 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Understanding Distributed GNN Training on GPUs
Apr 18, 2022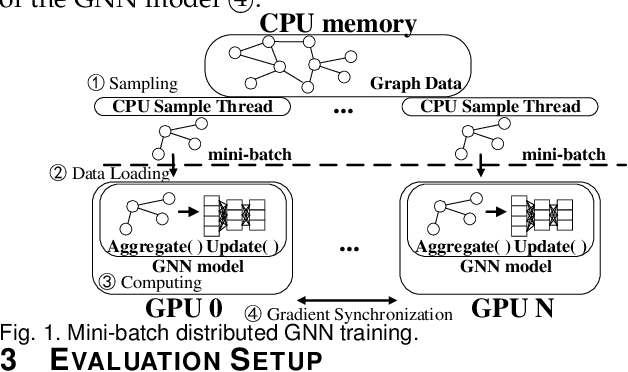
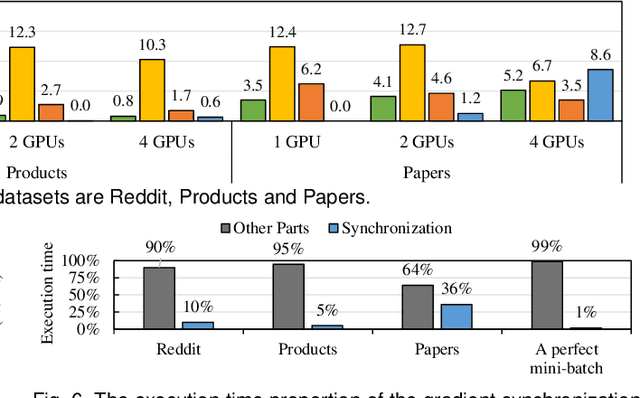
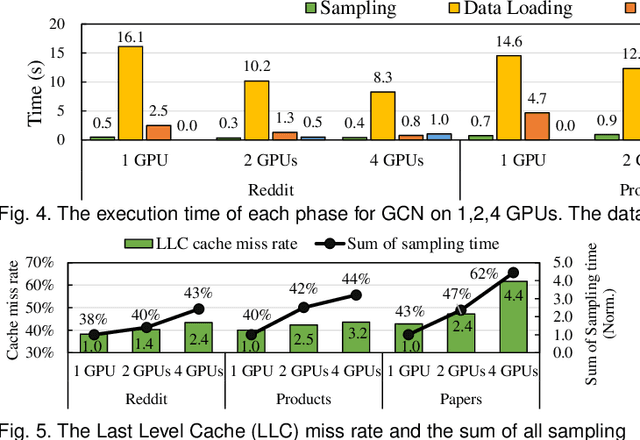
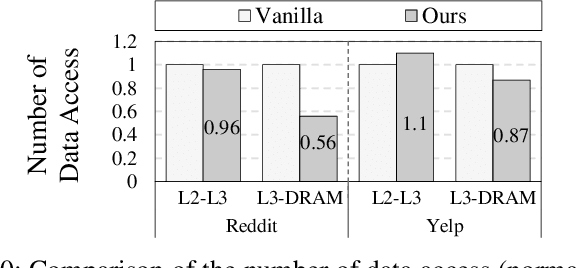
Graph neural network (GNN) has been demonstrated to be a powerful model in many domains for its effectiveness in learning over graphs. To scale GNN training for large graphs, a widely adopted approach is distributed training which accelerates training using multiple computing nodes. Maximizing the performance is essential, but the execution of distributed GNN training remains preliminarily understood. In this work, we provide an in-depth analysis of distributed GNN training on GPUs, revealing several significant observations and providing useful guidelines for both software optimization and hardware optimization.
GNNSampler: Bridging the Gap between Sampling Algorithms of GNN and Hardware
Aug 26, 2021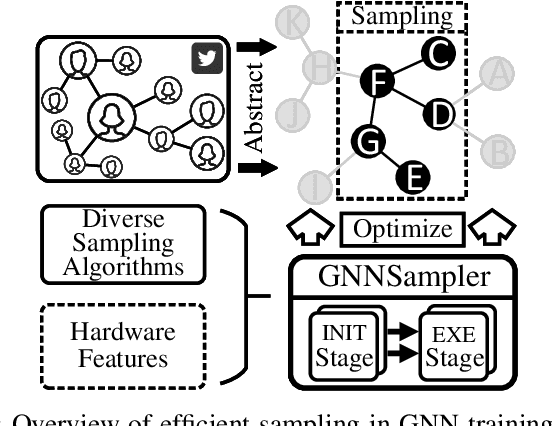
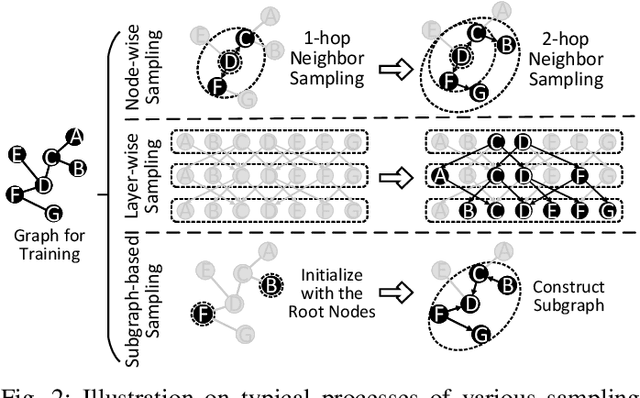

Sampling is a critical operation in the training of Graph Neural Network (GNN) that helps reduce the cost. Previous works have explored improving sampling algorithms through mathematical and statistical methods. However, there is a gap between sampling algorithms and hardware. Without consideration of hardware, algorithm designers merely optimize sampling at the algorithm level, missing the great potential of promoting the efficiency of existing sampling algorithms by leveraging hardware features. In this paper, we first propose a unified programming model for mainstream sampling algorithms, termed GNNSampler, covering the key processes for sampling algorithms in various categories. Second, we explore the data locality among nodes and their neighbors (i.e., the hardware feature) in real-world datasets for alleviating the irregular memory access in sampling. Third, we implement locality-aware optimizations in GNNSampler for diverse sampling algorithms to optimize the general sampling process in the training of GNN. Finally, we emphatically conduct experiments on large graph datasets to analyze the relevance between the training time, model accuracy, and hardware-level metrics, which helps achieve a good trade-off between time and accuracy in GNN training. Extensive experimental results show that our method is universal to mainstream sampling algorithms and reduces the training time of GNN (range from 4.83% with layer-wise sampling to 44.92% with subgraph-based sampling) with comparable accuracy.
Pixel-Semantic Revise of Position Learning A One-Stage Object Detector with A Shared Encoder-Decoder
Jan 04, 2020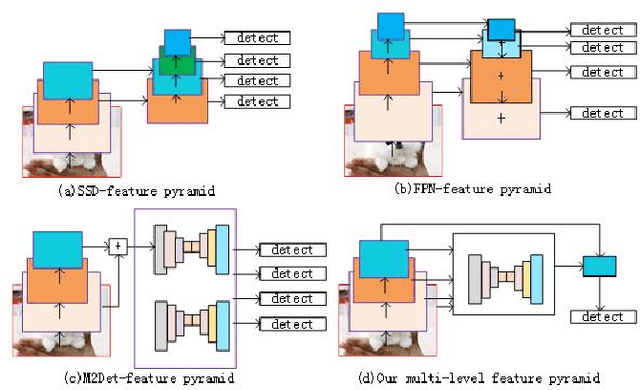
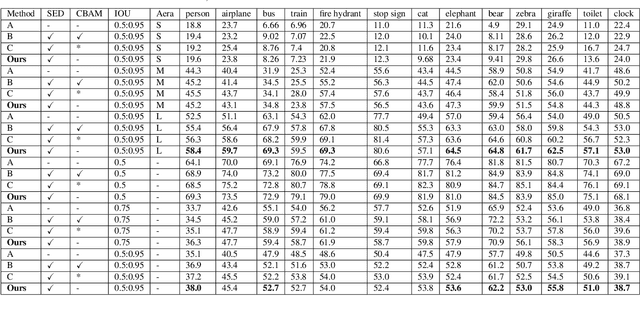
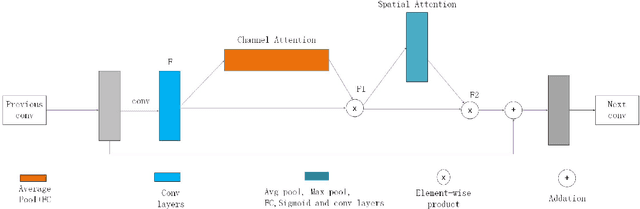

We analyze that different methods based channel or position attention mechanism give rise to different performance on scale, and some of state-of-the-art detectors applying feature pyramid are integrated with various variants convolutions with many mechanisms to enhance information, resulting in increasing runtime. This work addresses the problem by constructing an anchor-free detector with shared module consisting of encoder and decoder with attention mechanism. First, we consider different level features from backbone (e.g., ResNet-50) as the base features. Second, we feed the feature into a simple block, rather than various complex operations.Then, location and classification tasks are obtained by the detector head and classifier, respectively. At the same time, we use the semantic information to revise geometry locations. Additionally, we show that the detector is a pixel-semantic revise of position, universal, effective and simple to detect, especially, large-scale objects. More importantly, this work compares different feature processing (e.g.,mean, maximum or minimum) performance across channel. Finally,we present that our method improves detection accuracy by 3.8 AP compared to state-of-the-art MNC based ResNet-101 on the standard MSCOCO baseline.