 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents
Feb 05, 2020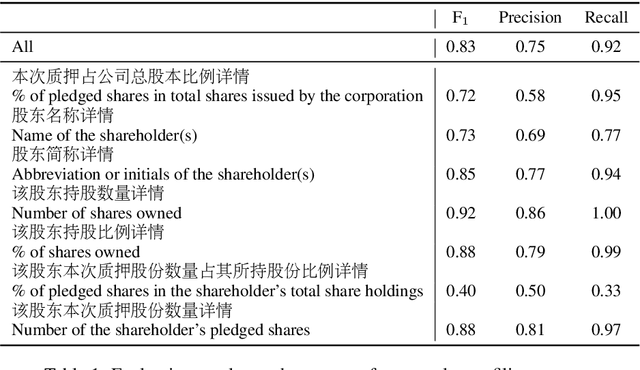
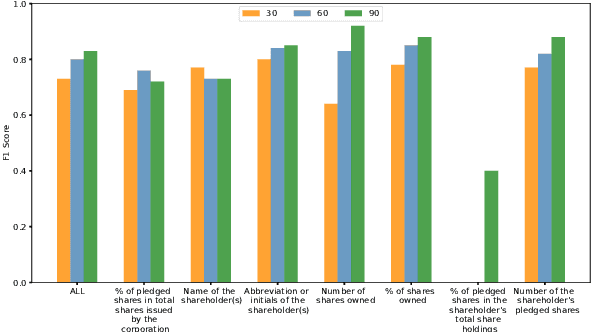
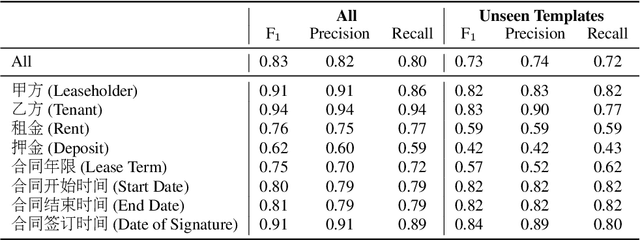
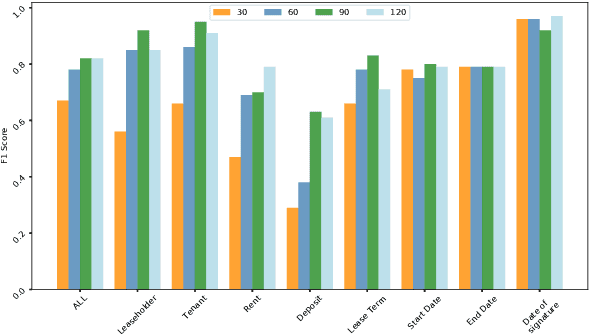
Techniques for automatically extracting important content elements from business documents such as contracts, statements, and filings have the potential to make business operations more efficient. This problem can be formulated as a sequence labeling task, and we demonstrate the adaption of BERT to two types of business documents: regulatory filings and property lease agreements. There are aspects of this problem that make it easier than "standard" information extraction tasks and other aspects that make it more difficult, but on balance we find that modest amounts of annotated data (less than 100 documents) are sufficient to achieve reasonable accuracy. We integrate our models into an end-to-end cloud platform that provides both an easy-to-use annotation interface as well as an inference interface that allows users to upload documents and inspect model outputs.