 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenealogical Population-Based Training for Hyperparameter Optimization
Sep 30, 2021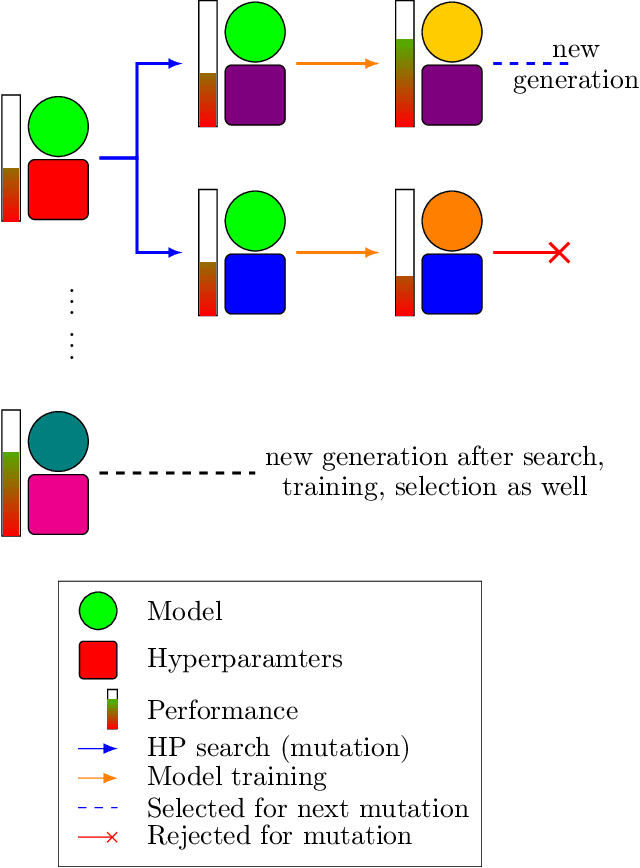
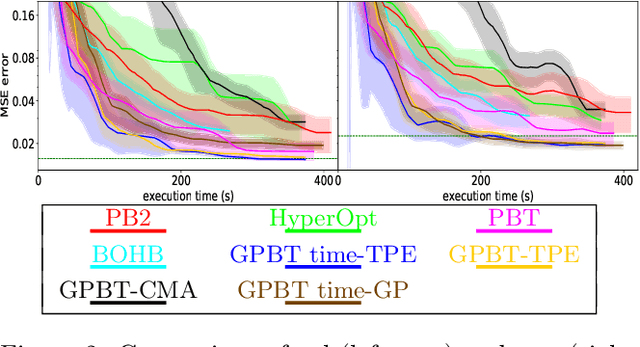
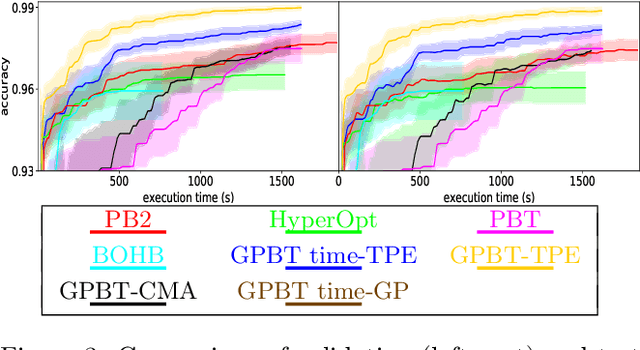
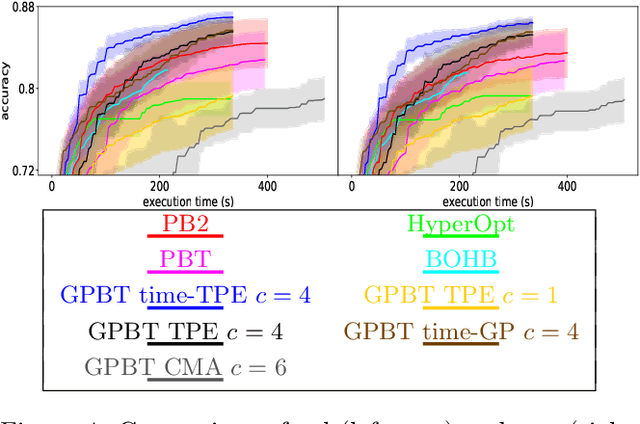
Hyperparameter optimization aims at finding more rapidly and efficiently the best hyperparameters (HPs) of learning models such as neural networks. In this work, we present a new approach called GPBT (Genealogical Population-Based Training), which shares many points with Population-Based Training: our approach outputs a schedule of HPs and updates both weights and HPs in a single run, but brings several novel contributions: the choice of new HPs is made by a modular search algorithm, the search algorithm can search HPs independently for models with different weights and can exploit separately the maximum amount of meaningful information (genealogically-related) from previous HPs evaluations instead of exploiting together all previous HPs evaluations, a variation of early stopping allows a 2-3 fold acceleration at small performance cost. GPBT significantly outperforms all other approaches of HP Optimization, on all supervised learning experiments tested in terms of speed and performances. HPs tuning will become less computationally expensive using our approach, not only in the deep learning field, but potentially for all processes based on iterative optimization.