 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Resilient Collective Communication Library for LLM Training and Serving
Dec 31, 2025Modern ML training and inference now span tens to tens of thousands of GPUs, where network faults can waste 10--15\% of GPU hours due to slow recovery. Common network errors and link fluctuations trigger timeouts that often terminate entire jobs, forcing expensive checkpoint rollback during training and request reprocessing during inference. We present R$^2$CCL, a fault-tolerant communication library that provides lossless, low-overhead failover by exploiting multi-NIC hardware. R$^2$CCL performs rapid connection migration, bandwidth-aware load redistribution, and resilient collective algorithms to maintain progress under failures. We evaluate R$^2$CCL on two 8-GPU H100 InfiniBand servers and via large-scale ML simulators modeling hundreds of GPUs with diverse failure patterns. Experiments show that R$^2$CCL is highly robust to NIC failures, incurring less than 1\% training and less than 3\% inference overheads. R$^2$CCL outperforms baselines AdapCC and DejaVu by 12.18$\times$ and 47$\times$, respectively.
GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
Mar 11, 2024



Key-value (KV) caching has become the de-facto to accelerate generation speed for large language models (LLMs) inference. However, the growing cache demand with increasing sequence length has transformed LLM inference to be a memory bound problem, significantly constraining the system throughput. Existing methods rely on dropping unimportant tokens or quantizing all entries uniformly. Such methods, however, often incur high approximation errors to represent the compressed matrices. The autoregressive decoding process further compounds the error of each step, resulting in critical deviation in model generation and deterioration of performance. To tackle this challenge, we propose GEAR, an efficient KV cache compression framework that achieves near-lossless high-ratio compression. GEAR first applies quantization to majority of entries of similar magnitudes to ultra-low precision. It then employs a low rank matrix to approximate the quantization error, and a sparse matrix to remedy individual errors from outlier entries. By adeptly integrating three techniques, GEAR is able to fully exploit their synergistic potentials. Our experiments demonstrate that compared to alternatives, GEAR achieves near-lossless 4-bit KV cache compression with up to 2.38x throughput improvement, while reducing peak-memory size up to 2.29x. Our code is publicly available at https://github.com/HaoKang-Timmy/GEAR.
Privacy for Free: Communication-Efficient Learning with Differential Privacy Using Sketches
Dec 06, 2019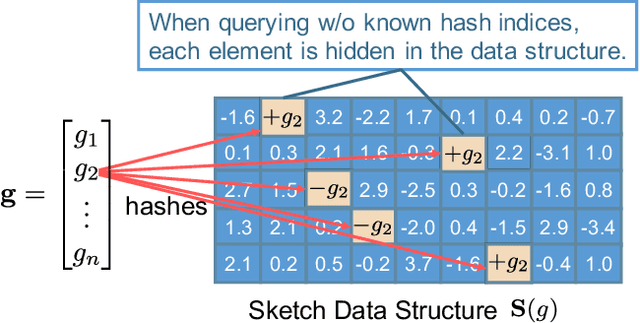

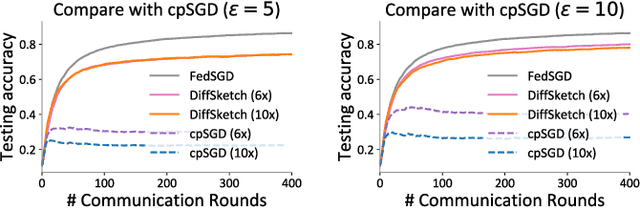
Communication and privacy are two critical concerns in distributed learning. Many existing works treat these concerns separately. In this work, we argue that a natural connection exists between methods for communication reduction and privacy preservation in the context of distributed machine learning. In particular, we prove that Count Sketch, a simple method for data stream summarization, has inherent differential privacy properties. Using these derived privacy guarantees, we propose a novel sketch-based framework (DiffSketch) for distributed learning, where we compress the transmitted messages via sketches to simultaneously achieve communication efficiency and provable privacy benefits. Our evaluation demonstrates that DiffSketch can provide strong differential privacy guarantees (e.g., $\varepsilon$= 1) and reduce communication by 20-50x with only marginal decreases in accuracy. Compared to baselines that treat privacy and communication separately, DiffSketch improves absolute test accuracy by 5%-50% while offering the same privacy guarantees and communication compression.
Enhancing the Privacy of Federated Learning with Sketching
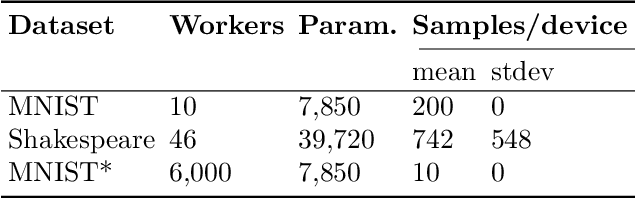
Nov 05, 2019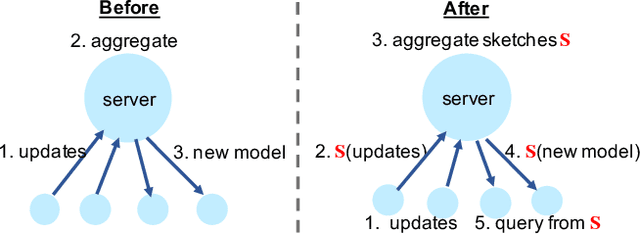
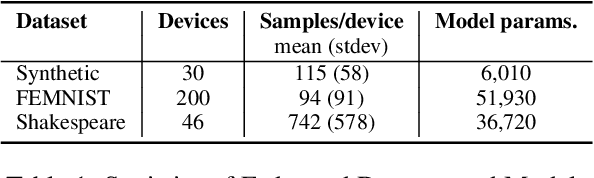
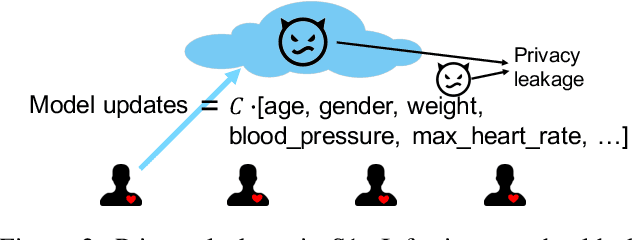
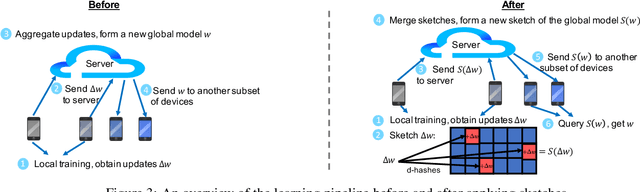
In response to growing concerns about user privacy, federated learning has emerged as a promising tool to train statistical models over networks of devices while keeping data localized. Federated learning methods run training tasks directly on user devices and do not share the raw user data with third parties. However, current methods still share model updates, which may contain private information (e.g., one's weight and height), during the training process. Existing efforts that aim to improve the privacy of federated learning make compromises in one or more of the following key areas: performance (particularly communication cost), accuracy, or privacy. To better optimize these trade-offs, we propose that \textit{sketching algorithms} have a unique advantage in that they can provide both privacy and performance benefits while maintaining accuracy. We evaluate the feasibility of sketching-based federated learning with a prototype on three representative learning models. Our initial findings show that it is possible to provide strong privacy guarantees for federated learning without sacrificing performance or accuracy. Our work highlights that there exists a fundamental connection between privacy and communication in distributed settings, and suggests important open problems surrounding the theoretical understanding, methodology, and system design of practical, private federated learning.