 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIMLE: Uncertainty-Aware World Models with IMLE for Sample-Efficient Continuous Control
Feb 15, 2026Model-based reinforcement learning promises strong sample efficiency but often underperforms in practice due to compounding model error, unimodal world models that average over multi-modal dynamics, and overconfident predictions that bias learning. We introduce WIMLE, a model-based method that extends Implicit Maximum Likelihood Estimation (IMLE) to the model-based RL framework to learn stochastic, multi-modal world models without iterative sampling and to estimate predictive uncertainty via ensembles and latent sampling. During training, WIMLE weights each synthetic transition by its predicted confidence, preserving useful model rollouts while attenuating bias from uncertain predictions and enabling stable learning. Across $40$ continuous-control tasks spanning DeepMind Control, MyoSuite, and HumanoidBench, WIMLE achieves superior sample efficiency and competitive or better asymptotic performance than strong model-free and model-based baselines. Notably, on the challenging Humanoid-run task, WIMLE improves sample efficiency by over $50$\% relative to the strongest competitor, and on HumanoidBench it solves $8$ of $14$ tasks (versus $4$ for BRO and $5$ for SimbaV2). These results highlight the value of IMLE-based multi-modality and uncertainty-aware weighting for stable model-based RL.
* Accepted at ICLR 2026. OpenReview: https://openreview.net/forum?id=mzLOnTb3WH
Intrinsic PAPR for Point-level 3D Scene Albedo and Shading Editing
Jun 29, 2024



Recent advancements in neural rendering have excelled at novel view synthesis from multi-view RGB images. However, they often lack the capability to edit the shading or colour of the scene at a detailed point-level, while ensuring consistency across different viewpoints. In this work, we address the challenge of point-level 3D scene albedo and shading editing from multi-view RGB images, focusing on detailed editing at the point-level rather than at a part or global level. While prior works based on volumetric representation such as NeRF struggle with achieving 3D consistent editing at the point level, recent advancements in point-based neural rendering show promise in overcoming this challenge. We introduce ``Intrinsic PAPR'', a novel method based on the recent point-based neural rendering technique Proximity Attention Point Rendering (PAPR). Unlike other point-based methods that model the intrinsic decomposition of the scene, our approach does not rely on complicated shading models or simplistic priors that may not universally apply. Instead, we directly model scene decomposition into albedo and shading components, leading to better estimation accuracy. Comparative evaluations against the latest point-based inverse rendering methods demonstrate that Intrinsic PAPR achieves higher-quality novel view rendering and superior point-level albedo and shading editing.
How Good Are Deep Generative Models for Solving Inverse Problems?
Dec 20, 2023Deep generative models, such as diffusion models, GANs, and IMLE, have shown impressive capability in tackling inverse problems. However, the validity of model-generated solutions w.r.t. the forward problem and the reliability of associated uncertainty estimates remain understudied. This study evaluates recent diffusion-based, GAN-based, and IMLE-based methods on three inverse problems, i.e., $16\times$ super-resolution, colourization, and image decompression. We assess the validity of these models' outputs as solutions to the inverse problems and conduct a thorough analysis of the reliability of the models' estimates of uncertainty over the solution. Overall, we find that the IMLE-based CHIMLE method outperforms other methods in terms of producing valid solutions and reliable uncertainty estimates.
PAPR: Proximity Attention Point Rendering
Jul 20, 2023Learning accurate and parsimonious point cloud representations of scene surfaces from scratch remains a challenge in 3D representation learning. Existing point-based methods often suffer from the vanishing gradient problem or require a large number of points to accurately model scene geometry and texture. To address these limitations, we propose Proximity Attention Point Rendering (PAPR), a novel method that consists of a point-based scene representation and a differentiable renderer. Our scene representation uses a point cloud where each point is characterized by its spatial position, foreground score, and view-independent feature vector. The renderer selects the relevant points for each ray and produces accurate colours using their associated features. PAPR effectively learns point cloud positions to represent the correct scene geometry, even when the initialization drastically differs from the target geometry. Notably, our method captures fine texture details while using only a parsimonious set of points. We also demonstrate four practical applications of our method: geometry editing, object manipulation, texture transfer, and exposure control. More results and code are available on our project website at https://zvict.github.io/papr/.
CHIMLE: Conditional Hierarchical IMLE for Multimodal Conditional Image Synthesis
Nov 25, 2022A persistent challenge in conditional image synthesis has been to generate diverse output images from the same input image despite only one output image being observed per input image. GAN-based methods are prone to mode collapse, which leads to low diversity. To get around this, we leverage Implicit Maximum Likelihood Estimation (IMLE) which can overcome mode collapse fundamentally. IMLE uses the same generator as GANs but trains it with a different, non-adversarial objective which ensures each observed image has a generated sample nearby. Unfortunately, to generate high-fidelity images, prior IMLE-based methods require a large number of samples, which is expensive. In this paper, we propose a new method to get around this limitation, which we dub Conditional Hierarchical IMLE (CHIMLE), which can generate high-fidelity images without requiring many samples. We show CHIMLE significantly outperforms the prior best IMLE, GAN and diffusion-based methods in terms of image fidelity and mode coverage across four tasks, namely night-to-day, 16x single image super-resolution, image colourization and image decompression. Quantitatively, our method improves Fr\'echet Inception Distance (FID) by 36.9% on average compared to the prior best IMLE-based method, and by 27.5% on average compared to the best non-IMLE-based general-purpose methods.
Cascading Modular Network (CAM-Net) for Multimodal Image Synthesis
Jun 16, 2021
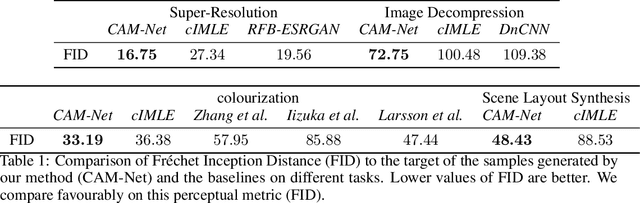
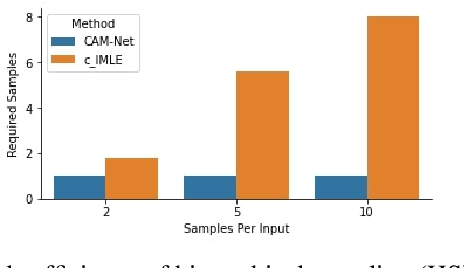
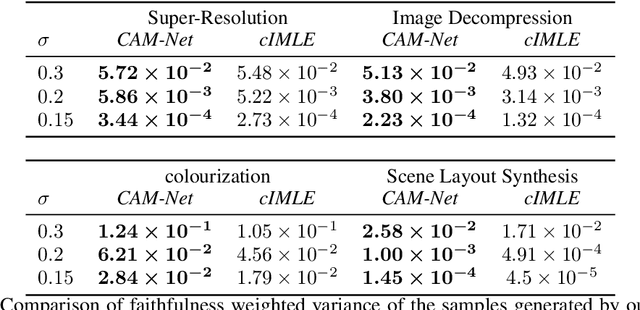
Deep generative models such as GANs have driven impressive advances in conditional image synthesis in recent years. A persistent challenge has been to generate diverse versions of output images from the same input image, due to the problem of mode collapse: because only one ground truth output image is given per input image, only one mode of the conditional distribution is modelled. In this paper, we focus on this problem of multimodal conditional image synthesis and build on the recently proposed technique of Implicit Maximum Likelihood Estimation (IMLE). Prior IMLE-based methods required different architectures for different tasks, which limit their applicability, and were lacking in fine details in the generated images. We propose CAM-Net, a unified architecture that can be applied to a broad range of tasks. Additionally, it is capable of generating convincing high frequency details, achieving a reduction of the Frechet Inception Distance (FID) by up to 45.3% compared to the baseline.