 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification-Regression for Chart Comprehension
Paper and Code
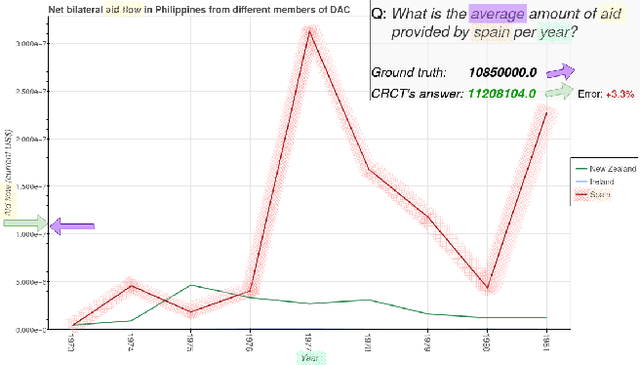
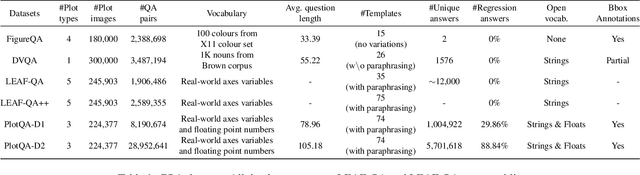
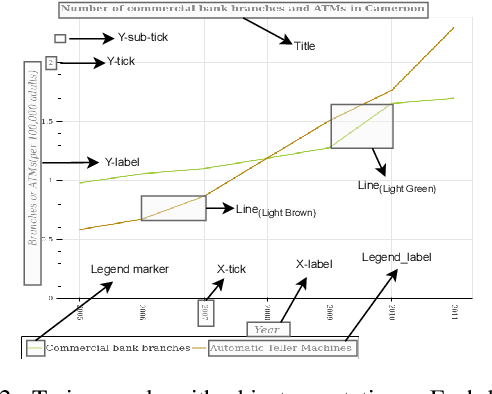
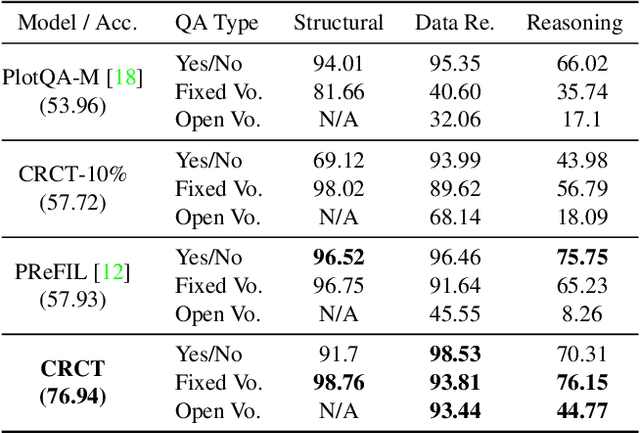
Charts are a popular and effective form of data visualization. Chart question answering (CQA) is a task used for assessing chart comprehension, which is fundamentally different from understanding natural images. CQA requires analyzing the relationships between the textual and the visual components of a chart, in order to answer general questions or infer numerical values. Most existing CQA datasets and it models are based on simplifying assumptions that often enable surpassing human performance. In this work, we further explore the reasons behind this outcome and propose a new model that jointly learns classification and regression. Our language-vision set up with co-attention transformers captures the complex interactions between the question and the textual elements, which commonly exist in real-world charts. We validate these conclusions with extensive experiments and breakdowns on the realistic PlotQA dataset, outperforming previous approaches by a large margin, while showing competitive performance on FigureQA. Our model's edge is particularly emphasized on questions with out-of-vocabulary answers, many of which require regression. We hope that this work will stimulate further research towards solving the challenging and highly practical task of chart comprehension.