 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Distributed Training of Graph Neural Networks
Nov 11, 2022Graph neural networks (GNNs) have been demonstrated to be a powerful algorithmic model in broad application fields for their effectiveness in learning over graphs. To scale GNN training up for large-scale and ever-growing graphs, the most promising solution is distributed training which distributes the workload of training across multiple computing nodes. However, the workflows, computational patterns, communication patterns, and optimization techniques of distributed GNN training remain preliminarily understood. In this paper, we provide a comprehensive survey of distributed GNN training by investigating various optimization techniques used in distributed GNN training. First, distributed GNN training is classified into several categories according to their workflows. In addition, their computational patterns and communication patterns, as well as the optimization techniques proposed by recent work are introduced. Second, the software frameworks and hardware platforms of distributed GNN training are also introduced for a deeper understanding. Third, distributed GNN training is compared with distributed training of deep neural networks, emphasizing the uniqueness of distributed GNN training. Finally, interesting issues and opportunities in this field are discussed.
Characterizing and Understanding Distributed GNN Training on GPUs
Apr 18, 2022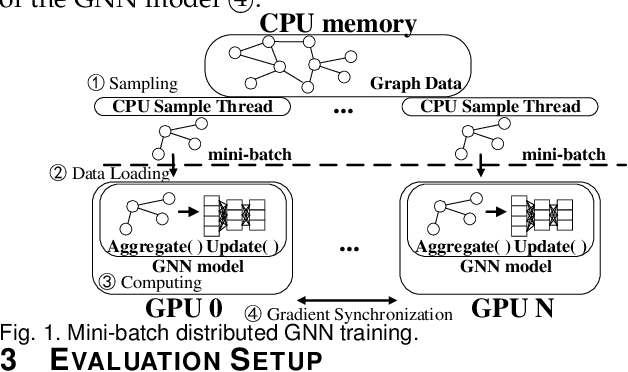
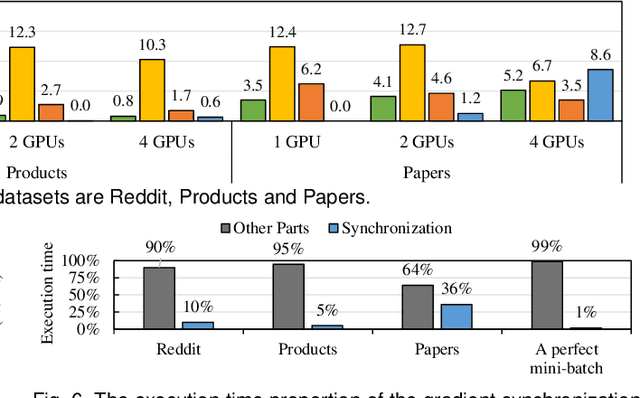
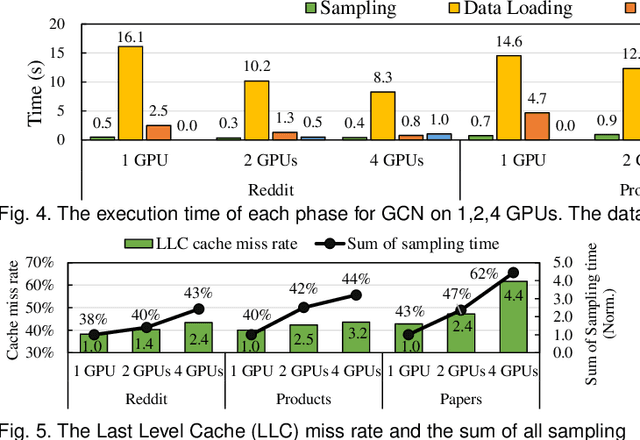
Graph neural network (GNN) has been demonstrated to be a powerful model in many domains for its effectiveness in learning over graphs. To scale GNN training for large graphs, a widely adopted approach is distributed training which accelerates training using multiple computing nodes. Maximizing the performance is essential, but the execution of distributed GNN training remains preliminarily understood. In this work, we provide an in-depth analysis of distributed GNN training on GPUs, revealing several significant observations and providing useful guidelines for both software optimization and hardware optimization.