 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Adaptive Graph Learning for Large-Scale Traffic Forecasting
Jun 08, 2025Traffic prediction is a critical task in spatial-temporal forecasting with broad applications in travel planning and urban management. Adaptive graph convolution networks have emerged as mainstream solutions due to their ability to learn node embeddings in a data-driven manner and capture complex latent dependencies. However, existing adaptive graph learning methods for traffic forecasting often either ignore the regularization of node embeddings, which account for a significant proportion of model parameters, or face scalability issues from expensive graph convolution operations. To address these challenges, we propose a Regularized Adaptive Graph Learning (RAGL) model. First, we introduce a regularized adaptive graph learning framework that synergizes Stochastic Shared Embedding (SSE) and adaptive graph convolution via a residual difference mechanism, achieving both embedding regularization and noise suppression. Second, to ensure scalability on large road networks, we develop the Efficient Cosine Operator (ECO), which performs graph convolution based on the cosine similarity of regularized embeddings with linear time complexity. Extensive experiments on four large-scale real-world traffic datasets show that RAGL consistently outperforms state-of-the-art methods in terms of prediction accuracy and exhibits competitive computational efficiency.
Semantic Scene Completion Based 3D Traversability Estimation for Off-Road Terrains
Dec 11, 2024Off-road environments present significant challenges for autonomous ground vehicles due to the absence of structured roads and the presence of complex obstacles, such as uneven terrain, vegetation, and occlusions. Traditional perception algorithms, designed primarily for structured environments, often fail under these conditions, leading to inaccurate traversability estimations. In this paper, ORDformer, a novel multimodal method that combines LiDAR point clouds with monocular images, is proposed to generate dense traversable occupancy predictions from a forward-facing perspective. By integrating multimodal data, environmental feature extraction is enhanced, which is crucial for accurate occupancy estimation in complex terrains. Furthermore, RELLIS-OCC, a dataset with 3D traversable occupancy annotations, is introduced, incorporating geometric features such as step height, slope, and unevenness. Through a comprehensive analysis of vehicle obstacle-crossing conditions and the incorporation of vehicle body structure constraints, four traversability cost labels are generated: lethal, medium-cost, low-cost, and free. Experimental results demonstrate that ORDformer outperforms existing approaches in 3D traversable area recognition, particularly in off-road environments with irregular geometries and partial occlusions. Specifically, ORDformer achieves over a 20\% improvement in scene completion IoU compared to other models. The proposed framework is scalable and adaptable to various vehicle platforms, allowing for adjustments to occupancy grid parameters and the integration of advanced dynamic models for traversability cost estimation.
CHAMMI: A benchmark for channel-adaptive models in microscopy imaging
Oct 30, 2023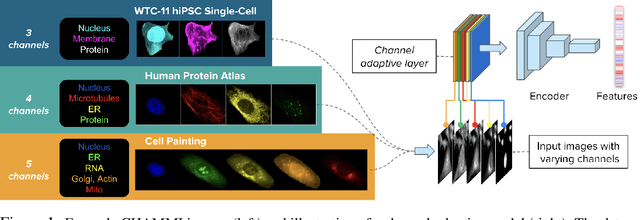
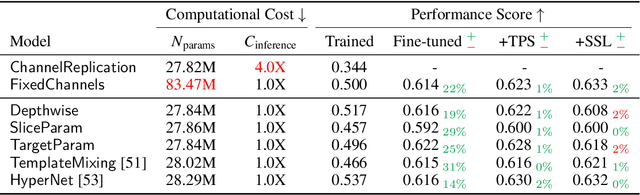
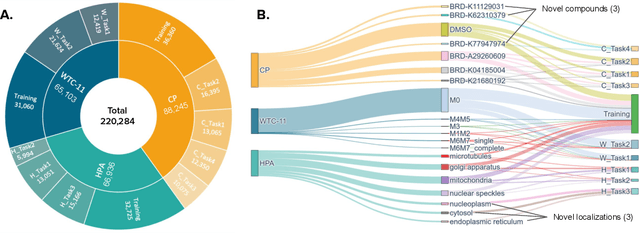

Most neural networks assume that input images have a fixed number of channels (three for RGB images). However, there are many settings where the number of channels may vary, such as microscopy images where the number of channels changes depending on instruments and experimental goals. Yet, there has not been a systemic attempt to create and evaluate neural networks that are invariant to the number and type of channels. As a result, trained models remain specific to individual studies and are hardly reusable for other microscopy settings. In this paper, we present a benchmark for investigating channel-adaptive models in microscopy imaging, which consists of 1) a dataset of varied-channel single-cell images, and 2) a biologically relevant evaluation framework. In addition, we adapted several existing techniques to create channel-adaptive models and compared their performance on this benchmark to fixed-channel, baseline models. We find that channel-adaptive models can generalize better to out-of-domain tasks and can be computationally efficient. We contribute a curated dataset (https://doi.org/10.5281/zenodo.7988357) and an evaluation API (https://github.com/broadinstitute/MorphEm.git) to facilitate objective comparisons in future research and applications.