 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNNSampler: Bridging the Gap between Sampling Algorithms of GNN and Hardware
Paper and Code
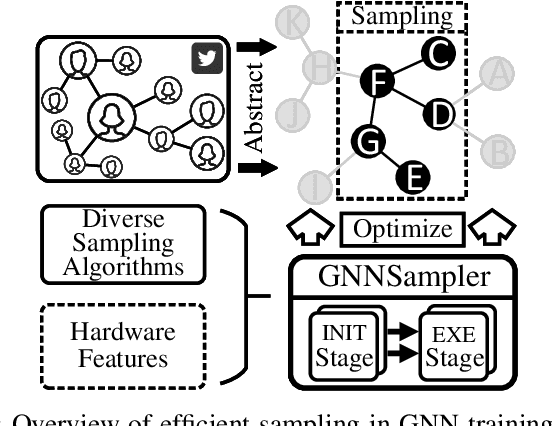
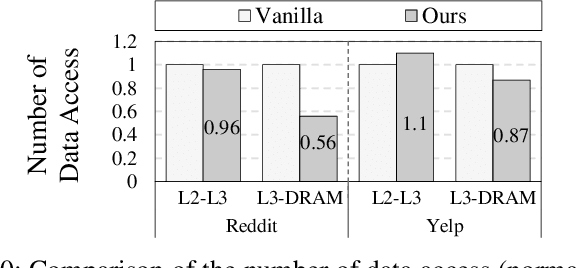
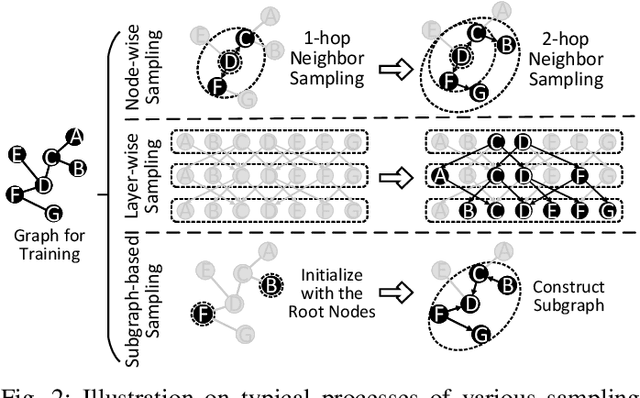

Sampling is a critical operation in the training of Graph Neural Network (GNN) that helps reduce the cost. Previous works have explored improving sampling algorithms through mathematical and statistical methods. However, there is a gap between sampling algorithms and hardware. Without consideration of hardware, algorithm designers merely optimize sampling at the algorithm level, missing the great potential of promoting the efficiency of existing sampling algorithms by leveraging hardware features. In this paper, we first propose a unified programming model for mainstream sampling algorithms, termed GNNSampler, covering the key processes for sampling algorithms in various categories. Second, we explore the data locality among nodes and their neighbors (i.e., the hardware feature) in real-world datasets for alleviating the irregular memory access in sampling. Third, we implement locality-aware optimizations in GNNSampler for diverse sampling algorithms to optimize the general sampling process in the training of GNN. Finally, we emphatically conduct experiments on large graph datasets to analyze the relevance between the training time, model accuracy, and hardware-level metrics, which helps achieve a good trade-off between time and accuracy in GNN training. Extensive experimental results show that our method is universal to mainstream sampling algorithms and reduces the training time of GNN (range from 4.83% with layer-wise sampling to 44.92% with subgraph-based sampling) with comparable accuracy.