 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
Jul 18, 2024



In this paper, we investigate the use of diffusion models which are pre-trained on large-scale image-caption pairs for open-vocabulary 3D semantic understanding. We propose a novel method, namely Diff2Scene, which leverages frozen representations from text-image generative models, along with salient-aware and geometric-aware masks, for open-vocabulary 3D semantic segmentation and visual grounding tasks. Diff2Scene gets rid of any labeled 3D data and effectively identifies objects, appearances, materials, locations and their compositions in 3D scenes. We show that it outperforms competitive baselines and achieves significant improvements over state-of-the-art methods. In particular, Diff2Scene improves the state-of-the-art method on ScanNet200 by 12%.
Experimental Investigation on the Friction-induced Vibration with Periodic Characteristics in a Running-in Process under Lubrication
Nov 24, 2021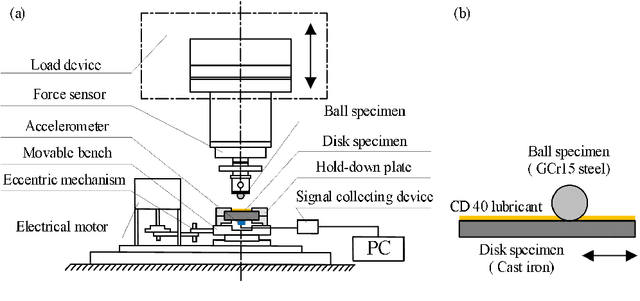
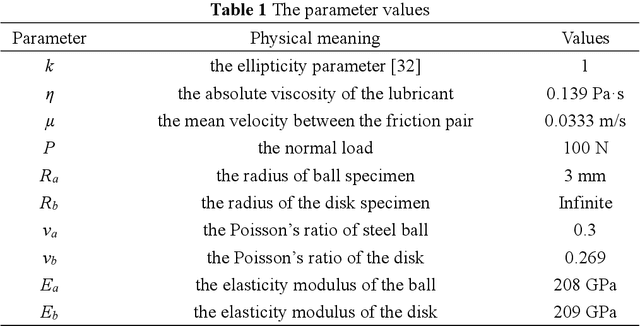
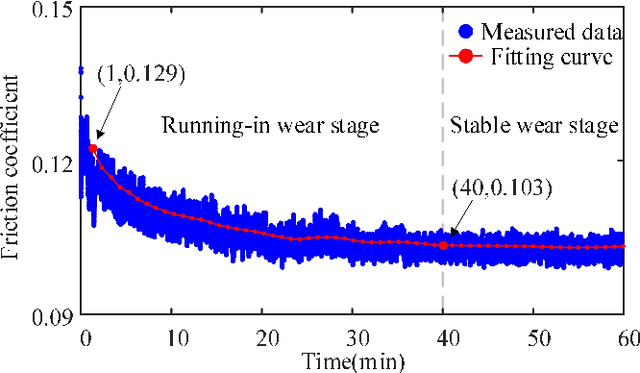
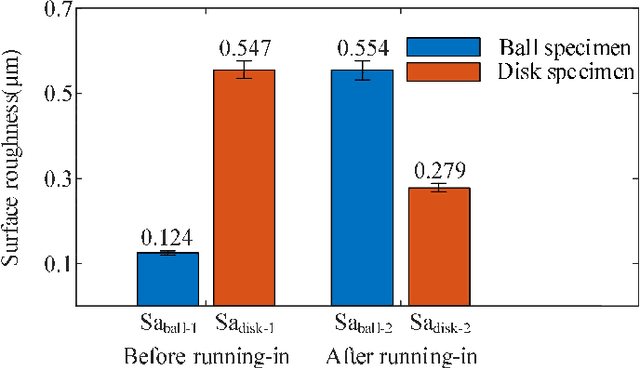
This paper investigated the friction-induced vibration (FIV) behavior under the running-in process with oil lubrication. The FIV signal with periodic characteristics under lubrication was identified with the help of the squeal signal induced in an oil-free wear experiment and then extracted by the harmonic wavelet packet transform (HWPT). The variation of the FIV signal from running-in wear stage to steady wear stage was studied by its root mean square (RMS) values. The result indicates that the time-frequency characteristics of the FIV signals evolve with the wear process and can reflect the wear stages of the friction pairs. The RMS evolvement of the FIV signal is in the same trend to the composite surface roughness and demonstrates that the friction pair goes through the running-in wear stage and the steady wear stage. Therefore, the FIV signal with periodic characteristics can describe the evolvement of the running-in process and distinguish the running-in wear stage and the stable wear stage of the friction pair.