 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics of the Unwritten
Paper and Code
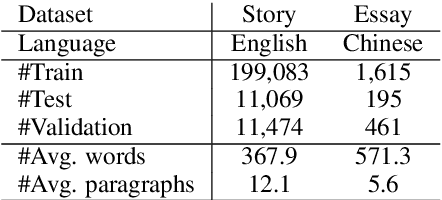
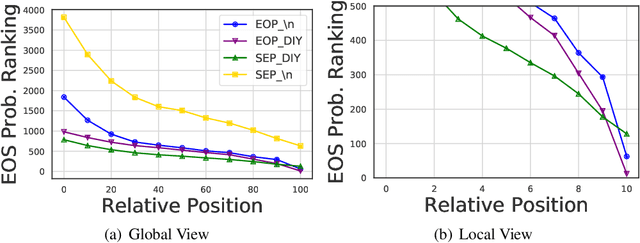
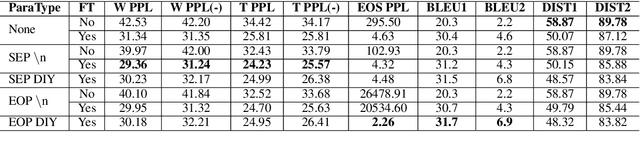

The semantics of a text is manifested not only by what is read, but also by what is not read. In this article, we will study how those implicit "not read" information such as end-of-paragraph (EOP) and end-of-sequence (EOS) affect the quality of text generation. Transformer-based pretrained language models (LMs) have demonstrated the ability to generate long continuations with good quality. This model gives us a platform for the first time to demonstrate that paragraph layouts and text endings are also important components of human writing. Specifically, we find that pretrained LMs can generate better continuations by learning to generate the end of the paragraph (EOP) in the fine-tuning stage. Experimental results on English story generation show that EOP can lead to higher BLEU score and lower EOS perplexity. To further investigate the relationship between text ending and EOP, we conduct experiments with a self-collected Chinese essay dataset on Chinese-GPT2, a character level LM without paragraph breaker or EOS during pre-training. Experimental results show that the Chinese GPT2 can generate better essay endings with paragraph information. Experiments on both English stories and Chinese essays demonstrate that learning to end paragraphs can benefit the continuation generation with pretrained LMs.