 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating High-fidelity, Synthetic Time Series Datasets with DoppelGANger
Sep 30, 2019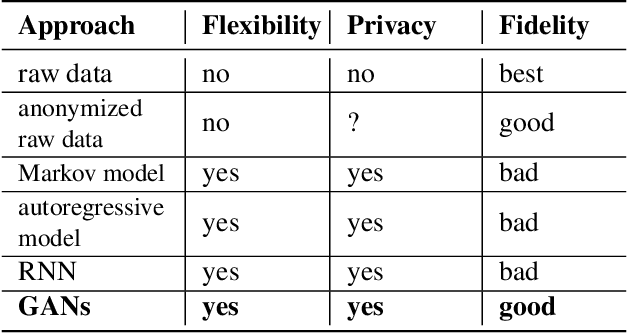
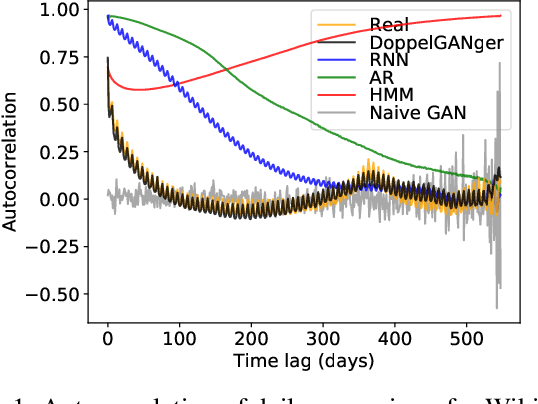
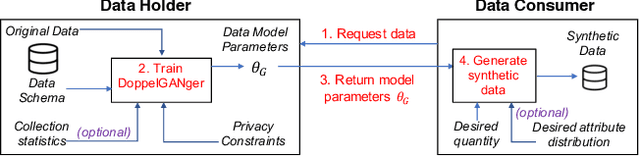
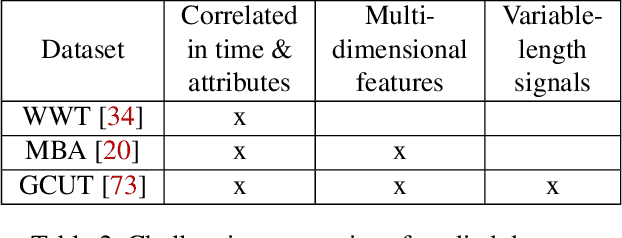
Limited data access is a substantial barrier to data-driven networking research and development. Although many organizations are motivated to share data, privacy concerns often prevent the sharing of proprietary data, including between teams in the same organization and with outside stakeholders (e.g., researchers, vendors). Many researchers have therefore proposed synthetic data models, most of which have not gained traction because of their narrow scope. In this work, we present DoppelGANger, a synthetic data generation framework based on generative adversarial networks (GANs). DoppelGANger is designed to work on time series datasets with both continuous features (e.g. traffic measurements) and discrete ones (e.g., protocol name). Modeling time series and mixed-type data is known to be difficult; DoppelGANger circumvents these problems through a new conditional architecture that isolates the generation of metadata from time series, but uses metadata to strongly influence time series generation. We demonstrate the efficacy of DoppelGANger on three real-world datasets. We show that DoppelGANger achieves up to 43% better fidelity than baseline models, and captures structural properties of data that baseline methods are unable to learn. Additionally, it gives data holders an easy mechanism for protecting attributes of their data without substantial loss of data utility.
Entity Projection via Machine Translation for Cross-Lingual NER
Sep 13, 2019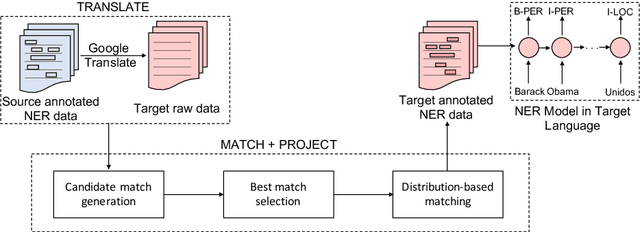

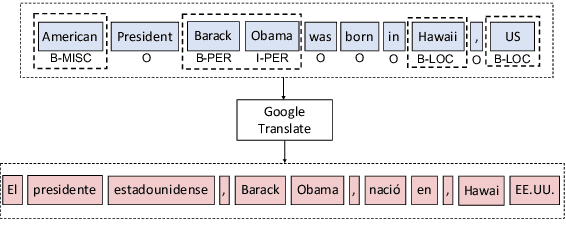

Although over 100 languages are supported by strong off-the-shelf machine translation systems, only a subset of them possess large annotated corpora for named entity recognition. Motivated by this fact, we leverage machine translation to improve annotation-projection approaches to cross-lingual named entity recognition. We propose a system that improves over prior entity-projection methods by: (a) leveraging machine translation systems twice: first for translating sentences and subsequently for translating entities; (b) matching entities based on orthographic and phonetic similarity; and (c) identifying matches based on distributional statistics derived from the dataset. Our approach improves upon current state-of-the-art methods for cross-lingual named entity recognition on 5 diverse languages by an average of 4.1 points. Further, our method achieves state-of-the-art F_1 scores for Armenian, outperforming even a monolingual model trained on Armenian source data.