 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformative Risk Control: Calibrating Models for Reliable Deployment under Performativity
May 30, 2025Calibrating blackbox machine learning models to achieve risk control is crucial to ensure reliable decision-making. A rich line of literature has been studying how to calibrate a model so that its predictions satisfy explicit finite-sample statistical guarantees under a fixed, static, and unknown data-generating distribution. However, prediction-supported decisions may influence the outcome they aim to predict, a phenomenon named performativity of predictions, which is commonly seen in social science and economics. In this paper, we introduce Performative Risk Control, a framework to calibrate models to achieve risk control under performativity with provable theoretical guarantees. Specifically, we provide an iteratively refined calibration process, where we ensure the predictions are improved and risk-controlled throughout the process. We also study different types of risk measures and choices of tail bounds. Lastly, we demonstrate the effectiveness of our framework by numerical experiments on the task of predicting credit default risk. To the best of our knowledge, this work is the first one to study statistically rigorous risk control under performativity, which will serve as an important safeguard against a wide range of strategic manipulation in decision-making processes.
Neural Architecture Search for Intel Movidius VPU
May 05, 2023


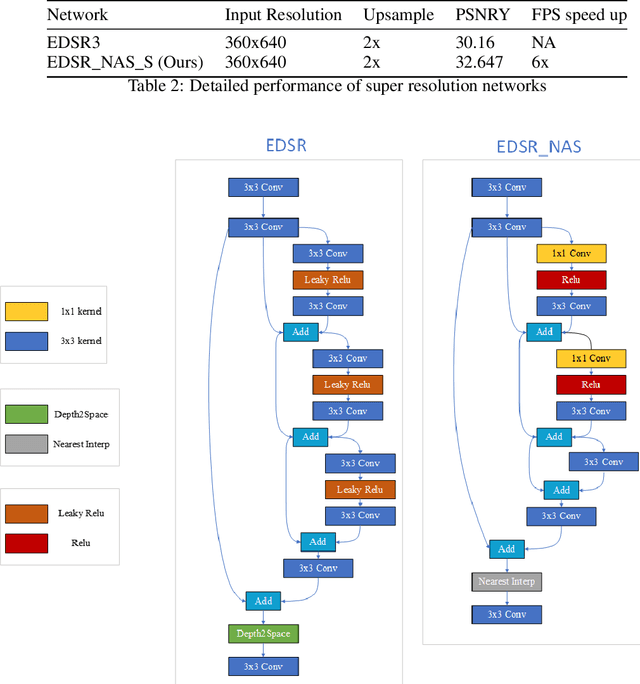
Hardware-aware Neural Architecture Search (NAS) technologies have been proposed to automate and speed up model design to meet both quality and inference efficiency requirements on a given hardware. Prior arts have shown the capability of NAS on hardware specific network design. In this whitepaper, we further extend the use of NAS to Intel Movidius VPU (Vision Processor Units). To determine the hardware-cost to be incorporated into the NAS process, we introduced two methods: pre-collected hardware-cost on device and device-specific hardware-cost model VPUNN. With the help of NAS, for classification task on VPU, we can achieve 1.3x fps acceleration over Mobilenet-v2-1.4 and 2.2x acceleration over Resnet50 with the same accuracy score. For super resolution task on VPU, we can achieve 1.08x PSNR and 6x higher fps compared with EDSR3.
Channel-wise Hessian Aware trace-Weighted Quantization of Neural Networks
Aug 19, 2020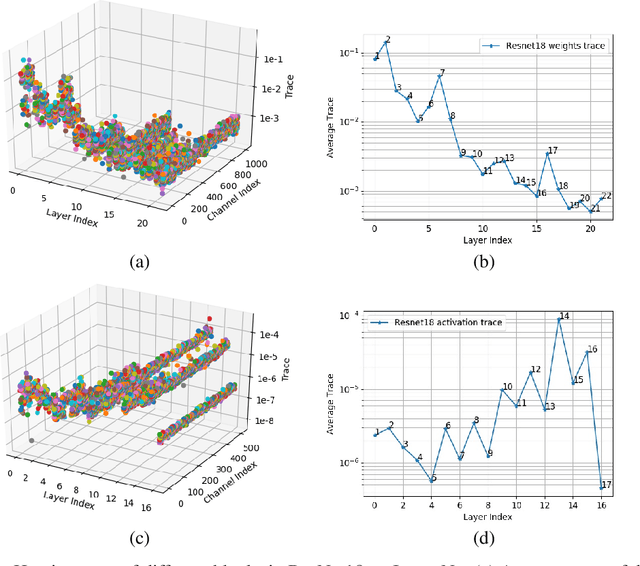
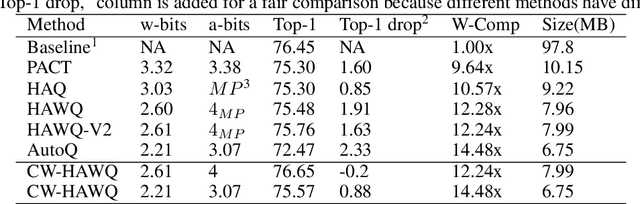
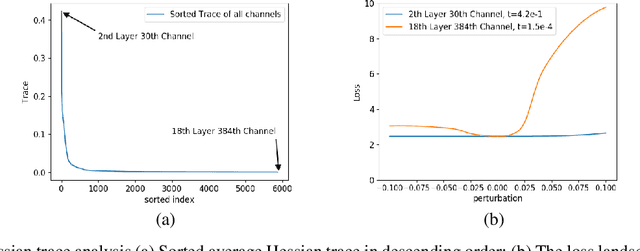
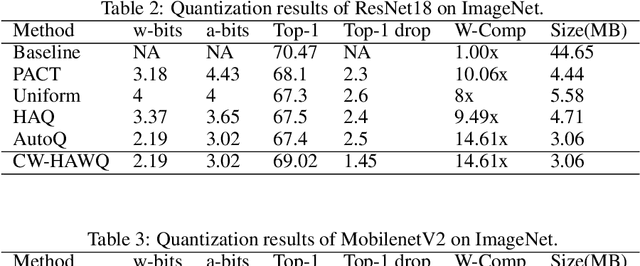
Second-order information has proven to be very effective in determining the redundancy of neural network weights and activations. Recent paper proposes to use Hessian traces of weights and activations for mixed-precision quantization and achieves state-of-the-art results. However, prior works only focus on selecting bits for each layer while the redundancy of different channels within a layer also differ a lot. This is mainly because the complexity of determining bits for each channel is too high for original methods. Here, we introduce Channel-wise Hessian Aware trace-Weighted Quantization (CW-HAWQ). CW-HAWQ uses Hessian trace to determine the relative sensitivity order of different channels of activations and weights. What's more, CW-HAWQ proposes to use deep Reinforcement learning (DRL) Deep Deterministic Policy Gradient (DDPG)-based agent to find the optimal ratios of different quantization bits and assign bits to channels according to the Hessian trace order. The number of states in CW-HAWQ is much smaller compared with traditional AutoML based mix-precision methods since we only need to search ratios for the quantization bits. Compare CW-HAWQ with state-of-the-art shows that we can achieve better results for multiple networks.