 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign and Aggregate: Compositional Reasoning with Video Alignment and Answer Aggregation for Video Question-Answering
Paper and Code
Jul 03, 2024
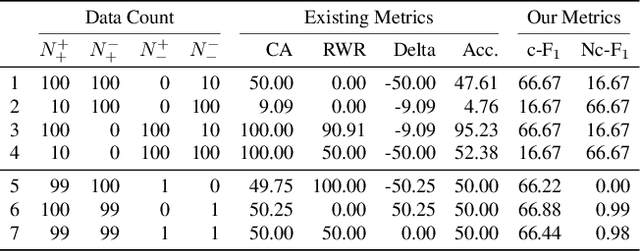
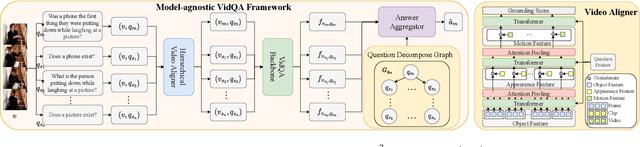

Despite the recent progress made in Video Question-Answering (VideoQA), these methods typically function as black-boxes, making it difficult to understand their reasoning processes and perform consistent compositional reasoning. To address these challenges, we propose a \textit{model-agnostic} Video Alignment and Answer Aggregation (VA$^{3}$) framework, which is capable of enhancing both compositional consistency and accuracy of existing VidQA methods by integrating video aligner and answer aggregator modules. The video aligner hierarchically selects the relevant video clips based on the question, while the answer aggregator deduces the answer to the question based on its sub-questions, with compositional consistency ensured by the information flow along question decomposition graph and the contrastive learning strategy. We evaluate our framework on three settings of the AGQA-Decomp dataset with three baseline methods, and propose new metrics to measure the compositional consistency of VidQA methods more comprehensively. Moreover, we propose a large language model (LLM) based automatic question decomposition pipeline to apply our framework to any VidQA dataset. We extend MSVD and NExT-QA datasets with it to evaluate our VA$^3$ framework on broader scenarios. Extensive experiments show that our framework improves both compositional consistency and accuracy of existing methods, leading to more interpretable real-world VidQA models.