 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascading Modular Network (CAM-Net) for Multimodal Image Synthesis
Paper and Code
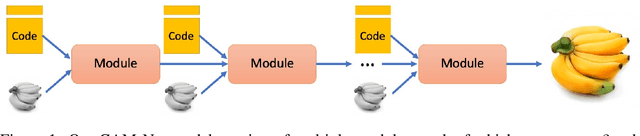
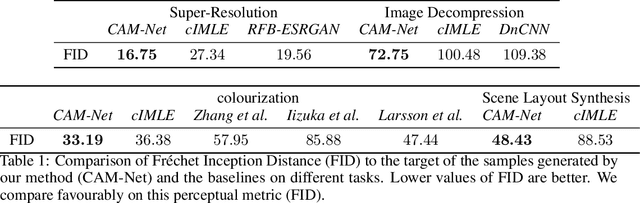
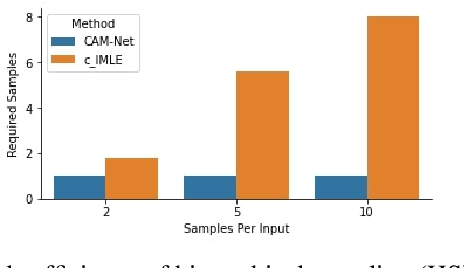
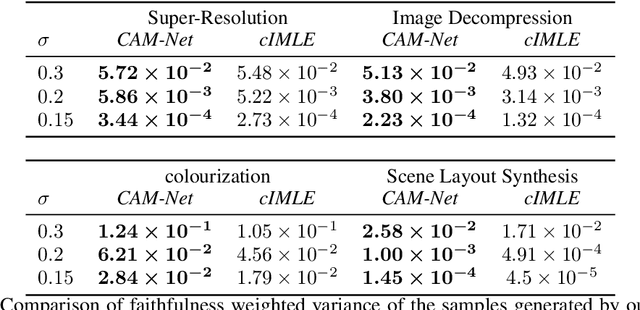
Deep generative models such as GANs have driven impressive advances in conditional image synthesis in recent years. A persistent challenge has been to generate diverse versions of output images from the same input image, due to the problem of mode collapse: because only one ground truth output image is given per input image, only one mode of the conditional distribution is modelled. In this paper, we focus on this problem of multimodal conditional image synthesis and build on the recently proposed technique of Implicit Maximum Likelihood Estimation (IMLE). Prior IMLE-based methods required different architectures for different tasks, which limit their applicability, and were lacking in fine details in the generated images. We propose CAM-Net, a unified architecture that can be applied to a broad range of tasks. Additionally, it is capable of generating convincing high frequency details, achieving a reduction of the Frechet Inception Distance (FID) by up to 45.3% compared to the baseline.