 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play Grounding of Reasoning in Multimodal Large Language Models
Paper and Code

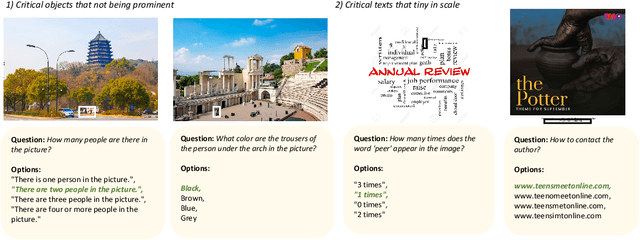


The surge of Multimodal Large Language Models (MLLMs), given their prominent emergent capabilities in instruction following and reasoning, has greatly advanced the field of visual reasoning. However, constrained by their non-lossless image tokenization, most MLLMs fall short of comprehensively capturing details of text and objects, especially in high-resolution images. To address this, we propose P2G, a novel framework for plug-and-play grounding of reasoning in MLLMs. Specifically, P2G exploits the tool-usage potential of MLLMs to employ expert agents to achieve on-the-fly grounding to critical visual and textual objects of image, thus achieving deliberate reasoning via multimodal prompting. We further create P2GB, a benchmark aimed at assessing MLLMs' ability to understand inter-object relationships and text in challenging high-resolution images. Comprehensive experiments on visual reasoning tasks demonstrate the superiority of P2G. Noteworthy, P2G achieved comparable performance with GPT-4V on P2GB, with a 7B backbone. Our work highlights the potential of plug-and-play grounding of reasoning and opens up a promising alternative beyond model scaling.