 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024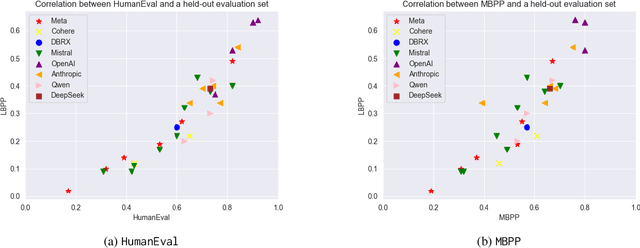
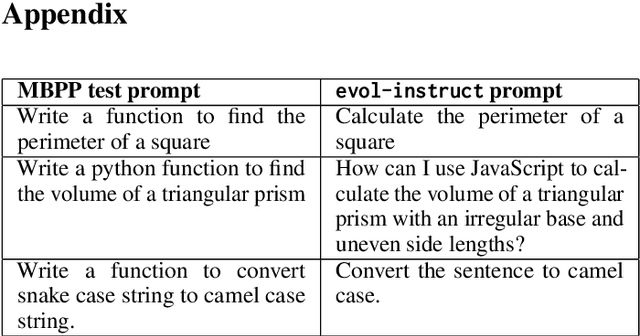
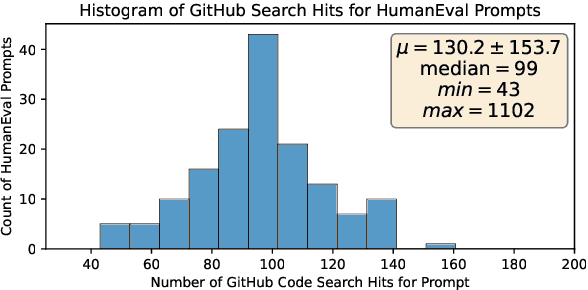
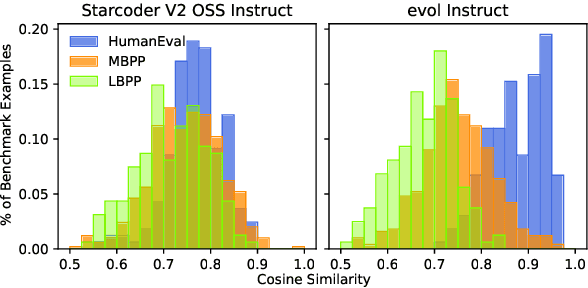
In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
Learning with Rejection for Abstractive Text Summarization
Feb 16, 2023
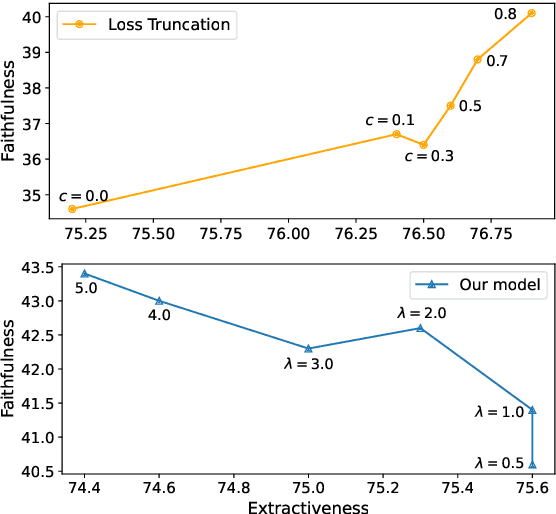


State-of-the-art abstractive summarization systems frequently hallucinate content that is not supported by the source document, mainly due to noise in the training dataset. Existing methods opt to drop the noisy samples or tokens from the training set entirely, reducing the effective training set size and creating an artificial propensity to copy words from the source. In this work, we propose a training objective for abstractive summarization based on rejection learning, in which the model learns whether or not to reject potentially noisy tokens. We further propose a regularized decoding objective that penalizes non-factual candidate summaries during inference by using the rejection probability learned during training. We show that our method considerably improves the factuality of generated summaries in automatic and human evaluations when compared to five baseline models and that it does so while increasing the abstractiveness of the generated summaries.
Learning Efficient Task-Specific Meta-Embeddings with Word Prisms
Nov 05, 2020
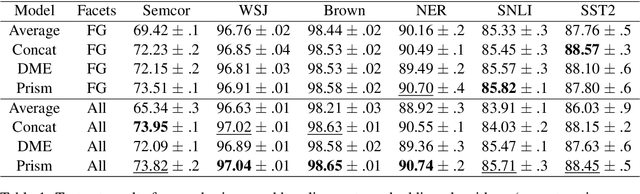

Word embeddings are trained to predict word cooccurrence statistics, which leads them to possess different lexical properties (syntactic, semantic, etc.) depending on the notion of context defined at training time. These properties manifest when querying the embedding space for the most similar vectors, and when used at the input layer of deep neural networks trained to solve downstream NLP problems. Meta-embeddings combine multiple sets of differently trained word embeddings, and have been shown to successfully improve intrinsic and extrinsic performance over equivalent models which use just one set of source embeddings. We introduce word prisms: a simple and efficient meta-embedding method that learns to combine source embeddings according to the task at hand. Word prisms learn orthogonal transformations to linearly combine the input source embeddings, which allows them to be very efficient at inference time. We evaluate word prisms in comparison to other meta-embedding methods on six extrinsic evaluations and observe that word prisms offer improvements in performance on all tasks.
An ensemble learning framework based on group decision making
Jul 01, 2020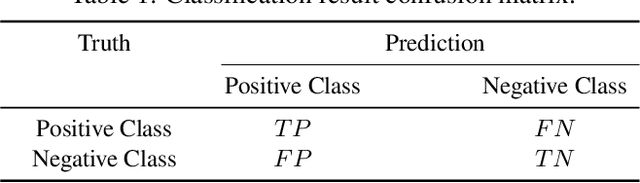
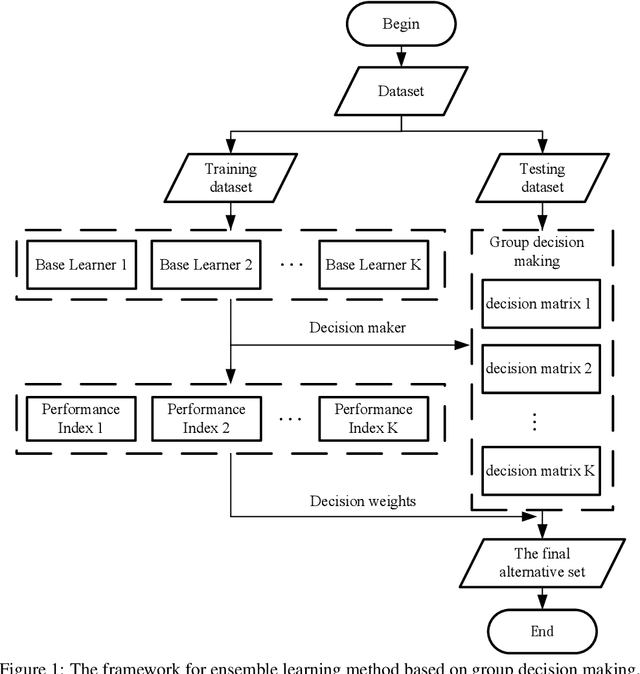
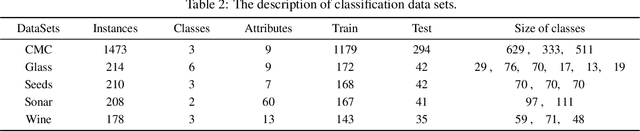
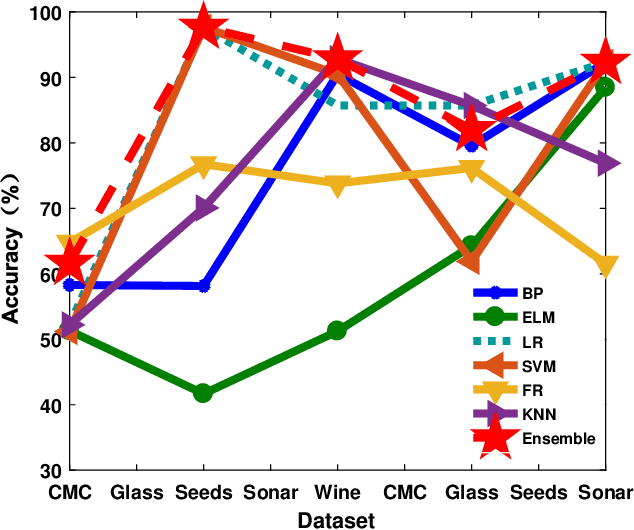
The classification problem is a significant topic in machine learning which aims to teach machines how to group together data by particular criteria. In this paper, a framework for the ensemble learning (EL) method based on group decision making (GDM) has been proposed to resolve this issue. In this framework, base learners can be considered as decision-makers, different categories can be seen as alternatives, classification results obtained by diverse base learners can be considered as performance ratings, and the precision, recall, and accuracy which can reflect the performances of the classification methods can be employed to identify the weights of decision-makers in GDM. Moreover, considering that the precision and recall defined in binary classification problems can not be used directly in the multi-classification problem, the One vs Rest (OvR) has been proposed to obtain the precision and recall of the base learner for each category. The experimental results demonstrate that the proposed EL method based on GDM has higher accuracy than other 6 current popular classification methods in most instances, which verifies the effectiveness of the proposed method.