 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinGAIA: An End-to-End Benchmark for Evaluating AI Agents in Finance
Jul 23, 2025



The booming development of AI agents presents unprecedented opportunities for automating complex tasks across various domains. However, their multi-step, multi-tool collaboration capabilities in the financial sector remain underexplored. This paper introduces FinGAIA, an end-to-end benchmark designed to evaluate the practical abilities of AI agents in the financial domain. FinGAIA comprises 407 meticulously crafted tasks, spanning seven major financial sub-domains: securities, funds, banking, insurance, futures, trusts, and asset management. These tasks are organized into three hierarchical levels of scenario depth: basic business analysis, asset decision support, and strategic risk management. We evaluated 10 mainstream AI agents in a zero-shot setting. The best-performing agent, ChatGPT, achieved an overall accuracy of 48.9\%, which, while superior to non-professionals, still lags financial experts by over 35 percentage points. Error analysis has revealed five recurring failure patterns: Cross-modal Alignment Deficiency, Financial Terminological Bias, Operational Process Awareness Barrier, among others. These patterns point to crucial directions for future research. Our work provides the first agent benchmark closely related to the financial domain, aiming to objectively assess and promote the development of agents in this crucial field. Partial data is available at https://github.com/SUFE-AIFLM-Lab/FinGAIA.
Towards Better Multi-modal Keyphrase Generation via Visual Entity Enhancement and Multi-granularity Image Noise Filtering
Sep 09, 2023
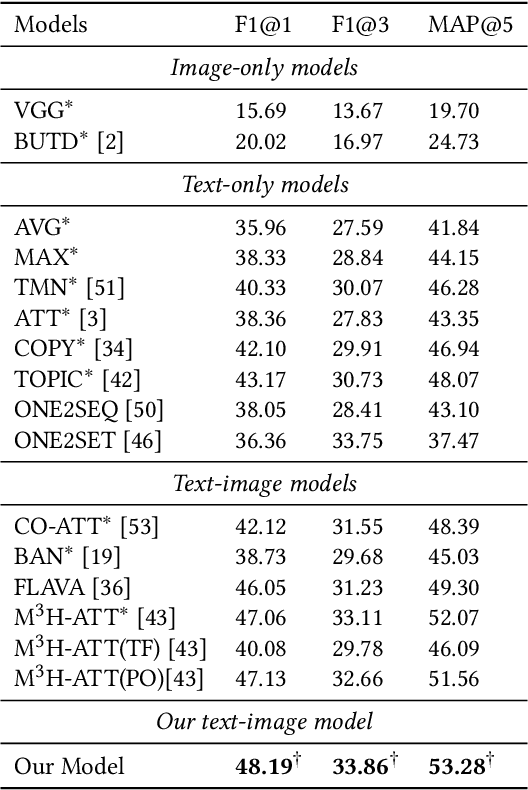
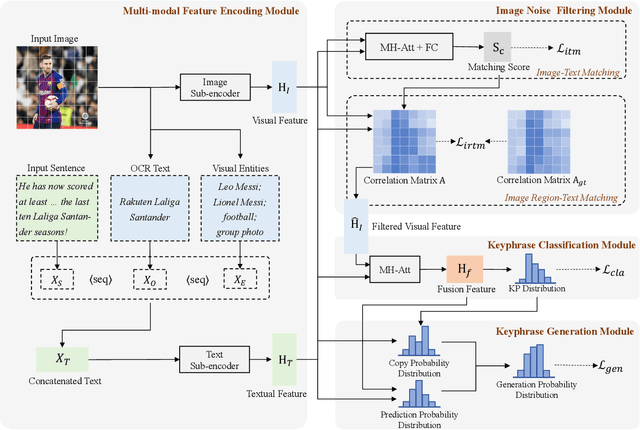
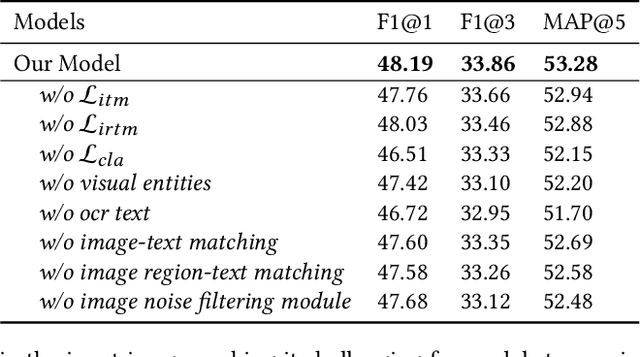
Multi-modal keyphrase generation aims to produce a set of keyphrases that represent the core points of the input text-image pair. In this regard, dominant methods mainly focus on multi-modal fusion for keyphrase generation. Nevertheless, there are still two main drawbacks: 1) only a limited number of sources, such as image captions, can be utilized to provide auxiliary information. However, they may not be sufficient for the subsequent keyphrase generation. 2) the input text and image are often not perfectly matched, and thus the image may introduce noise into the model. To address these limitations, in this paper, we propose a novel multi-modal keyphrase generation model, which not only enriches the model input with external knowledge, but also effectively filters image noise. First, we introduce external visual entities of the image as the supplementary input to the model, which benefits the cross-modal semantic alignment for keyphrase generation. Second, we simultaneously calculate an image-text matching score and image region-text correlation scores to perform multi-granularity image noise filtering. Particularly, we introduce the correlation scores between image regions and ground-truth keyphrases to refine the calculation of the previously-mentioned correlation scores. To demonstrate the effectiveness of our model, we conduct several groups of experiments on the benchmark dataset. Experimental results and in-depth analyses show that our model achieves the state-of-the-art performance. Our code is available on https://github.com/DeepLearnXMU/MM-MKP.