 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard to Forget: Poisoning Attacks on Certified Machine Unlearning
Paper and Code
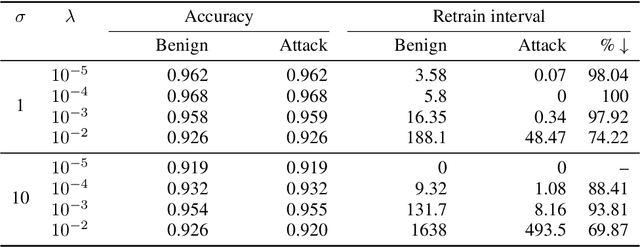
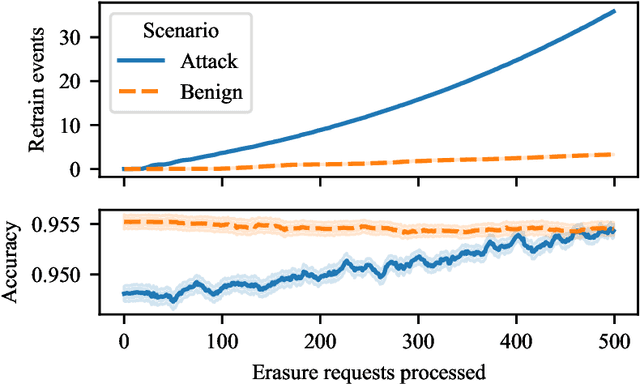
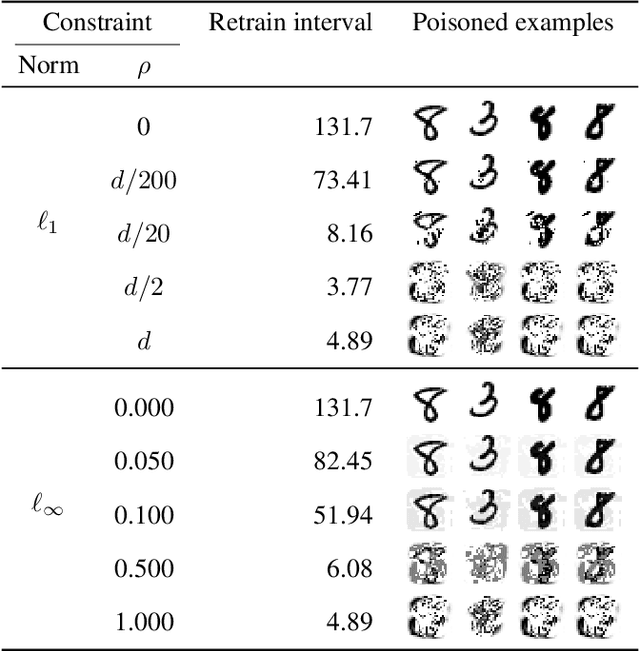

The right to erasure requires removal of a user's information from data held by organizations, with rigorous interpretations extending to downstream products such as learned models. Retraining from scratch with the particular user's data omitted fully removes its influence on the resulting model, but comes with a high computational cost. Machine "unlearning" mitigates the cost incurred by full retraining: instead, models are updated incrementally, possibly only requiring retraining when approximation errors accumulate. Rapid progress has been made towards privacy guarantees on the indistinguishability of unlearned and retrained models, but current formalisms do not place practical bounds on computation. In this paper we demonstrate how an attacker can exploit this oversight, highlighting a novel attack surface introduced by machine unlearning. We consider an attacker aiming to increase the computational cost of data removal. We derive and empirically investigate a poisoning attack on certified machine unlearning where strategically designed training data triggers complete retraining when removed.