead of granular fact-checks, which result in desensitizing users. In this paper, we propose to incorporate stance detection into existing automated soft-moderation pipelines, with the goal of ruling out contextual false positives and providing more precise recommendations for social media content that should receive warnings. We develop a textual deviation task called Contrastive Textual Deviation (CTD) and show that it outperforms existing stance detection approaches when applied to soft moderation.We then integrate CTD into the stateof-the-art system for automated soft moderation Lambretta, showing that our approach can reduce contextual false positives from 20% to 2.1%, providing another important building block towards deploying reliable automated soft moderation tools on social media.
Discovering Political Topics in Facebook Discussion threads with Graph Contextualization
Mar 24, 2018
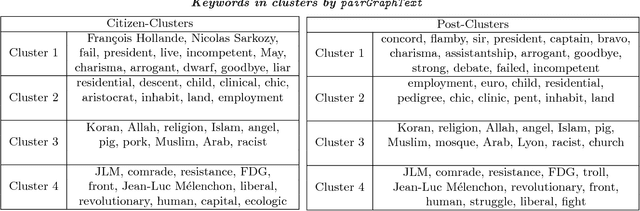
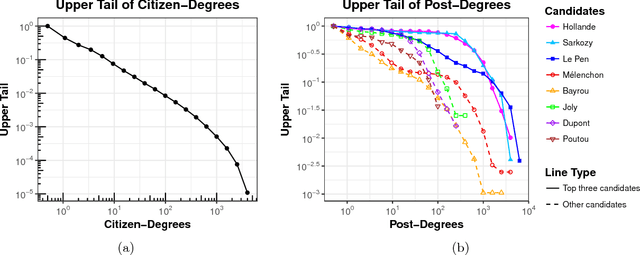
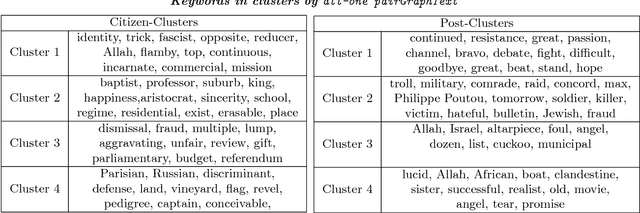
We propose a graph contextualization method, pairGraphText, to study political engagement on Facebook during the 2012 French presidential election. It is a spectral algorithm that contextualizes graph data with text data for online discussion thread. In particular, we examine the Facebook posts of the eight leading candidates and the comments beneath these posts. We find evidence of both (i) candidate-centered structure, where citizens primarily comment on the wall of one candidate and (ii) issue-centered structure (i.e. on political topics), where citizens' attention and expression is primarily directed towards a specific set of issues (e.g. economics, immigration, etc). To identify issue-centered structure, we develop pairGraphText, to analyze a network with high-dimensional features on the interactions (i.e. text). This technique scales to hundreds of thousands of nodes and thousands of unique words. In the Facebook data, spectral clustering without the contextualizing text information finds a mixture of (i) candidate and (ii) issue clusters. The contextualized information with text data helps to separate these two structures. We conclude by showing that the novel methodology is consistent under a statistical model.
My Brain is Full: When More Memory Helps
Jan 23, 2013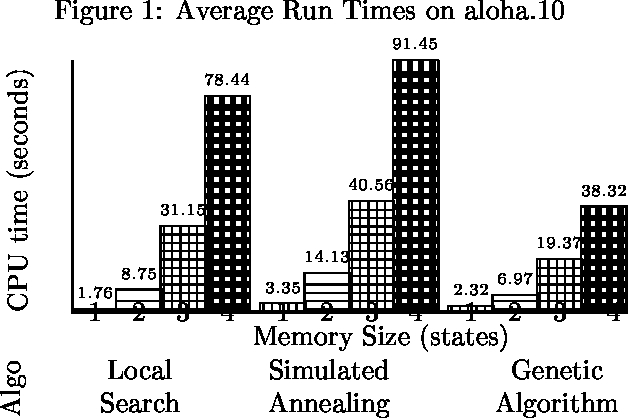
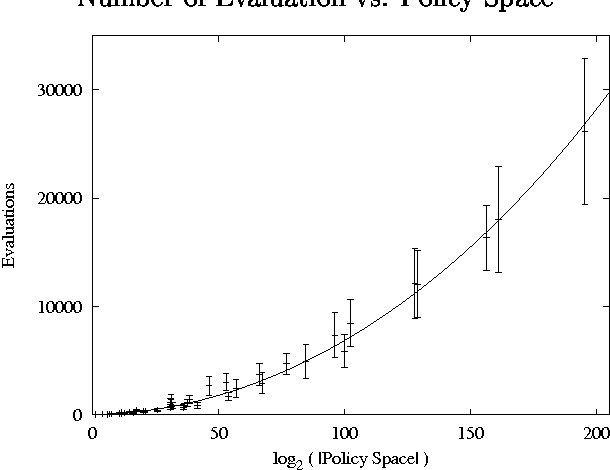
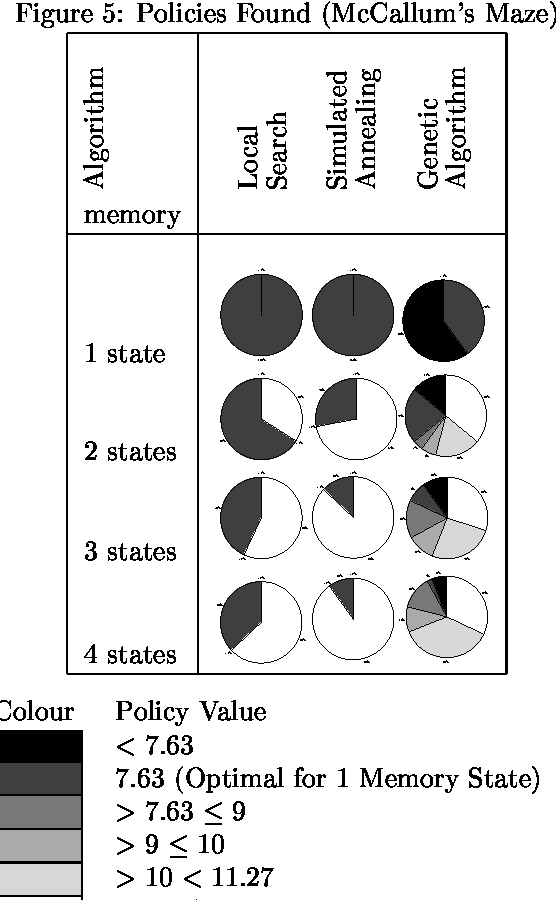
We consider the problem of finding good finite-horizon policies for POMDPs under the expected reward metric. The policies considered are {em free finite-memory policies with limited memory}; a policy is a mapping from the space of observation-memory pairs to the space of action-memeory pairs (the policy updates the memory as it goes), and the number of possible memory states is a parameter of the input to the policy-finding algorithms. The algorithms considered here are preliminary implementations of three search heuristics: local search, simulated annealing, and genetic algorithms. We compare their outcomes to each other and to the optimal policies for each instance. We compare run times of each policy and of a dynamic programming algorithm for POMDPs developed by Hansen that iteratively improves a finite-state controller --- the previous state of the art for finite memory policies. The value of the best policy can only improve as the amount of memory increases, up to the amount needed for an optimal finite-memory policy. Our most surprising finding is that more memory helps in another way: given more memory than is needed for an optimal policy, the algorithms are more likely to converge to optimal-valued policies.