 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottleneck Tokens for Unified Multimodal Retrieval
Apr 13, 2026Adapting decoder-only multimodal large language models (MLLMs) for unified multimodal retrieval faces two structural gaps. First, existing methods rely on implicit pooling, which overloads the hidden state of a standard vocabulary token (e.g., <EOS>) as the sequence-level representation, a mechanism never designed for information aggregation. Second, contrastive fine-tuning specifies what the embedding should match but provides no token-level guidance on how information should be compressed into it. We address both gaps with two complementary components. Architecturally, we introduce Bottleneck Tokens (BToks), a small set of learnable tokens that serve as a fixed-capacity explicit pooling mechanism. For training, we propose Generative Information Condensation: a next-token prediction objective coupled with a Condensation Mask that severs the direct attention path from target tokens to query tokens. All predictive signals are thereby forced through the BToks, converting the generative loss into dense, token-level supervision for semantic compression. At inference time, only the input and BToks are processed in a single forward pass with negligible overhead over conventional last-token pooling. On MMEB-V2 (78 datasets, 3 modalities, 9 meta-tasks), our approach achieves state-of-the-art among 2B-scale methods under comparable data conditions, attaining an Overall score of 59.0 (+3.6 over VLM2Vec-V2) with substantial gains on semantically demanding tasks (e.g., +12.6 on Video-QA).
AIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation
Mar 31, 2026Although image generation has boosted various applications via its rapid evolution, whether the state-of-the-art models are able to produce ready-to-use academic illustrations for papers is still largely unexplored. Directly comparing or evaluating the illustration with VLM is native but requires oracle multi-modal understanding ability, which is unreliable for long and complex texts and illustrations. To address this, we propose AIBench, the first benchmark using VQA for evaluating logic correctness of the academic illustrations and VLMs for assessing aesthetics. In detail, we designed four levels of questions proposed from a logic diagram summarized from the method part of the paper, which query whether the generated illustration aligns with the paper on different scales. Our VQA-based approach raises more accurate and detailed evaluations on visual-logical consistency while relying less on the ability of the judger VLM. With our high-quality AIBench, we conduct extensive experiments and conclude that the performance gap between models on this task is significantly larger than general ones, reflecting their various complex reasoning and high-density generation ability. Further, the logic and aesthetics are hard to optimize simultaneously as in handcrafted illustrations. Additional experiments further state that test-time scaling on both abilities significantly boosts the performance on this task.
ShowTable: Unlocking Creative Table Visualization with Collaborative Reflection and Refinement
Dec 15, 2025While existing generation and unified models excel at general image generation, they struggle with tasks requiring deep reasoning, planning, and precise data-to-visual mapping abilities beyond general scenarios. To push beyond the existing limitations, we introduce a new and challenging task: creative table visualization, requiring the model to generate an infographic that faithfully and aesthetically visualizes the data from a given table. To address this challenge, we propose ShowTable, a pipeline that synergizes MLLMs with diffusion models via a progressive self-correcting process. The MLLM acts as the central orchestrator for reasoning the visual plan and judging visual errors to provide refined instructions, the diffusion execute the commands from MLLM, achieving high-fidelity results. To support this task and our pipeline, we introduce three automated data construction pipelines for training different modules. Furthermore, we introduce TableVisBench, a new benchmark with 800 challenging instances across 5 evaluation dimensions, to assess performance on this task. Experiments demonstrate that our pipeline, instantiated with different models, significantly outperforms baselines, highlighting its effective multi-modal reasoning, generation, and error correction capabilities.
Align and Aggregate: Compositional Reasoning with Video Alignment and Answer Aggregation for Video Question-Answering
Jul 03, 2024
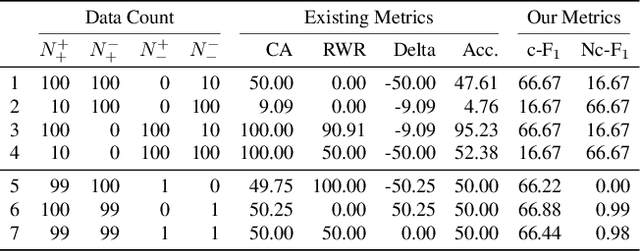
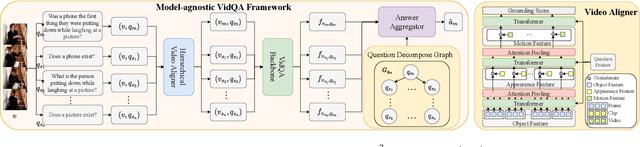

Despite the recent progress made in Video Question-Answering (VideoQA), these methods typically function as black-boxes, making it difficult to understand their reasoning processes and perform consistent compositional reasoning. To address these challenges, we propose a \textit{model-agnostic} Video Alignment and Answer Aggregation (VA$^{3}$) framework, which is capable of enhancing both compositional consistency and accuracy of existing VidQA methods by integrating video aligner and answer aggregator modules. The video aligner hierarchically selects the relevant video clips based on the question, while the answer aggregator deduces the answer to the question based on its sub-questions, with compositional consistency ensured by the information flow along question decomposition graph and the contrastive learning strategy. We evaluate our framework on three settings of the AGQA-Decomp dataset with three baseline methods, and propose new metrics to measure the compositional consistency of VidQA methods more comprehensively. Moreover, we propose a large language model (LLM) based automatic question decomposition pipeline to apply our framework to any VidQA dataset. We extend MSVD and NExT-QA datasets with it to evaluate our VA$^3$ framework on broader scenarios. Extensive experiments show that our framework improves both compositional consistency and accuracy of existing methods, leading to more interpretable real-world VidQA models.
* 10 pages,CVPR
Trainable Activation Function in Image Classification
Jun 05, 2020


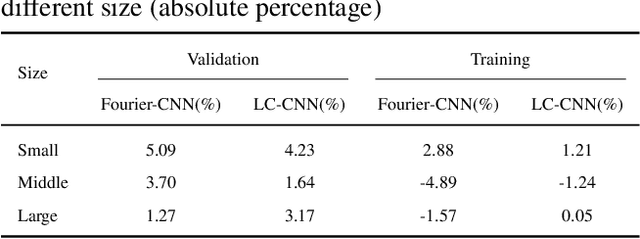
In the current research of neural networks, the activation function is manually specified by human and not able to change themselves during training. This paper focus on how to make the activation function trainable for deep neural networks. We use series and linear combination of different activation functions make activation functions continuously variable. Also, we test the performance of CNNs with Fourier series simulated activation(Fourier-CNN) and CNNs with linear combined activation function (LC-CNN) on Cifar-10 dataset. The result shows our trainable activation function reveals better performance than the most used ReLU activation function. Finally, we improves the performance of Fourier-CNN with Autoencoder, and test the performance of PSO algorithm in optimizing the parameters of networks