 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneity-Aware Dataset Scheduling for Efficient Audio Large Language Model Training
May 18, 2026Training general-purpose Audio Large Language Models (ALLMs) across diverse datasets is essential for holistic audio understanding, yet it faces significant challenges due to dataset heterogeneity, which often leads to conflicting gradients and slow convergence. Despite its impact, how to explicitly manage this heterogeneity during training remains underexplored, with current practices relying primarily on uniform mixture. In this work, we analyze multi-dataset AudioQA training from a convergence perspective and propose Grouped Sequential Training (GST). GST strategically organizes datasets into affinity-aware groups and introduces them via a progressive scheduling protocol, effectively balancing the stability of parallel training with the efficiency of sequential optimization. To ensure scalability, we develop gradient-based affinity metrics that capture inter-dataset relationships without the prohibitive cost of empirical transferability estimation. Extensive evaluations on 14 AudioQA datasets spanning speech, music, and environmental sounds demonstrate that GST achieves 30--40\% faster convergence than standard parallel training while maintaining or even surpassing the performance of mix-all training. Our results provide both theoretical insights and a practical, model-agnostic framework for efficient large-scale ALLM optimization.
Exploiting Task Relationships for Continual Learning Using Transferability-Aware Task Embeddings
Feb 17, 2025



Continual learning (CL) has been an essential topic in the contemporary application of deep neural networks, where catastrophic forgetting (CF) can impede a model's ability to acquire knowledge progressively. Existing CL strategies primarily address CF by regularizing model updates or separating task-specific and shared components. However, these methods focus on task model elements while overlooking the potential of leveraging inter-task relationships for learning enhancement. To address this, we propose a transferability-aware task embedding named H-embedding and train a hypernet under its guidance to learn task-conditioned model weights for CL tasks. Particularly, H-embedding is introduced based on an information theoretical transferability measure and is designed to be online and easy to compute. The framework is also characterized by notable practicality, which only requires storing a low-dimensional task embedding for each task, and can be efficiently trained in an end-to-end way. Extensive evaluations and experimental analyses on datasets including Permuted MNIST, Cifar10/100, and ImageNet-R demonstrate that our framework performs prominently compared to various baseline methods, displaying great potential in exploiting intrinsic task relationships.
H-ensemble: An Information Theoretic Approach to Reliable Few-Shot Multi-Source-Free Transfer
Dec 19, 2023



Multi-source transfer learning is an effective solution to data scarcity by utilizing multiple source tasks for the learning of the target task. However, access to source data and model details is limited in the era of commercial models, giving rise to the setting of multi-source-free (MSF) transfer learning that aims to leverage source domain knowledge without such access. As a newly defined problem paradigm, MSF transfer learning remains largely underexplored and not clearly formulated. In this work, we adopt an information theoretic perspective on it and propose a framework named H-ensemble, which dynamically learns the optimal linear combination, or ensemble, of source models for the target task, using a generalization of maximal correlation regression. The ensemble weights are optimized by maximizing an information theoretic metric for transferability. Compared to previous works, H-ensemble is characterized by: 1) its adaptability to a novel and realistic MSF setting for few-shot target tasks, 2) theoretical reliability, 3) a lightweight structure easy to interpret and adapt. Our method is empirically validated by ablation studies, along with extensive comparative analysis with other task ensemble and transfer learning methods. We show that the H-ensemble can successfully learn the optimal task ensemble, as well as outperform prior arts.
An Effective Data Creation Pipeline to Generate High-quality Financial Instruction Data for Large Language Model
Jul 31, 2023At the beginning era of large language model, it is quite critical to generate a high-quality financial dataset to fine-tune a large language model for financial related tasks. Thus, this paper presents a carefully designed data creation pipeline for this purpose. Particularly, we initiate a dialogue between an AI investor and financial expert using ChatGPT and incorporate the feedback of human financial experts, leading to the refinement of the dataset. This pipeline yielded a robust instruction tuning dataset comprised of 103k multi-turn chats. Extensive experiments have been conducted on this dataset to evaluate the model's performance by adopting an external GPT-4 as the judge. The promising experimental results verify that our approach led to significant advancements in generating accurate, relevant, and financial-style responses from AI models, and thus providing a powerful tool for applications within the financial sector.
SHREC'22 Track: Sketch-Based 3D Shape Retrieval in the Wild
Jul 11, 2022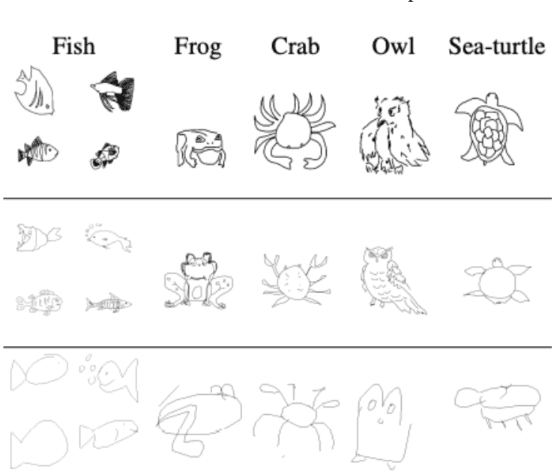
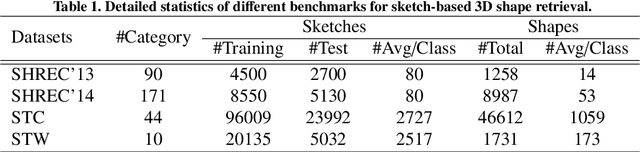
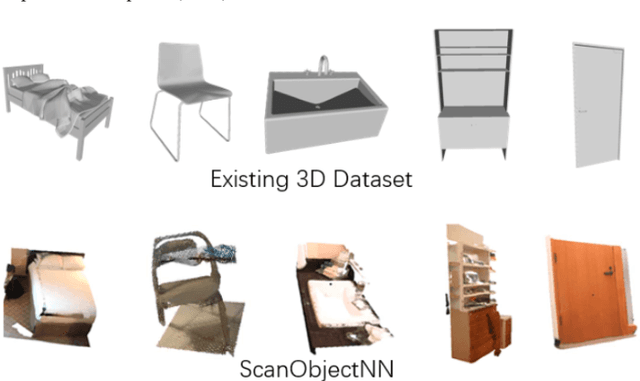
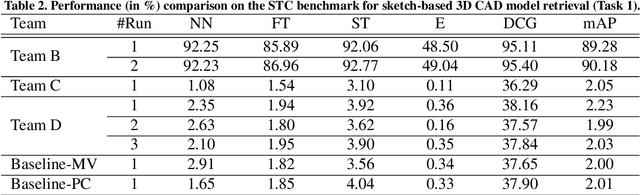
Sketch-based 3D shape retrieval (SBSR) is an important yet challenging task, which has drawn more and more attention in recent years. Existing approaches address the problem in a restricted setting, without appropriately simulating real application scenarios. To mimic the realistic setting, in this track, we adopt large-scale sketches drawn by amateurs of different levels of drawing skills, as well as a variety of 3D shapes including not only CAD models but also models scanned from real objects. We define two SBSR tasks and construct two benchmarks consisting of more than 46,000 CAD models, 1,700 realistic models, and 145,000 sketches in total. Four teams participated in this track and submitted 15 runs for the two tasks, evaluated by 7 commonly-adopted metrics. We hope that, the benchmarks, the comparative results, and the open-sourced evaluation code will foster future research in this direction among the 3D object retrieval community.