 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Online Planning for Min-Max Problems in Networked Markov Games
May 29, 2024


Min-max problems are important in multi-agent sequential decision-making because they improve the performance of the worst-performing agent in the network. However, solving the multi-agent min-max problem is challenging. We propose a modular, distributed, online planning-based algorithm that is able to approximate the solution of the min-max objective in networked Markov games, assuming that the agents communicate within a network topology and the transition and reward functions are neighborhood-dependent. This set-up is encountered in the multi-robot setting. Our method consists of two phases at every planning step. In the first phase, each agent obtains sample returns based on its local reward function, by performing online planning. Using the samples from online planning, each agent constructs a concave approximation of its underlying local return as a function of only the action of its neighborhood at the next planning step. In the second phase, the agents deploy a distributed optimization framework that converges to the optimal immediate next action for each agent, based on the function approximations of the first phase. We demonstrate our algorithm's performance through formation control simulations.
Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination
Jan 28, 2022
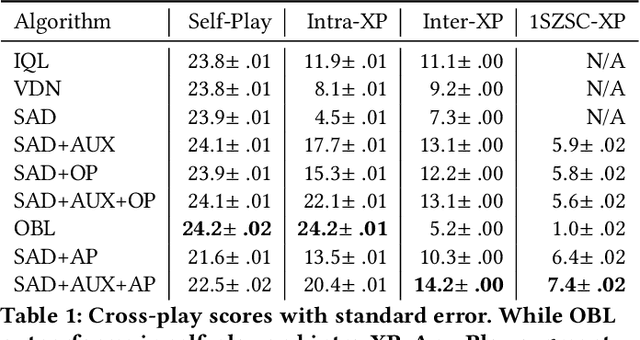
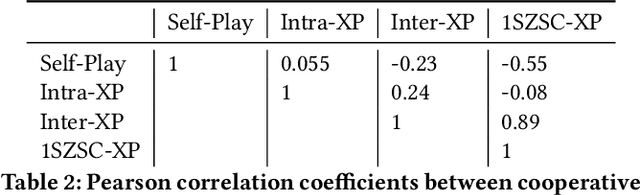
Cooperative artificial intelligence with human or superhuman proficiency in collaborative tasks stands at the frontier of machine learning research. Prior work has tended to evaluate cooperative AI performance under the restrictive paradigms of self-play (teams composed of agents trained together) and cross-play (teams of agents trained independently but using the same algorithm). Recent work has indicated that AI optimized for these narrow settings may make for undesirable collaborators in the real-world. We formalize an alternative criteria for evaluating cooperative AI, referred to as inter-algorithm cross-play, where agents are evaluated on teaming performance with all other agents within an experiment pool with no assumption of algorithmic similarities between agents. We show that existing state-of-the-art cooperative AI algorithms, such as Other-Play and Off-Belief Learning, under-perform in this paradigm. We propose the Any-Play learning augmentation -- a multi-agent extension of diversity-based intrinsic rewards for zero-shot coordination (ZSC) -- for generalizing self-play-based algorithms to the inter-algorithm cross-play setting. We apply the Any-Play learning augmentation to the Simplified Action Decoder (SAD) and demonstrate state-of-the-art performance in the collaborative card game Hanabi.
Evaluation of Human-AI Teams for Learned and Rule-Based Agents in Hanabi
Jul 20, 2021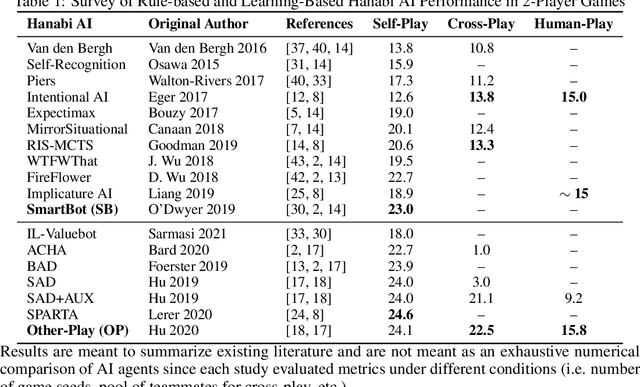
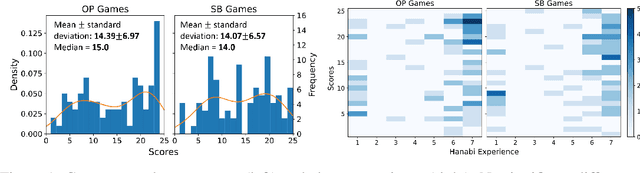
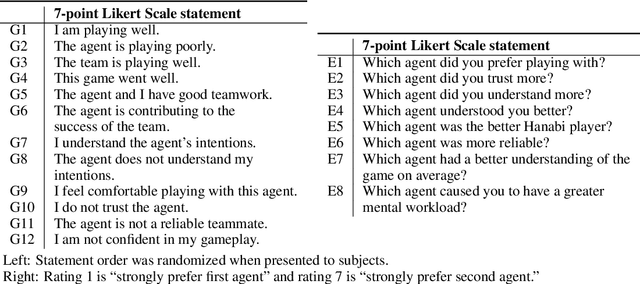
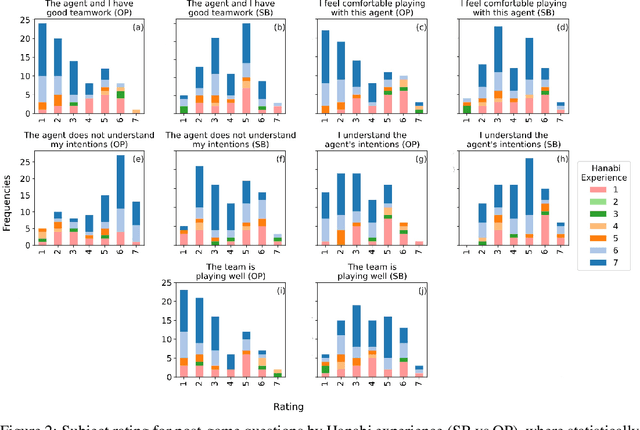
Deep reinforcement learning has generated superhuman AI in competitive games such as Go and StarCraft. Can similar learning techniques create a superior AI teammate for human-machine collaborative games? Will humans prefer AI teammates that improve objective team performance or those that improve subjective metrics of trust? In this study, we perform a single-blind evaluation of teams of humans and AI agents in the cooperative card game Hanabi, with both rule-based and learning-based agents. In addition to the game score, used as an objective metric of the human-AI team performance, we also quantify subjective measures of the human's perceived performance, teamwork, interpretability, trust, and overall preference of AI teammate. We find that humans have a clear preference toward a rule-based AI teammate (SmartBot) over a state-of-the-art learning-based AI teammate (Other-Play) across nearly all subjective metrics, and generally view the learning-based agent negatively, despite no statistical difference in the game score. This result has implications for future AI design and reinforcement learning benchmarking, highlighting the need to incorporate subjective metrics of human-AI teaming rather than a singular focus on objective task performance.
Health-Informed Policy Gradients for Multi-Agent Reinforcement Learning
Aug 02, 2019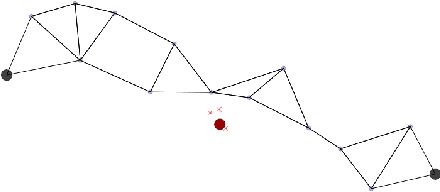
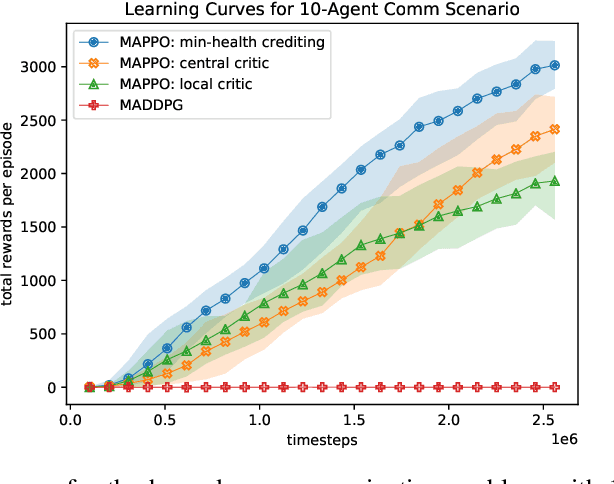
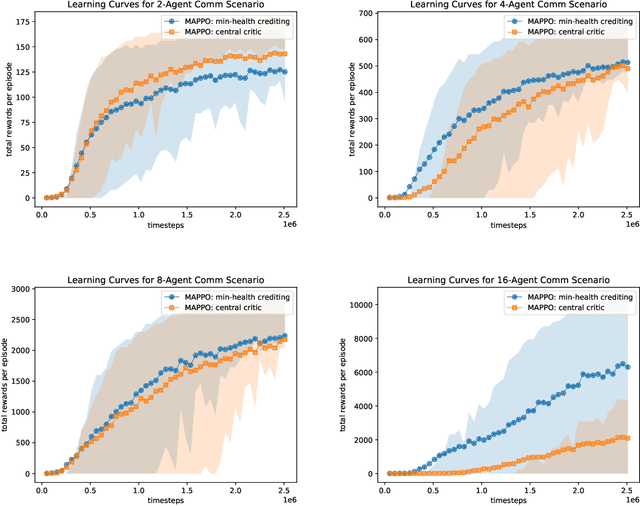
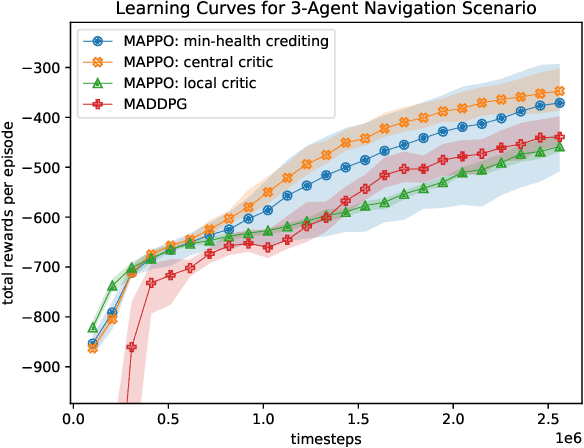
This paper proposes a definition of system health in the context of multiple agents optimizing a joint reward function. We use this definition as a credit assignment term in a policy gradient algorithm to distinguish the contributions of individual agents to the global reward. The health-informed credit assignment is then extended to a multi-agent variant of the proximal policy optimization algorithm and demonstrated on simple particle environments that have elements of system health, risk-taking, semi-expendable agents, and partial observability. We show significant improvement in learning performance compared to policy gradient methods that do not perform multi-agent credit assignment.