 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Fine-Grained Classification by Structure and Subject Preserving Augmentation
Paper and Code
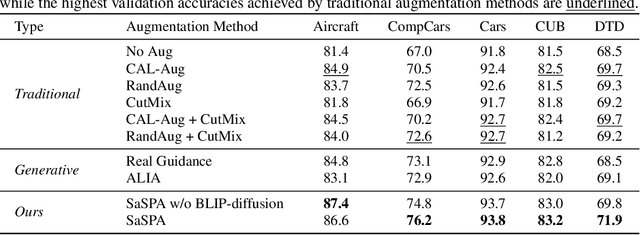
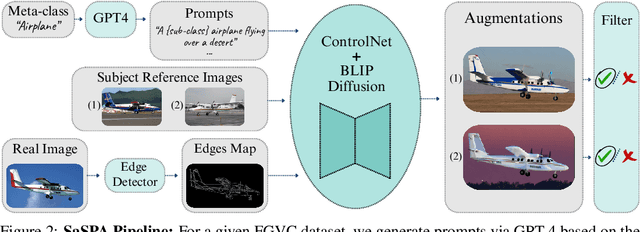
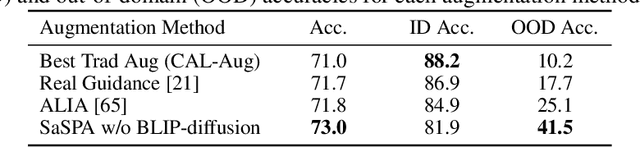

Fine-grained visual classification (FGVC) involves classifying closely related sub-classes. This task is difficult due to the subtle differences between classes and the high intra-class variance. Moreover, FGVC datasets are typically small and challenging to gather, thus highlighting a significant need for effective data augmentation. Recent advancements in text-to-image diffusion models offer new possibilities for augmenting classification datasets. While these models have been used to generate training data for classification tasks, their effectiveness in full-dataset training of FGVC models remains under-explored. Recent techniques that rely on Text2Image generation or Img2Img methods, often struggle to generate images that accurately represent the class while modifying them to a degree that significantly increases the dataset's diversity. To address these challenges, we present SaSPA: Structure and Subject Preserving Augmentation. Contrary to recent methods, our method does not use real images as guidance, thereby increasing generation flexibility and promoting greater diversity. To ensure accurate class representation, we employ conditioning mechanisms, specifically by conditioning on image edges and subject representation. We conduct extensive experiments and benchmark SaSPA against both traditional and recent generative data augmentation methods. SaSPA consistently outperforms all established baselines across multiple settings, including full dataset training, contextual bias, and few-shot classification. Additionally, our results reveal interesting patterns in using synthetic data for FGVC models; for instance, we find a relationship between the amount of real data used and the optimal proportion of synthetic data. Code is available at https://github.com/EyalMichaeli/SaSPA-Aug.