 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathbb{T}$-Stochastic Graphs
Sep 04, 2023Previous statistical approaches to hierarchical clustering for social network analysis all construct an "ultrametric" hierarchy. While the assumption of ultrametricity has been discussed and studied in the phylogenetics literature, it has not yet been acknowledged in the social network literature. We show that "non-ultrametric structure" in the network introduces significant instabilities in the existing top-down recovery algorithms. To address this issue, we introduce an instability diagnostic plot and use it to examine a collection of empirical networks. These networks appear to violate the "ultrametric" assumption. We propose a deceptively simple and yet general class of probabilistic models called $\mathbb{T}$-Stochastic Graphs which impose no topological restrictions on the latent hierarchy. To illustrate this model, we propose six alternative forms of hierarchical network models and then show that all six are equivalent to the $\mathbb{T}$-Stochastic Graph model. These alternative models motivate a novel approach to hierarchical clustering that combines spectral techniques with the well-known Neighbor-Joining algorithm from phylogenetic reconstruction. We prove this spectral approach is statistically consistent.
Estimating Graph Dimension with Cross-validated Eigenvalues
Aug 06, 2021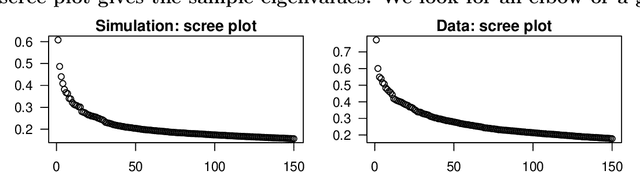
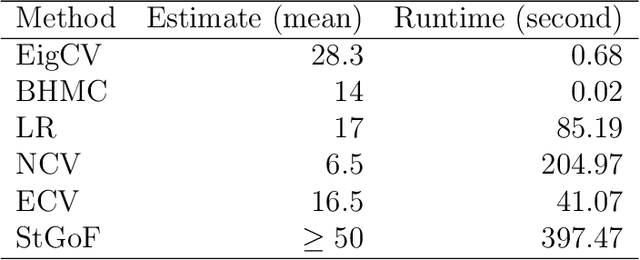
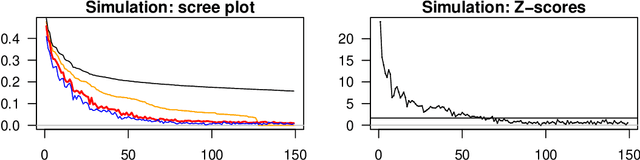
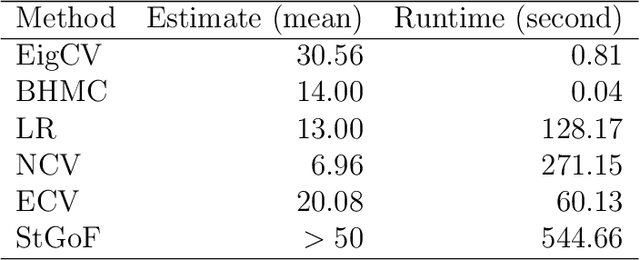
In applied multivariate statistics, estimating the number of latent dimensions or the number of clusters is a fundamental and recurring problem. One common diagnostic is the scree plot, which shows the largest eigenvalues of the data matrix; the user searches for a "gap" or "elbow" in the decreasing eigenvalues; unfortunately, these patterns can hide beneath the bias of the sample eigenvalues. This methodological problem is conceptually difficult because, in many situations, there is only enough signal to detect a subset of the $k$ population dimensions/eigenvectors. In this situation, one could argue that the correct choice of $k$ is the number of detectable dimensions. We alleviate these problems with cross-validated eigenvalues. Under a large class of random graph models, without any parametric assumptions, we provide a p-value for each sample eigenvector. It tests the null hypothesis that this sample eigenvector is orthogonal to (i.e., uncorrelated with) the true latent dimensions. This approach naturally adapts to problems where some dimensions are not statistically detectable. In scenarios where all $k$ dimensions can be estimated, we prove that our procedure consistently estimates $k$. In simulations and a data example, the proposed estimator compares favorably to alternative approaches in both computational and statistical performance.
A New Basis for Sparse PCA
Jul 01, 2020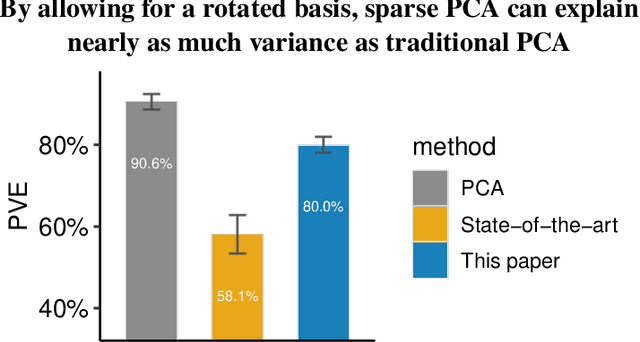
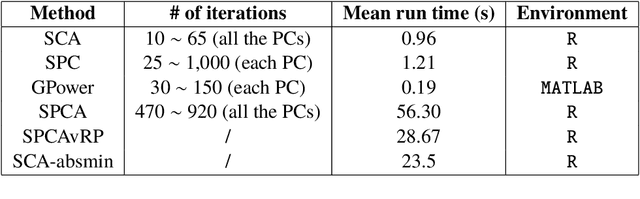
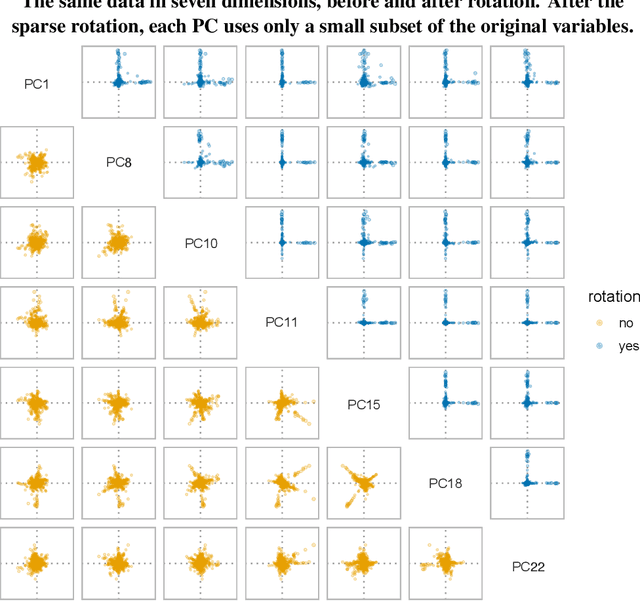
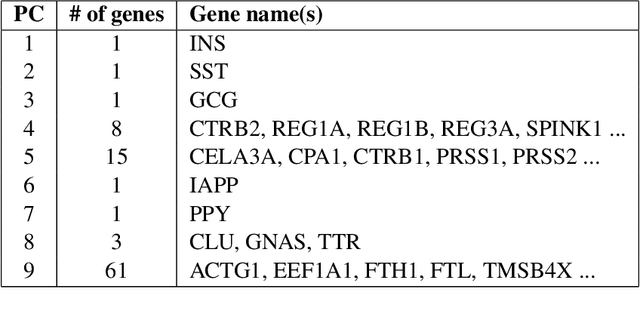
The statistical and computational performance of sparse principal component analysis (PCA) can be dramatically improved when the principal components are allowed to be sparse in a rotated eigenbasis. For this, we propose a new method for sparse PCA. In the simplest version of the algorithm, the component scores and loadings are initialized with a low-rank singular value decomposition. Then, the singular vectors are rotated with orthogonal rotations to make them approximately sparse. Finally, soft-thresholding is applied to the rotated singular vectors. This approach differs from prior approaches because it uses an orthogonal rotation to approximate a sparse basis. Our sparse PCA framework is versatile; for example, it extends naturally to the two-way analysis of a data matrix for simultaneous dimensionality reduction of rows and columns. We identify the close relationship between sparse PCA and independent component analysis for separating sparse signals. We provide empirical evidence showing that for the same level of sparsity, the proposed sparse PCA method is more stable and can explain more variance compared to alternative methods. Through three applications---sparse coding of images, analysis of transcriptome sequencing data, and large-scale clustering of Twitter accounts, we demonstrate the usefulness of sparse PCA in exploring modern multivariate data.
Targeted sampling from massive Blockmodel graphs with personalized PageRank
Oct 04, 2019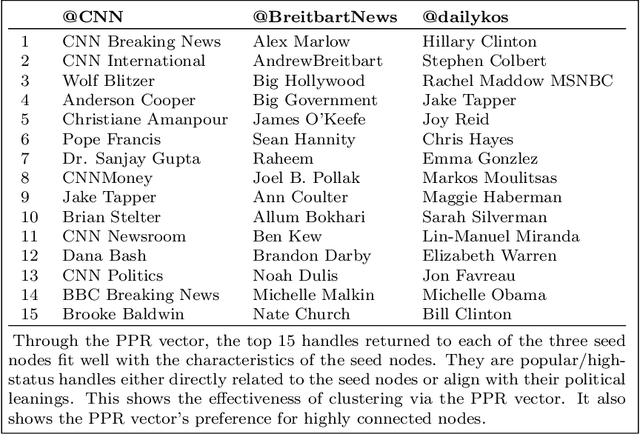
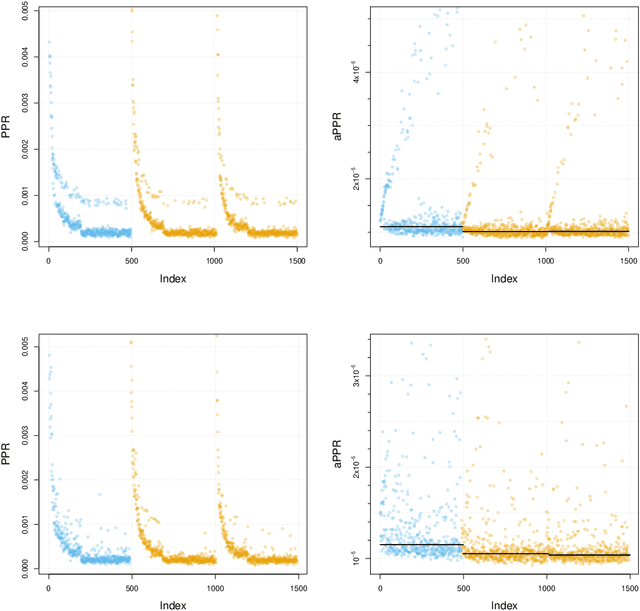
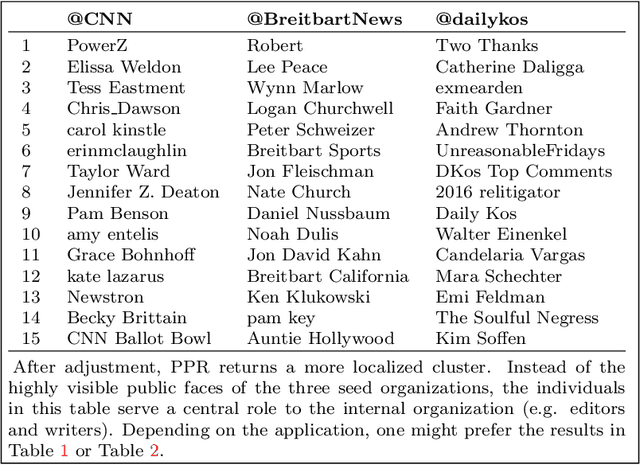
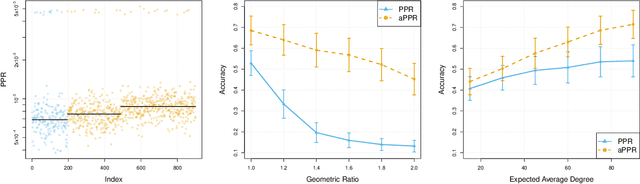
This paper provides statistical theory and intuition for Personalized PageRank (PPR), a popular technique that samples a small community from a massive network. We study a setting where the entire network is expensive to thoroughly obtain or maintain, but we can start from a seed node of interest and "crawl" the network to find other nodes through their connections. By crawling the graph in a designed way, the PPR vector can be approximated without querying the entire massive graph, making it an alternative to snowball sampling. Using the Degree-Corrected Stochastic Blockmodel, we study whether the PPR vector can select nodes that belong to the same block as the seed node. We provide a simple and interpretable form for the PPR vector, highlighting its biases towards high degree nodes outside of the target block. We examine a simple adjustment based on node degrees and establish consistency results for PPR clustering that allows for directed graphs. We illustrate the method with the Twitter friendship graph and find that (i) the adjusted and unadjusted PPR techniques are complementary approaches, where the adjustment makes the results particularly localized around the seed node and (ii) the bias adjustment greatly benefits from degree regularization.
Understanding Regularized Spectral Clustering via Graph Conductance
Oct 31, 2018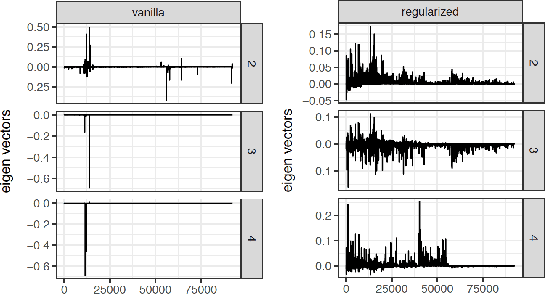
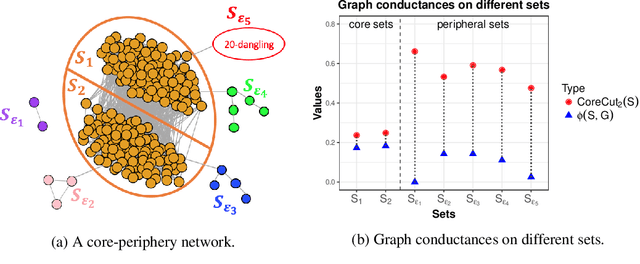
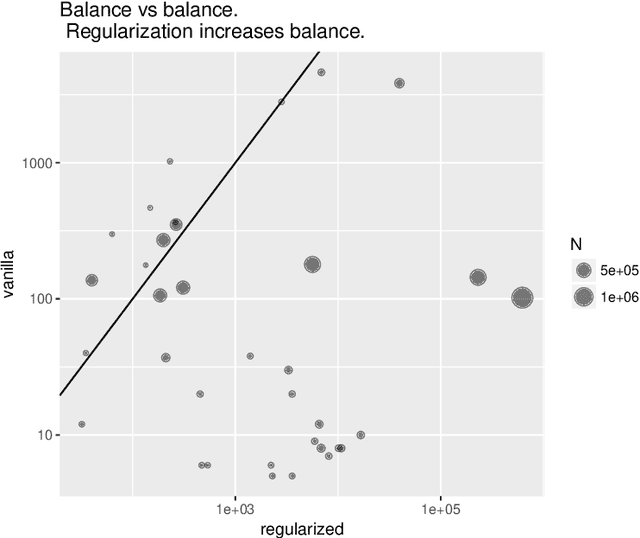
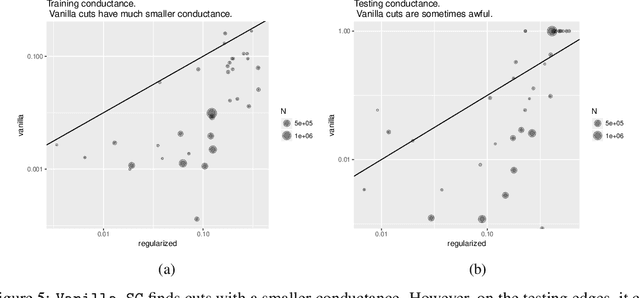
This paper uses the relationship between graph conductance and spectral clustering to study (i) the failures of spectral clustering and (ii) the benefits of regularization. The explanation is simple. Sparse and stochastic graphs create a lot of small trees that are connected to the core of the graph by only one edge. Graph conductance is sensitive to these noisy `dangling sets'. Spectral clustering inherits this sensitivity. The second part of the paper starts from a previously proposed form of regularized spectral clustering and shows that it is related to the graph conductance on a `regularized graph'. We call the conductance on the regularized graph CoreCut. Based upon previous arguments that relate graph conductance to spectral clustering (e.g. Cheeger inequality), minimizing CoreCut relaxes to regularized spectral clustering. Simple inspection of CoreCut reveals why it is less sensitive to small cuts in the graph. Together, these results show that unbalanced partitions from spectral clustering can be understood as overfitting to noise in the periphery of a sparse and stochastic graph. Regularization fixes this overfitting. In addition to this statistical benefit, these results also demonstrate how regularization can improve the computational speed of spectral clustering. We provide simulations and data examples to illustrate these results.
Discovering Political Topics in Facebook Discussion threads with Graph Contextualization
Mar 24, 2018
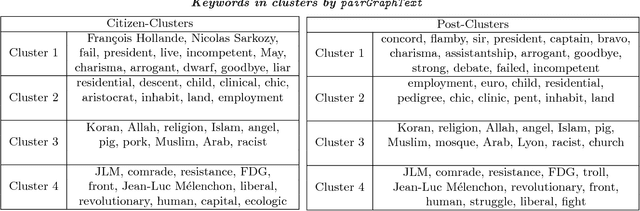
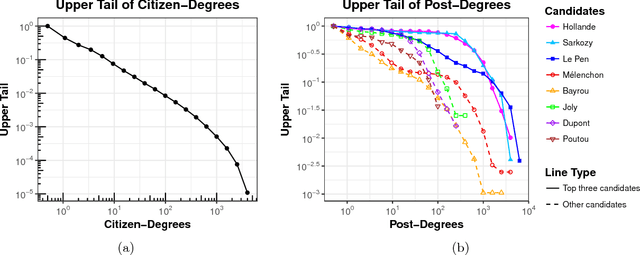
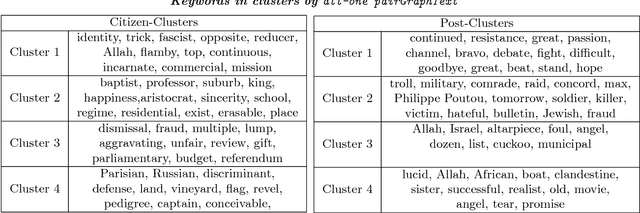
We propose a graph contextualization method, pairGraphText, to study political engagement on Facebook during the 2012 French presidential election. It is a spectral algorithm that contextualizes graph data with text data for online discussion thread. In particular, we examine the Facebook posts of the eight leading candidates and the comments beneath these posts. We find evidence of both (i) candidate-centered structure, where citizens primarily comment on the wall of one candidate and (ii) issue-centered structure (i.e. on political topics), where citizens' attention and expression is primarily directed towards a specific set of issues (e.g. economics, immigration, etc). To identify issue-centered structure, we develop pairGraphText, to analyze a network with high-dimensional features on the interactions (i.e. text). This technique scales to hundreds of thousands of nodes and thousands of unique words. In the Facebook data, spectral clustering without the contextualizing text information finds a mixture of (i) candidate and (ii) issue clusters. The contextualized information with text data helps to separate these two structures. We conclude by showing that the novel methodology is consistent under a statistical model.
Network driven sampling; a critical threshold for design effects
Jun 01, 2017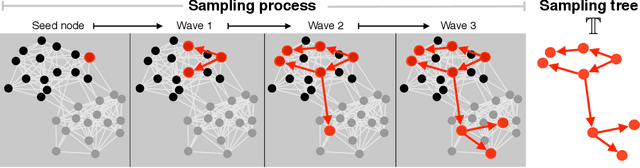
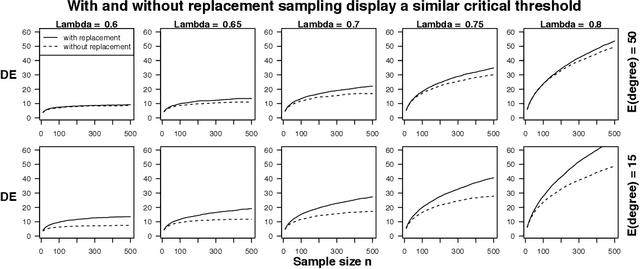
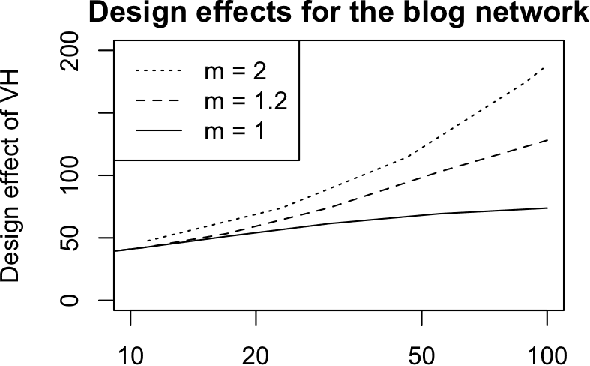
Web crawling, snowball sampling, and respondent-driven sampling (RDS) are three types of network sampling techniques used to contact individuals in hard-to-reach populations. This paper studies these procedures as a Markov process on the social network that is indexed by a tree. Each node in this tree corresponds to an observation and each edge in the tree corresponds to a referral. Indexing with a tree (instead of a chain) allows for the sampled units to refer multiple future units into the sample. In survey sampling, the design effect characterizes the additional variance induced by a novel sampling strategy. If the design effect is some value $DE$, then constructing an estimator from the novel design makes the variance of the estimator $DE$ times greater than it would be under a simple random sample with the same sample size $n$. Under certain assumptions on the referral tree, the design effect of network sampling has a critical threshold that is a function of the referral rate $m$ and the clustering structure in the social network, represented by the second eigenvalue of the Markov transition matrix, $\lambda_2$. If $m < 1/\lambda_2^2$, then the design effect is finite (i.e. the standard estimator is $\sqrt{n}$-consistent). However, if $m > 1/\lambda_2^2$, then the design effect grows with $n$ (i.e. the standard estimator is no longer $\sqrt{n}$-consistent). Past this critical threshold, the standard error of the estimator converges at the slower rate of $n^{\log_m \lambda_2}$. The Markov model allows for nodes to be resampled; computational results show that the findings hold in without-replacement sampling. To estimate confidence intervals that adapt to the correct level of uncertainty, a novel resampling procedure is proposed. Computational experiments compare this procedure to previous techniques.
Covariate-assisted spectral clustering
Oct 30, 2016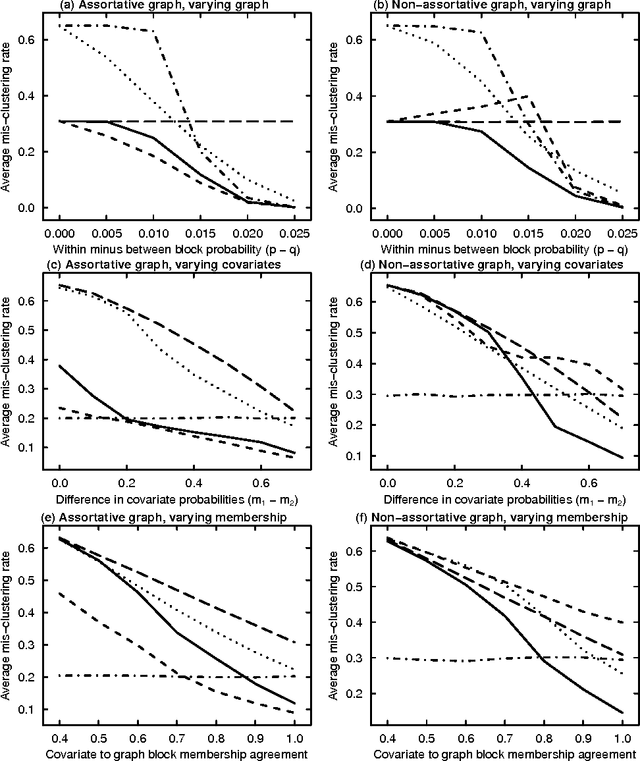
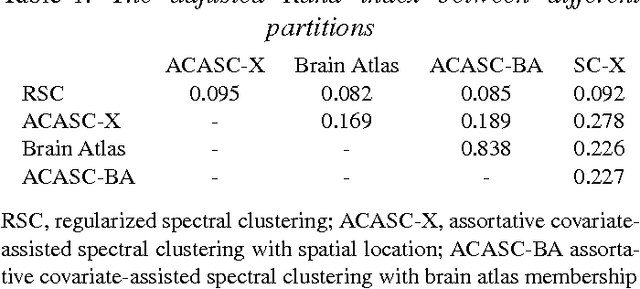
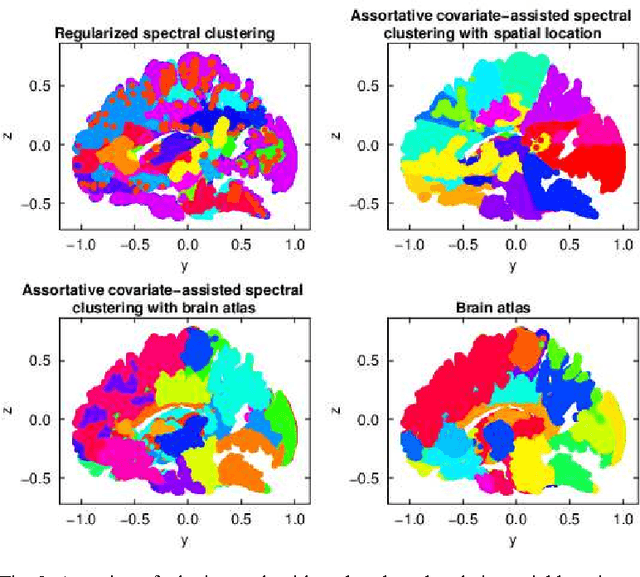
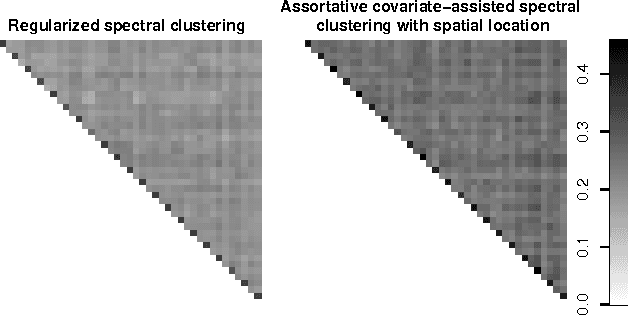
Biological and social systems consist of myriad interacting units. The interactions can be represented in the form of a graph or network. Measurements of these graphs can reveal the underlying structure of these interactions, which provides insight into the systems that generated the graphs. Moreover, in applications such as connectomics, social networks, and genomics, graph data are accompanied by contextualizing measures on each node. We utilize these node covariates to help uncover latent communities in a graph, using a modification of spectral clustering. Statistical guarantees are provided under a joint mixture model that we call the node-contextualized stochastic blockmodel, including a bound on the mis-clustering rate. The bound is used to derive conditions for achieving perfect clustering. For most simulated cases, covariate-assisted spectral clustering yields results superior to regularized spectral clustering without node covariates and to an adaptation of canonical correlation analysis. We apply our clustering method to large brain graphs derived from diffusion MRI data, using the node locations or neurological region membership as covariates. In both cases, covariate-assisted spectral clustering yields clusters that are easier to interpret neurologically.
* 28 pages, 4 figures, includes substantial changes to theoretical results
Co-clustering for directed graphs: the Stochastic co-Blockmodel and spectral algorithm Di-Sim
Jan 08, 2015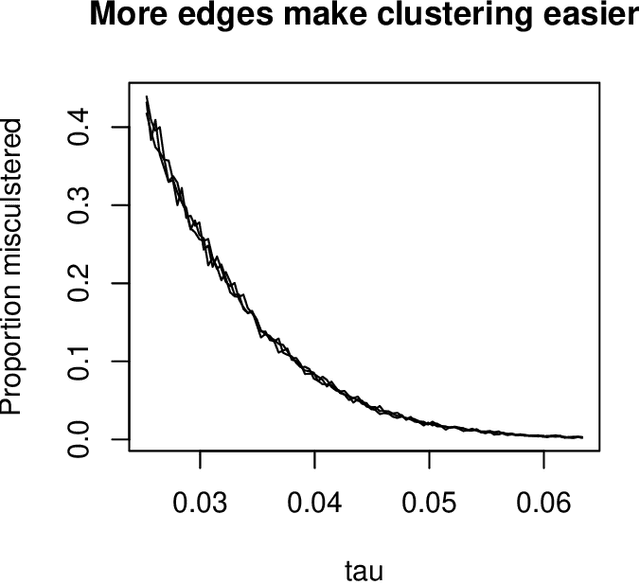
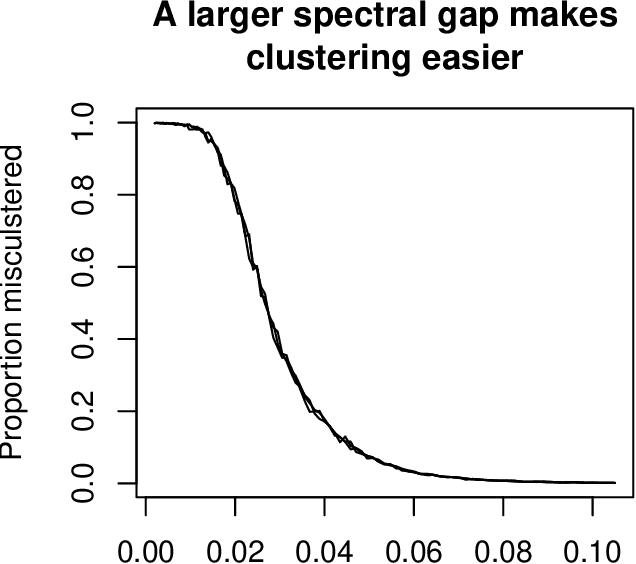
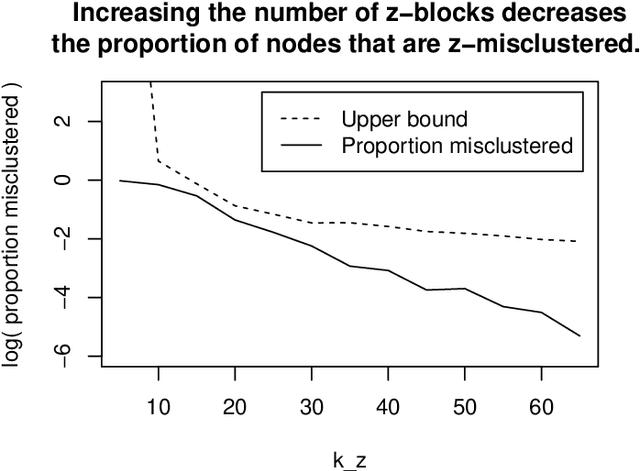
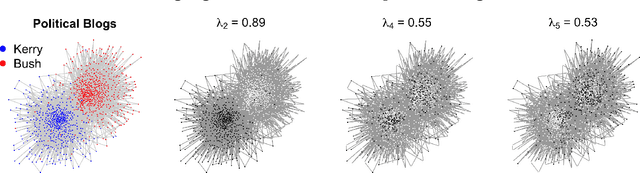
Directed graphs have asymmetric connections, yet the current graph clustering methodologies cannot identify the potentially global structure of these asymmetries. We give a spectral algorithm called di-sim that builds on a dual measure of similarity that correspond to how a node (i) sends and (ii) receives edges. Using di-sim, we analyze the global asymmetries in the networks of Enron emails, political blogs, and the c elegans neural connectome. In each example, a small subset of nodes have persistent asymmetries; these nodes send edges with one cluster, but receive edges with another cluster. Previous approaches would have assigned these asymmetric nodes to only one cluster, failing to identify their sending/receiving asymmetries. Regularization and "projection" are two steps of di-sim that are essential for spectral clustering algorithms to work in practice. The theoretical results show that these steps make the algorithm weakly consistent under the degree corrected Stochastic co-Blockmodel, a model that generalizes the Stochastic Blockmodel to allow for both (i) degree heterogeneity and (ii) the global asymmetries that we intend to detect. The theoretical results make no assumptions on the smallest degree nodes. Instead, the theorem requires that the average degree grows sufficiently fast and that the weak consistency only applies to the subset of the nodes with sufficiently large leverage scores. The results results also apply to bipartite graphs.
A note relating ridge regression and OLS p-values to preconditioned sparse penalized regression
Dec 03, 2014When the design matrix has orthonormal columns, "soft thresholding" the ordinary least squares (OLS) solution produces the Lasso solution [Tibshirani, 1996]. If one uses the Puffer preconditioned Lasso [Jia and Rohe, 2012], then this result generalizes from orthonormal designs to full rank designs (Theorem 1). Theorem 2 refines the Puffer preconditioner to make the Lasso select the same model as removing the elements of the OLS solution with the largest p-values. Using a generalized Puffer preconditioner, Theorem 3 relates ridge regression to the preconditioned Lasso; this result is for the high dimensional setting, p > n. Where the standard Lasso is akin to forward selection [Efron et al., 2004], Theorems 1, 2, and 3 suggest that the preconditioned Lasso is more akin to backward elimination. These results hold for sparse penalties beyond l1; for a broad class of sparse and non-convex techniques (e.g. SCAD and MC+), the results hold for all local minima.