 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Guided Biomechanical Profiling: A White-Box Framework for Opportunistic Screening of Spinal Instability on Routine CT
Mar 17, 2026Routine oncologic computed tomography (CT) presents an ideal opportunity for screening spinal instability, yet prophylactic stabilization windows are frequently missed due to the complex geometric reasoning required by the Spinal Instability Neoplastic Score (SINS). Automating SINS is fundamentally hindered by metastatic osteolysis, which induces topological ambiguity that confounds standard segmentation and black-box AI. We propose Topology-Guided Biomechanical Profiling (TGBP), an auditable white-box framework decoupling anatomical perception from structural reasoning. TGBP anchors SINS assessment on two deterministic geometric innovations: (i) canal-referenced partitioning to resolve posterolateral boundary ambiguity, and (ii) context-aware morphometric normalization via covariance-based oriented bounding boxes (OBB) to quantify vertebral collapse. Integrated with auxiliary radiomic and large language model (LLM) modules, TGBP provides an end-to-end, interpretable SINS evaluation. Validated on a multi-center, multi-cancer cohort ($N=482$), TGBP achieved 90.2\% accuracy in 3-tier stability triage. In a blinded reader study ($N=30$), TGBP significantly outperformed medical oncologists on complex structural features ($κ=0.857$ vs.\ $0.570$) and prevented compounding errors in Total Score estimation ($κ=0.625$ vs.\ $0.207$), democratizing expert-level opportunistic screening.
InViC: Intent-aware Visual Cues for Medical Visual Question Answering
Mar 17, 2026Medical visual question answering (Med-VQA) aims to answer clinically relevant questions grounded in medical images. However, existing multimodal large language models (MLLMs) often exhibit shortcut answering, producing plausible responses by exploiting language priors or dataset biases while insufficiently attending to visual evidence. This behavior undermines clinical reliability, especially when subtle imaging findings are decisive. We propose a lightweight plug-in framework, termed Intent-aware Visual Cues (InViC), to explicitly enhance image-based answer generation in medical VQA. InViC introduces a Cue Tokens Extraction (CTE) module that distills dense visual tokens into a compact set of K question-conditioned cue tokens, which serve as structured visual intermediaries injected into the LLM decoder to promote intent-aligned visual evidence. To discourage bypassing of visual information, we further design a two-stage fine-tuning strategy with a cue-bottleneck attention mask. In Stage I, we employ an attention mask to block the LLM's direct view of raw visual features, thereby funneling all visual evidence through the cue pathway. In Stage II, standard causal attention is restored to train the LLM to jointly exploit the visual and cue tokens. We evaluate InViC on three public Med-VQA benchmarks (VQA-RAD, SLAKE, and ImageCLEF VQA-Med 2019) across multiple representative MLLMs. InViC consistently improves over zero-shot inference and standard LoRA fine-tuning, demonstrating that intent-aware visual cues with bottlenecked training is a practical and effective strategy for improving trustworthy Med-VQA.
Enjoying Information Dividend: Gaze Track-based Medical Weakly Supervised Segmentation
May 28, 2025Weakly supervised semantic segmentation (WSSS) in medical imaging struggles with effectively using sparse annotations. One promising direction for WSSS leverages gaze annotations, captured via eye trackers that record regions of interest during diagnostic procedures. However, existing gaze-based methods, such as GazeMedSeg, do not fully exploit the rich information embedded in gaze data. In this paper, we propose GradTrack, a framework that utilizes physicians' gaze track, including fixation points, durations, and temporal order, to enhance WSSS performance. GradTrack comprises two key components: Gaze Track Map Generation and Track Attention, which collaboratively enable progressive feature refinement through multi-level gaze supervision during the decoding process. Experiments on the Kvasir-SEG and NCI-ISBI datasets demonstrate that GradTrack consistently outperforms existing gaze-based methods, achieving Dice score improvements of 3.21\% and 2.61\%, respectively. Moreover, GradTrack significantly narrows the performance gap with fully supervised models such as nnUNet.
CoSAM: Self-Correcting SAM for Domain Generalization in 2D Medical Image Segmentation
Nov 15, 2024



Medical images often exhibit distribution shifts due to variations in imaging protocols and scanners across different medical centers. Domain Generalization (DG) methods aim to train models on source domains that can generalize to unseen target domains. Recently, the segment anything model (SAM) has demonstrated strong generalization capabilities due to its prompt-based design, and has gained significant attention in image segmentation tasks. Existing SAM-based approaches attempt to address the need for manual prompts by introducing prompt generators that automatically generate these prompts. However, we argue that auto-generated prompts may not be sufficiently accurate under distribution shifts, potentially leading to incorrect predictions that still require manual verification and correction by clinicians. To address this challenge, we propose a method for 2D medical image segmentation called Self-Correcting SAM (CoSAM). Our approach begins by generating coarse masks using SAM in a prompt-free manner, providing prior prompts for the subsequent stages, and eliminating the need for prompt generators. To automatically refine these coarse masks, we introduce a generalized error decoder that simulates the correction process typically performed by clinicians. Furthermore, we generate diverse prompts as feedback based on the corrected masks, which are used to iteratively refine the predictions within a self-correcting loop, enhancing the generalization performance of our model. Extensive experiments on two medical image segmentation benchmarks across multiple scenarios demonstrate the superiority of CoSAM over state-of-the-art SAM-based methods.
From Few to More: Scribble-based Medical Image Segmentation via Masked Context Modeling and Continuous Pseudo Labels
Aug 23, 2024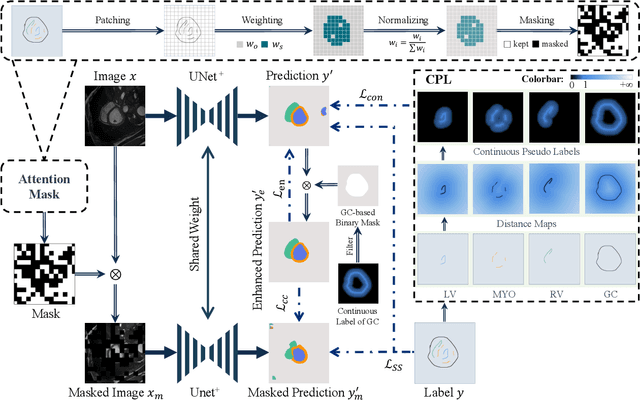
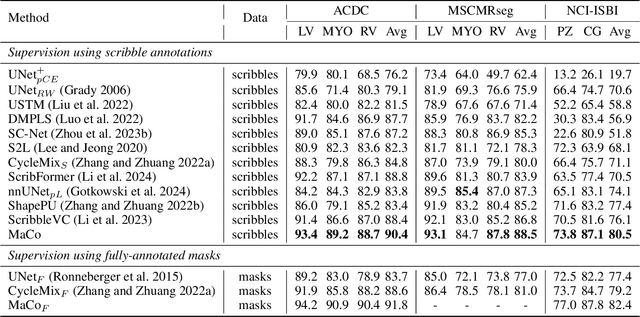
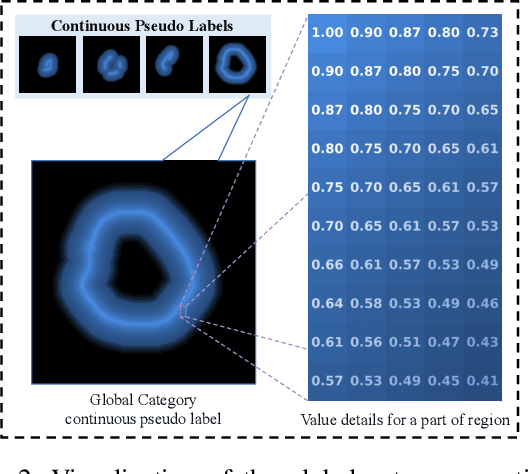

Scribble-based weakly supervised segmentation techniques offer comparable performance to fully supervised methods while significantly reducing annotation costs, making them an appealing alternative. Existing methods often rely on auxiliary tasks to enforce semantic consistency and use hard pseudo labels for supervision. However, these methods often overlook the unique requirements of models trained with sparse annotations. Since the model must predict pixel-wise segmentation maps with limited annotations, the ability to handle varying levels of annotation richness is critical. In this paper, we adopt the principle of `from few to more' and propose MaCo, a weakly supervised framework designed for medical image segmentation. MaCo employs masked context modeling (MCM) and continuous pseudo labels (CPL). MCM uses an attention-based masking strategy to disrupt the input image, compelling the model's predictions to remain consistent with those of the original image. CPL converts scribble annotations into continuous pixel-wise labels by applying an exponential decay function to distance maps, resulting in continuous maps that represent the confidence of each pixel belonging to a specific category, rather than using hard pseudo labels. We evaluate MaCo against other weakly supervised methods using three public datasets. The results indicate that MaCo outperforms competing methods across all datasets, setting a new record in weakly supervised medical image segmentation.