 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrackSegFlow: Controllable Flow Matching Synthesis for Generalizable Crack Segmentation with a 50K Image-Mask Benchmark
Jan 08, 2026Automated crack segmentation is essential for condition assessment, yet deployment is limited by scarce pixel-level labels and domain shift. We present CrackSegFlow, a controllable flow-matching synthesis framework that generates crack images conditioned on binary masks with mask-image alignment. The renderer combines topology-preserving mask injection with edge gating to maintain thin-structure continuity and suppress false positives. A class-conditional flow-matching mask model synthesizes masks with control over crack coverage, enabling balanced, topology-diverse data without manual annotation. We inject masks into crack-free backgrounds to diversify illumination and reduce false positives. On five datasets with a CNN-Transformer backbone, incorporating synthesized pairs improves in-domain performance by 5.37 mIoU and 5.13 F1, and target-guided cross-domain synthesis yields gains of 13.12 mIoU and 14.82 F1 using target mask statistics. We also release CSF-50K, 50,000 image-mask pairs for benchmarking.
RTLRepoCoder: Repository-Level RTL Code Completion through the Combination of Fine-Tuning and Retrieval Augmentation
Apr 11, 2025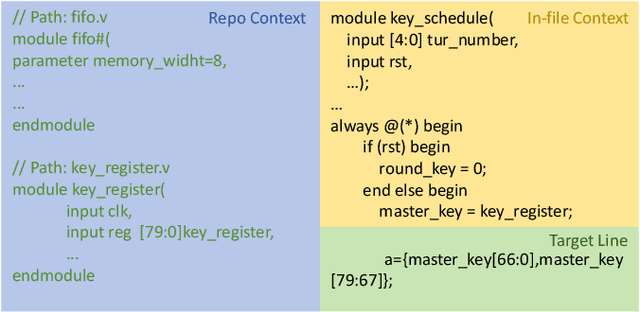
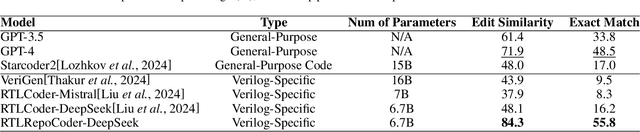
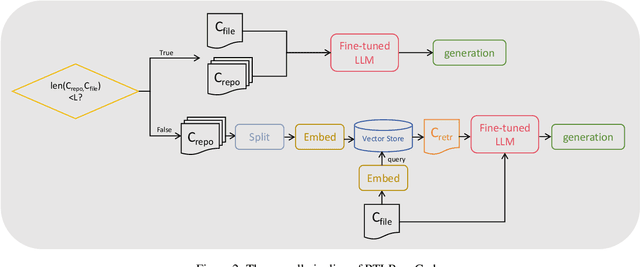

As an essential part of modern hardware design, manually writing Register Transfer Level (RTL) code such as Verilog is often labor-intensive. Following the tremendous success of large language models (LLMs), researchers have begun to explore utilizing LLMs for generating RTL code. However, current studies primarily focus on generating simple single modules, which can not meet the demands in real world. In fact, due to challenges in managing long-context RTL code and complex cross-file dependencies, existing solutions cannot handle large-scale Verilog repositories in practical hardware development. As the first endeavor to exclusively adapt LLMs for large-scale RTL development, we propose RTLRepoCoder, a groundbreaking solution that incorporates specific fine-tuning and Retrieval-Augmented Generation (RAG) for repository-level Verilog code completion. Open-source Verilog repositories from the real world, along with an extended context size, are used for domain-specific fine-tuning. The optimized RAG system improves the information density of the input context by retrieving relevant code snippets. Tailored optimizations for RAG are carried out, including the embedding model, the cross-file context splitting strategy, and the chunk size. Our solution achieves state-of-the-art performance on public benchmark, significantly surpassing GPT-4 and advanced domain-specific LLMs on Edit Similarity and Exact Match rate. Comprehensive experiments demonstrate the remarkable effectiveness of our approach and offer insights for future work.