 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is the Watermark? Interpretable Watermark Detection at the Block Level
Dec 17, 2025Recent advances in generative AI have enabled the creation of highly realistic digital content, raising concerns around authenticity, ownership, and misuse. While watermarking has become an increasingly important mechanism to trace and protect digital media, most existing image watermarking schemes operate as black boxes, producing global detection scores without offering any insight into how or where the watermark is present. This lack of transparency impacts user trust and makes it difficult to interpret the impact of tampering. In this paper, we present a post-hoc image watermarking method that combines localised embedding with region-level interpretability. Our approach embeds watermark signals in the discrete wavelet transform domain using a statistical block-wise strategy. This allows us to generate detection maps that reveal which regions of an image are likely watermarked or altered. We show that our method achieves strong robustness against common image transformations while remaining sensitive to semantic manipulations. At the same time, the watermark remains highly imperceptible. Compared to prior post-hoc methods, our approach offers more interpretable detection while retaining competitive robustness. For example, our watermarks are robust to cropping up to half the image.
AdaptDel: Adaptable Deletion Rate Randomized Smoothing for Certified Robustness
Nov 12, 2025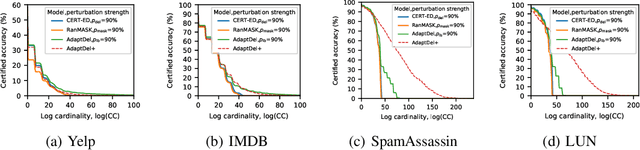
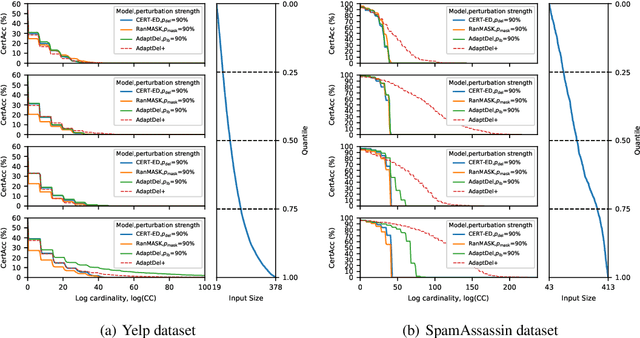
We consider the problem of certified robustness for sequence classification against edit distance perturbations. Naturally occurring inputs of varying lengths (e.g., sentences in natural language processing tasks) present a challenge to current methods that employ fixed-rate deletion mechanisms and lead to suboptimal performance. To this end, we introduce AdaptDel methods with adaptable deletion rates that dynamically adjust based on input properties. We extend the theoretical framework of randomized smoothing to variable-rate deletion, ensuring sound certification with respect to edit distance. We achieve strong empirical results in natural language tasks, observing up to 30 orders of magnitude improvement to median cardinality of the certified region, over state-of-the-art certifications.
Adaptive Data Analysis for Growing Data
May 22, 2024



Reuse of data in adaptive workflows poses challenges regarding overfitting and the statistical validity of results. Previous work has demonstrated that interacting with data via differentially private algorithms can mitigate overfitting, achieving worst-case generalization guarantees with asymptotically optimal data requirements. However, such past work assumes data is static and cannot accommodate situations where data grows over time. In this paper we address this gap, presenting the first generalization bounds for adaptive analysis in the dynamic data setting. We allow the analyst to adaptively schedule their queries conditioned on the current size of the data, in addition to previous queries and responses. We also incorporate time-varying empirical accuracy bounds and mechanisms, allowing for tighter guarantees as data accumulates. In a batched query setting, the asymptotic data requirements of our bound grows with the square-root of the number of adaptive queries, matching prior works' improvement over data splitting for the static setting. We instantiate our bound for statistical queries with the clipped Gaussian mechanism, where it empirically outperforms baselines composed from static bounds.
Certified Robustness of Learning-based Static Malware Detectors
Jan 31, 2023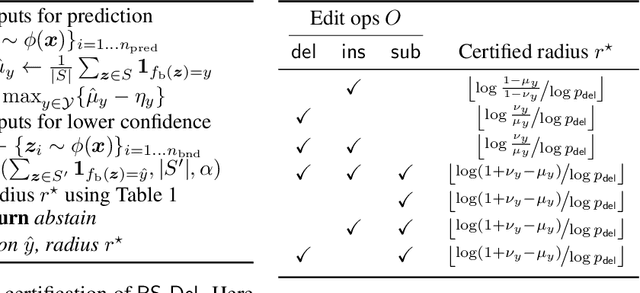


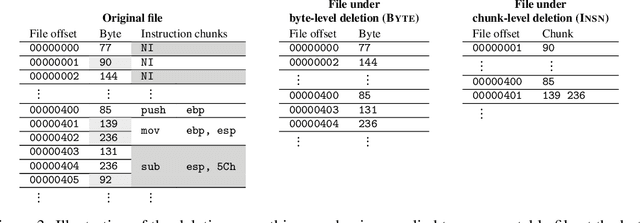
Certified defenses are a recent development in adversarial machine learning (ML), which aim to rigorously guarantee the robustness of ML models to adversarial perturbations. A large body of work studies certified defenses in computer vision, where $\ell_p$ norm-bounded evasion attacks are adopted as a tractable threat model. However, this threat model has known limitations in vision, and is not applicable to other domains -- e.g., where inputs may be discrete or subject to complex constraints. Motivated by this gap, we study certified defenses for malware detection, a domain where attacks against ML-based systems are a real and current threat. We consider static malware detection systems that operate on byte-level data. Our certified defense is based on the approach of randomized smoothing which we adapt by: (1) replacing the standard Gaussian randomization scheme with a novel deletion randomization scheme that operates on bytes or chunks of an executable; and (2) deriving a certificate that measures robustness to evasion attacks in terms of generalized edit distance. To assess the size of robustness certificates that are achievable while maintaining high accuracy, we conduct experiments on malware datasets using a popular convolutional malware detection model, MalConv. We are able to accurately classify 91% of the inputs while being certifiably robust to any adversarial perturbations of edit distance 128 bytes or less. By comparison, an existing certification of up to 128 bytes of substitutions (without insertions or deletions) achieves an accuracy of 78%. In addition, given that robustness certificates are conservative, we evaluate practical robustness to several recently published evasion attacks and, in some cases, find robustness beyond certified guarantees.
Hard to Forget: Poisoning Attacks on Certified Machine Unlearning
Sep 17, 2021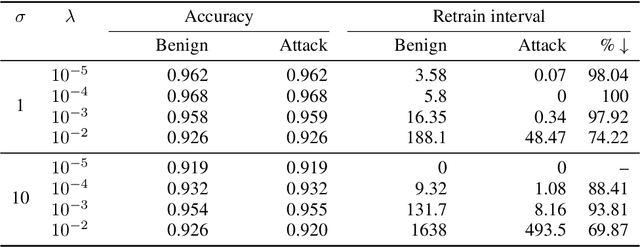
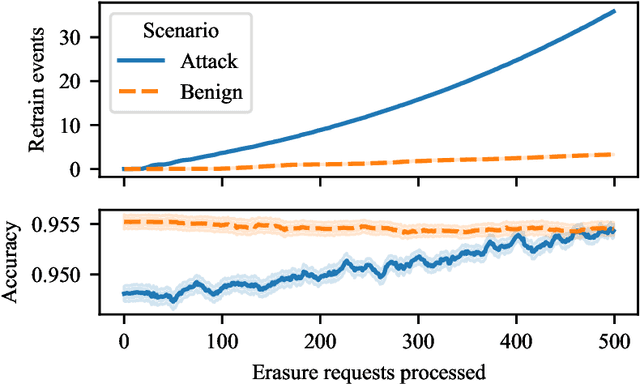
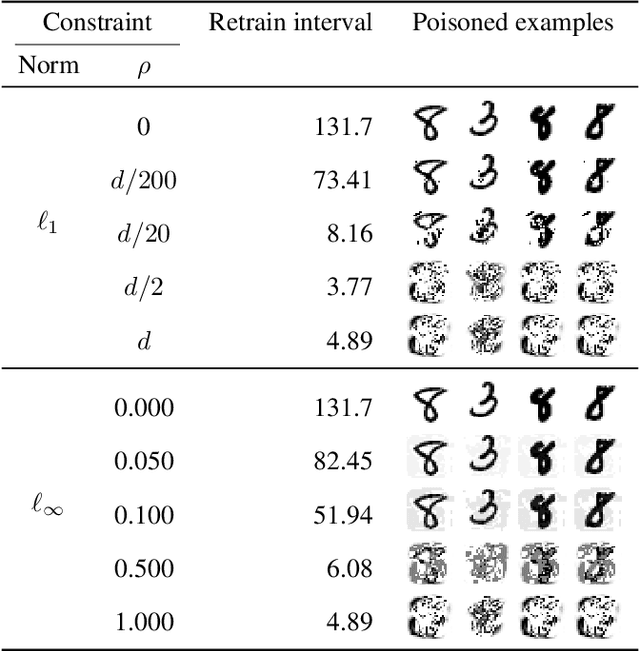

The right to erasure requires removal of a user's information from data held by organizations, with rigorous interpretations extending to downstream products such as learned models. Retraining from scratch with the particular user's data omitted fully removes its influence on the resulting model, but comes with a high computational cost. Machine "unlearning" mitigates the cost incurred by full retraining: instead, models are updated incrementally, possibly only requiring retraining when approximation errors accumulate. Rapid progress has been made towards privacy guarantees on the indistinguishability of unlearned and retrained models, but current formalisms do not place practical bounds on computation. In this paper we demonstrate how an attacker can exploit this oversight, highlighting a novel attack surface introduced by machine unlearning. We consider an attacker aiming to increase the computational cost of data removal. We derive and empirically investigate a poisoning attack on certified machine unlearning where strategically designed training data triggers complete retraining when removed.
A general framework for label-efficient online evaluation with asymptotic guarantees
Jun 12, 2020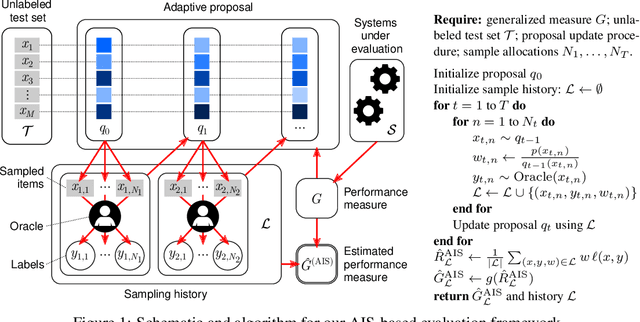
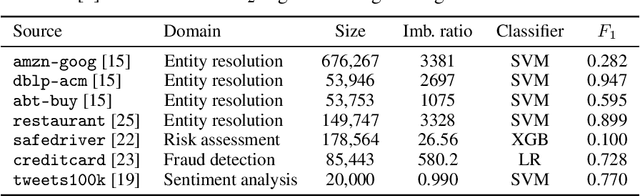
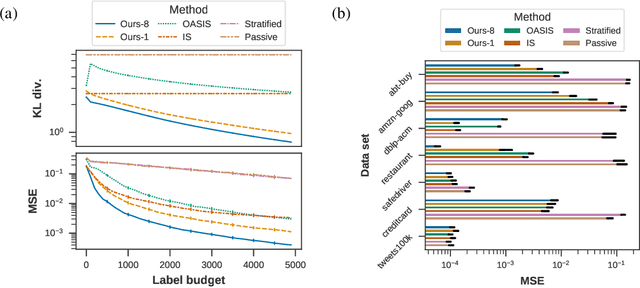
Achieving statistically significant evaluation with passive sampling of test data is challenging in settings such as extreme classification and record linkage, where significant class imbalance is prevalent. Adaptive importance sampling focuses labeling on informative regions of the instance space, however it breaks data independence assumptions - commonly required for asymptotic guarantees that assure estimates approximate population performance and provide practical confidence intervals. In this paper we develop an adaptive importance sampling framework for supervised evaluation that defines a sequence of proposal distributions given a user-defined discriminative model of p(y|x) and a generalized performance measure to evaluate. Under verifiable conditions on the model and performance measure, we establish strong consistency and a (martingale) central limit theorem for resulting performance estimates. We instantiate our framework with worked examples given stochastic or deterministic label oracle access. Both examples leverage Dirichlet-tree models for practical online evaluation, with the deterministic case achieving asymptotic optimality. Experiments on seven datasets demonstrate an average mean-squared error superior to state-of-the-art samplers on fixed label budgets.
d-blink: Distributed End-to-End Bayesian Entity Resolution
Sep 13, 2019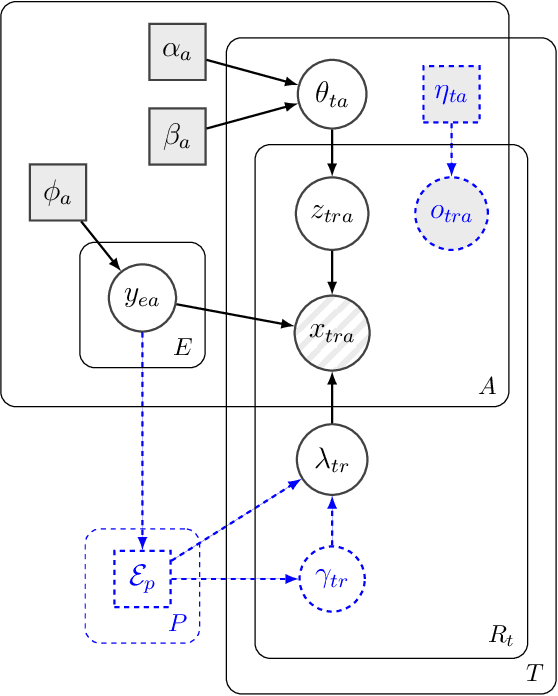
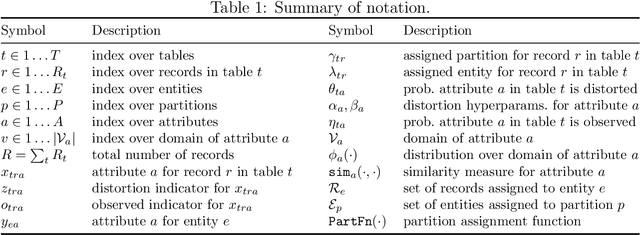

Entity resolution (ER) (record linkage or de-duplication) is the process of merging together noisy databases, often in the absence of a unique identifier. A major advancement in ER methodology has been the application of Bayesian generative models. Such models provide a natural framework for clustering records to unobserved (latent) entities, while providing exact uncertainty quantification and tight performance bounds. Despite these advancements, existing models do not scale to realistically-sized databases (larger than 1000 records) and they do not incorporate probabilistic blocking. In this paper, we propose "distributed Bayesian linkage" or d-blink -- the first scalable and distributed end-to-end Bayesian model for ER, which propagates uncertainty in blocking, matching and merging. We make several novel contributions, including: (i) incorporating probabilistic blocking directly into the model through auxiliary partitions; (ii) support for missing values; (iii) a partially-collapsed Gibbs sampler; and (iv) a novel perturbation sampling algorithm (leveraging the Vose-Alias method) that enables fast updates of the entity attributes. Finally, we conduct experiments on five data sets which show that d-blink can achieve significant efficiency gains -- in excess of 300$\times$ -- when compared to existing non-distributed methods.
In Search of an Entity Resolution OASIS: Optimal Asymptotic Sequential Importance Sampling
Jun 26, 2017

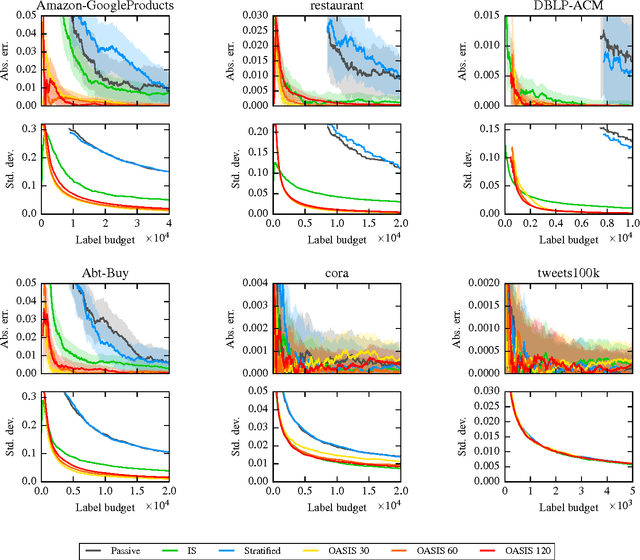
Entity resolution (ER) presents unique challenges for evaluation methodology. While crowdsourcing platforms acquire ground truth, sound approaches to sampling must drive labelling efforts. In ER, extreme class imbalance between matching and non-matching records can lead to enormous labelling requirements when seeking statistically consistent estimates for rigorous evaluation. This paper addresses this important challenge with the OASIS algorithm: a sampler and F-measure estimator for ER evaluation. OASIS draws samples from a (biased) instrumental distribution, chosen to ensure estimators with optimal asymptotic variance. As new labels are collected OASIS updates this instrumental distribution via a Bayesian latent variable model of the annotator oracle, to quickly focus on unlabelled items providing more information. We prove that resulting estimates of F-measure, precision, recall converge to the true population values. Thorough comparisons of sampling methods on a variety of ER datasets demonstrate significant labelling reductions of up to 83% without loss to estimate accuracy.