 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigPAPR: Rig-Based Animation of Static Neural Point Clouds from a Fixed-Viewpoint Video
Jun 04, 2026Static neural point reconstructions capture a subject at high fidelity from posed images. Given such a reconstruction, we aim to animate it to follow a monocular fixed-viewpoint driving video of the subject, whether captured or produced by image-to-video (I2V) generation, and to recover a rigged, re-posable 3D asset. Existing methods deform Gaussian splats through direct linear blend skinning (LBS) or mesh proxies, both of which are prone to joint-boundary artifacts under articulation, even with per-primitive corrections. We trace the artifact to the representation: each splat carries an individual shape calibrated in the canonical pose to tile with its neighbours. Under rigid LBS, each splat moves with its bone but cannot bend, so the canonical tiling breaks at joint boundaries into gaps and spikes. Proximity attention point rendering (PAPR) instead carries no per-primitive shape; each pixel is recomposed at render time from the deformed primitives' positions, so the surface re-forms naturally with the articulation. We present RigPAPR, which auto-rigs a static PAPR cloud and drives it under direct LBS from a single fixed-viewpoint video, without mesh proxy, pose-dependent correction, or category template. On synthetic subjects, RigPAPR matches the strongest baseline at the supervised view and exceeds mesh-based and Gaussian-splatting baselines at novel views by 3+dB PSNR, with cleaner joint-boundary renderings of both synthetic and real subjects.
Latent Dynamics for Full Body Avatar Animation
May 20, 2026Pose-driven full-body avatars built on neural rendering produce high-quality novel views of a captured subject. Yet loose clothing and other dynamic elements deform in ways pose alone cannot explain: the same pose can correspond to many different states, because their motion depends on history, inertia, and contact. Explicit simulation and layered-garment methods can model such dynamics, but they require either a dedicated garment template, which raw multi-view capture does not naturally provide, or a test-time physics simulator with non-trivial runtime cost. A parallel line of work learns data-driven clothing avatars that avoid explicit garment layers. These methods add an auxiliary latent for variation beyond pose; at inference, they fix it, regress it from pose, or retrieve it from training data, without explicitly modeling how the latent evolves with its own dynamics. Additionally, even in everyday motion with loose clothing, existing architectures often struggle to capture fine-grained detail, producing blurry renderings and temporal artifacts. We augment a pose-conditioned 3D Gaussian avatar with a transformer-based decoder and a dynamics residual latent that captures temporal appearance and geometry variation beyond the driving signals. At inference, a learned latent dynamics model evolves the residual latent from a short pose history and the previous latent state. The model decomposes each update into driving, restoring, and dissipative forces, producing temporally coherent, history-dependent rollouts with negligible added cost. Different initial conditions yield diverse yet plausible motion trajectories, and the force decomposition exposes controls such as stiffness. Across nine captured sequences of everyday motion with diverse loose garments, quantitative metrics and a perceptual user study show improved animation quality over recent data-driven baselines.
Rejection Sampling IMLE: Designing Priors for Better Few-Shot Image Synthesis
Sep 26, 2024An emerging area of research aims to learn deep generative models with limited training data. Prior generative models like GANs and diffusion models require a lot of data to perform well, and their performance degrades when they are trained on only a small amount of data. A recent technique called Implicit Maximum Likelihood Estimation (IMLE) has been adapted to the few-shot setting, achieving state-of-the-art performance. However, current IMLE-based approaches encounter challenges due to inadequate correspondence between the latent codes selected for training and those drawn during inference. This results in suboptimal test-time performance. We theoretically show a way to address this issue and propose RS-IMLE, a novel approach that changes the prior distribution used for training. This leads to substantially higher quality image generation compared to existing GAN and IMLE-based methods, as validated by comprehensive experiments conducted on nine few-shot image datasets.
Intrinsic PAPR for Point-level 3D Scene Albedo and Shading Editing
Jun 29, 2024



Recent advancements in neural rendering have excelled at novel view synthesis from multi-view RGB images. However, they often lack the capability to edit the shading or colour of the scene at a detailed point-level, while ensuring consistency across different viewpoints. In this work, we address the challenge of point-level 3D scene albedo and shading editing from multi-view RGB images, focusing on detailed editing at the point-level rather than at a part or global level. While prior works based on volumetric representation such as NeRF struggle with achieving 3D consistent editing at the point level, recent advancements in point-based neural rendering show promise in overcoming this challenge. We introduce ``Intrinsic PAPR'', a novel method based on the recent point-based neural rendering technique Proximity Attention Point Rendering (PAPR). Unlike other point-based methods that model the intrinsic decomposition of the scene, our approach does not rely on complicated shading models or simplistic priors that may not universally apply. Instead, we directly model scene decomposition into albedo and shading components, leading to better estimation accuracy. Comparative evaluations against the latest point-based inverse rendering methods demonstrate that Intrinsic PAPR achieves higher-quality novel view rendering and superior point-level albedo and shading editing.
PAPR in Motion: Seamless Point-level 3D Scene Interpolation
Jun 08, 2024We propose the problem of point-level 3D scene interpolation, which aims to simultaneously reconstruct a 3D scene in two states from multiple views, synthesize smooth point-level interpolations between them, and render the scene from novel viewpoints, all without any supervision between the states. The primary challenge is on achieving a smooth transition between states that may involve significant and non-rigid changes. To address these challenges, we introduce "PAPR in Motion", a novel approach that builds upon the recent Proximity Attention Point Rendering (PAPR) technique, which can deform a point cloud to match a significantly different shape and render a visually coherent scene even after non-rigid deformations. Our approach is specifically designed to maintain the temporal consistency of the geometric structure by introducing various regularization techniques for PAPR. The result is a method that can effectively bridge large scene changes and produce visually coherent and temporally smooth interpolations in both geometry and appearance. Evaluation across diverse motion types demonstrates that "PAPR in Motion" outperforms the leading neural renderer for dynamic scenes. For more results and code, please visit our project website at https://niopeng.github.io/PAPR-in-Motion/ .
How Good Are Deep Generative Models for Solving Inverse Problems?
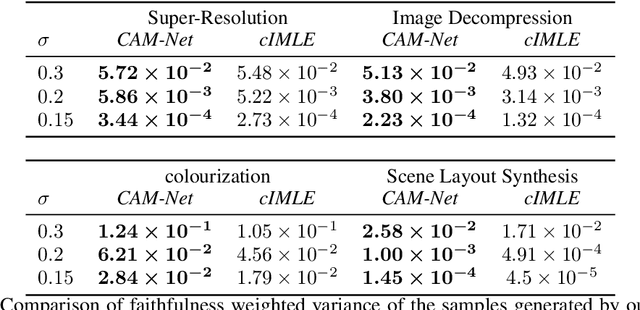
Dec 20, 2023Deep generative models, such as diffusion models, GANs, and IMLE, have shown impressive capability in tackling inverse problems. However, the validity of model-generated solutions w.r.t. the forward problem and the reliability of associated uncertainty estimates remain understudied. This study evaluates recent diffusion-based, GAN-based, and IMLE-based methods on three inverse problems, i.e., $16\times$ super-resolution, colourization, and image decompression. We assess the validity of these models' outputs as solutions to the inverse problems and conduct a thorough analysis of the reliability of the models' estimates of uncertainty over the solution. Overall, we find that the IMLE-based CHIMLE method outperforms other methods in terms of producing valid solutions and reliable uncertainty estimates.
PAPR: Proximity Attention Point Rendering
Jul 20, 2023Learning accurate and parsimonious point cloud representations of scene surfaces from scratch remains a challenge in 3D representation learning. Existing point-based methods often suffer from the vanishing gradient problem or require a large number of points to accurately model scene geometry and texture. To address these limitations, we propose Proximity Attention Point Rendering (PAPR), a novel method that consists of a point-based scene representation and a differentiable renderer. Our scene representation uses a point cloud where each point is characterized by its spatial position, foreground score, and view-independent feature vector. The renderer selects the relevant points for each ray and produces accurate colours using their associated features. PAPR effectively learns point cloud positions to represent the correct scene geometry, even when the initialization drastically differs from the target geometry. Notably, our method captures fine texture details while using only a parsimonious set of points. We also demonstrate four practical applications of our method: geometry editing, object manipulation, texture transfer, and exposure control. More results and code are available on our project website at https://zvict.github.io/papr/.
CHIMLE: Conditional Hierarchical IMLE for Multimodal Conditional Image Synthesis
Nov 25, 2022A persistent challenge in conditional image synthesis has been to generate diverse output images from the same input image despite only one output image being observed per input image. GAN-based methods are prone to mode collapse, which leads to low diversity. To get around this, we leverage Implicit Maximum Likelihood Estimation (IMLE) which can overcome mode collapse fundamentally. IMLE uses the same generator as GANs but trains it with a different, non-adversarial objective which ensures each observed image has a generated sample nearby. Unfortunately, to generate high-fidelity images, prior IMLE-based methods require a large number of samples, which is expensive. In this paper, we propose a new method to get around this limitation, which we dub Conditional Hierarchical IMLE (CHIMLE), which can generate high-fidelity images without requiring many samples. We show CHIMLE significantly outperforms the prior best IMLE, GAN and diffusion-based methods in terms of image fidelity and mode coverage across four tasks, namely night-to-day, 16x single image super-resolution, image colourization and image decompression. Quantitatively, our method improves Fr\'echet Inception Distance (FID) by 36.9% on average compared to the prior best IMLE-based method, and by 27.5% on average compared to the best non-IMLE-based general-purpose methods.
Multimodal Shape Completion via IMLE
Jul 07, 2021

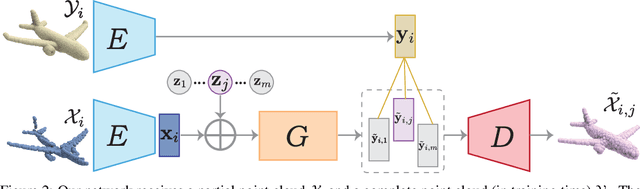

Shape completion is the problem of completing partial input shapes such as partial scans. This problem finds important applications in computer vision and robotics due to issues such as occlusion or sparsity in real-world data. However, most of the existing research related to shape completion has been focused on completing shapes by learning a one-to-one mapping which limits the diversity and creativity of the produced results. We propose a novel multimodal shape completion technique that is effectively able to learn a one-to-many mapping and generates diverse complete shapes. Our approach is based on the conditional Implicit MaximumLikelihood Estimation (IMLE) technique wherein we condition our inputs on partial 3D point clouds. We extensively evaluate our approach by comparing it to various baselines both quantitatively and qualitatively. We show that our method is superior to alternatives in terms of completeness and diversity of shapes.
Cascading Modular Network (CAM-Net) for Multimodal Image Synthesis
Jun 16, 2021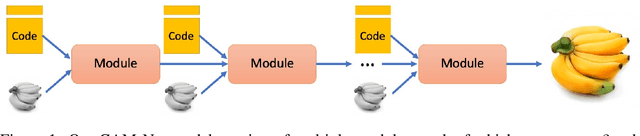
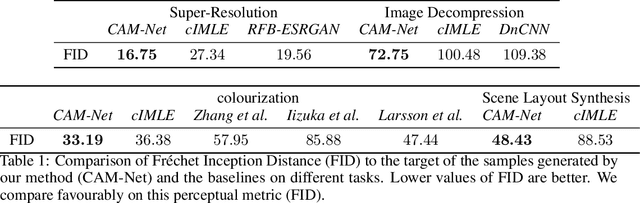
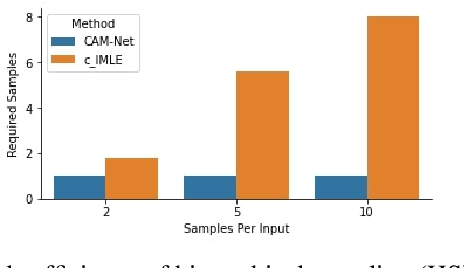
Deep generative models such as GANs have driven impressive advances in conditional image synthesis in recent years. A persistent challenge has been to generate diverse versions of output images from the same input image, due to the problem of mode collapse: because only one ground truth output image is given per input image, only one mode of the conditional distribution is modelled. In this paper, we focus on this problem of multimodal conditional image synthesis and build on the recently proposed technique of Implicit Maximum Likelihood Estimation (IMLE). Prior IMLE-based methods required different architectures for different tasks, which limit their applicability, and were lacking in fine details in the generated images. We propose CAM-Net, a unified architecture that can be applied to a broad range of tasks. Additionally, it is capable of generating convincing high frequency details, achieving a reduction of the Frechet Inception Distance (FID) by up to 45.3% compared to the baseline.