 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWin-Win Cooperation: Bundling Sequence and Span Models for Named Entity Recognition
Paper and Code
Jul 16, 2022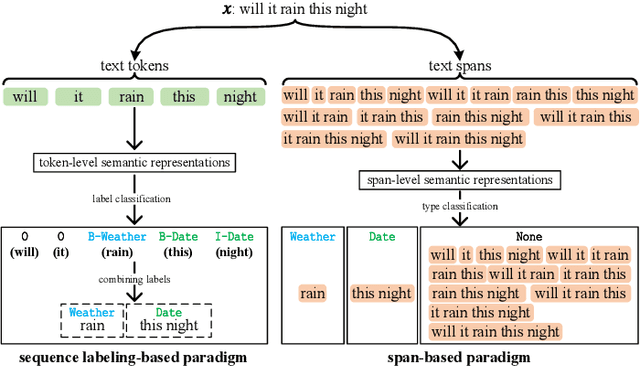
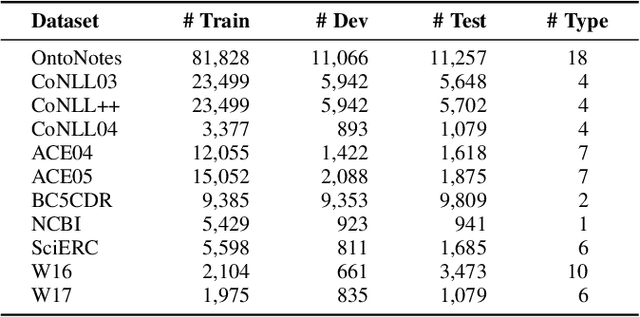

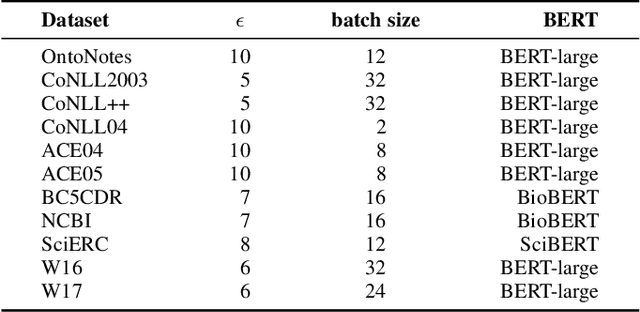
For Named Entity Recognition (NER), sequence labeling-based and span-based paradigms are quite different. Previous research has demonstrated that the two paradigms have clear complementary advantages, but few models have attempted to leverage these advantages in a single NER model as far as we know. In our previous work, we proposed a paradigm known as Bundling Learning (BL) to address the above problem. The BL paradigm bundles the two NER paradigms, enabling NER models to jointly tune their parameters by weighted summing each paradigm's training loss. However, three critical issues remain unresolved: When does BL work? Why does BL work? Can BL enhance the existing state-of-the-art (SOTA) NER models? To address the first two issues, we implement three NER models, involving a sequence labeling-based model--SeqNER, a span-based NER model--SpanNER, and BL-NER that bundles SeqNER and SpanNER together. We draw two conclusions regarding the two issues based on the experimental results on eleven NER datasets from five domains. We then apply BL to five existing SOTA NER models to investigate the third issue, consisting of three sequence labeling-based models and two span-based models. Experimental results indicate that BL consistently enhances their performance, suggesting that it is possible to construct a new SOTA NER system by incorporating BL into the current SOTA system. Moreover, we find that BL reduces both entity boundary and type prediction errors. In addition, we compare two commonly used labeling tagging methods as well as three types of span semantic representations.