 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset
Jun 04, 2025This paper introduces HiFiTTS-2, a large-scale speech dataset designed for high-bandwidth speech synthesis. The dataset is derived from LibriVox audiobooks, and contains approximately 36.7k hours of English speech for 22.05 kHz training, and 31.7k hours for 44.1 kHz training. We present our data processing pipeline, including bandwidth estimation, segmentation, text preprocessing, and multi-speaker detection. The dataset is accompanied by detailed utterance and audiobook metadata generated by our pipeline, enabling researchers to apply data quality filters to adapt the dataset to various use cases. Experimental results demonstrate that our data pipeline and resulting dataset can facilitate the training of high-quality, zero-shot text-to-speech (TTS) models at high bandwidths.
Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
Feb 07, 2025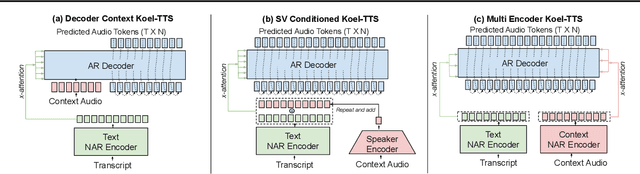
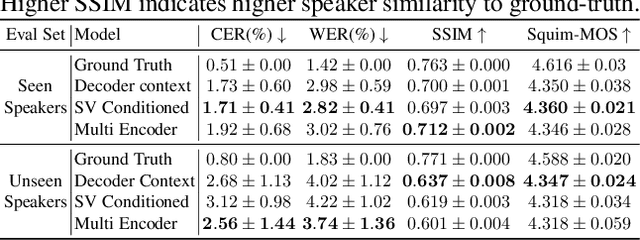
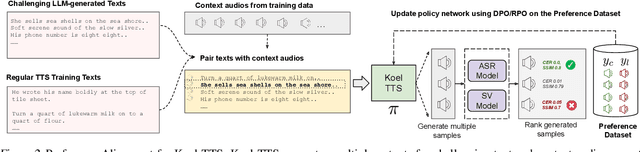
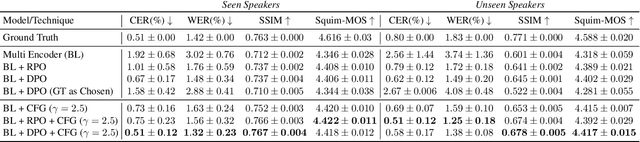
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
Low Frame-rate Speech Codec: a Codec Designed for Fast High-quality Speech LLM Training and Inference
Sep 18, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modeling techniques to audio data. However, audio codecs often operate at high frame rates, resulting in slow training and inference, especially for autoregressive models. To address this challenge, we present the Low Frame-rate Speech Codec (LFSC): a neural audio codec that leverages finite scalar quantization and adversarial training with large speech language models to achieve high-quality audio compression with a 1.89 kbps bitrate and 21.5 frames per second. We demonstrate that our novel codec can make the inference of LLM-based text-to-speech models around three times faster while improving intelligibility and producing quality comparable to previous models.
Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment
Jun 25, 2024



Large Language Model (LLM) based text-to-speech (TTS) systems have demonstrated remarkable capabilities in handling large speech datasets and generating natural speech for new speakers. However, LLM-based TTS models are not robust as the generated output can contain repeating words, missing words and mis-aligned speech (referred to as hallucinations or attention errors), especially when the text contains multiple occurrences of the same token. We examine these challenges in an encoder-decoder transformer model and find that certain cross-attention heads in such models implicitly learn the text and speech alignment when trained for predicting speech tokens for a given text. To make the alignment more robust, we propose techniques utilizing CTC loss and attention priors that encourage monotonic cross-attention over the text tokens. Our guided attention training technique does not introduce any new learnable parameters and significantly improves robustness of LLM-based TTS models.
REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models
Oct 18, 2023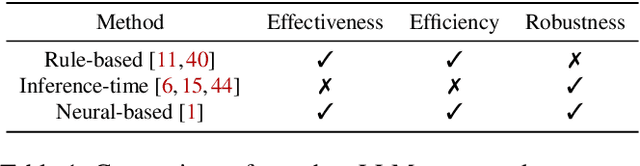
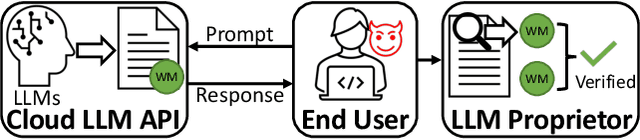
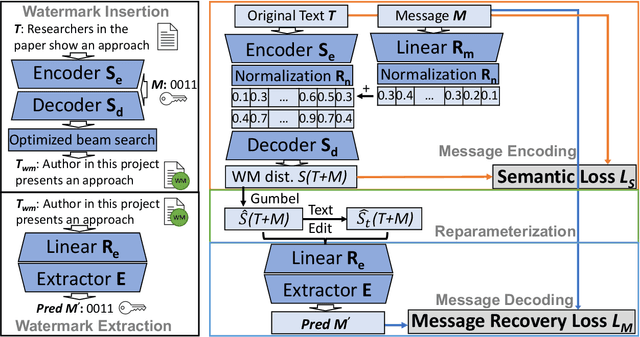
We present REMARK-LLM, a novel efficient, and robust watermarking framework designed for texts generated by large language models (LLMs). Synthesizing human-like content using LLMs necessitates vast computational resources and extensive datasets, encapsulating critical intellectual property (IP). However, the generated content is prone to malicious exploitation, including spamming and plagiarism. To address the challenges, REMARK-LLM proposes three new components: (i) a learning-based message encoding module to infuse binary signatures into LLM-generated texts; (ii) a reparameterization module to transform the dense distributions from the message encoding to the sparse distribution of the watermarked textual tokens; (iii) a decoding module dedicated for signature extraction; Furthermore, we introduce an optimized beam search algorithm to guarantee the coherence and consistency of the generated content. REMARK-LLM is rigorously trained to encourage the preservation of semantic integrity in watermarked content, while ensuring effective watermark retrieval. Extensive evaluations on multiple unseen datasets highlight REMARK-LLM proficiency and transferability in inserting 2 times more signature bits into the same texts when compared to prior art, all while maintaining semantic integrity. Furthermore, REMARK-LLM exhibits better resilience against a spectrum of watermark detection and removal attacks.
SelfVC: Voice Conversion With Iterative Refinement using Self Transformations
Oct 14, 2023



We propose SelfVC, a training strategy to iteratively improve a voice conversion model with self-synthesized examples. Previous efforts on voice conversion focus on explicitly disentangling speech representations to separately encode speaker characteristics and linguistic content. However, disentangling speech representations to capture such attributes using task-specific loss terms can lead to information loss by discarding finer nuances of the original signal. In this work, instead of explicitly disentangling attributes with loss terms, we present a framework to train a controllable voice conversion model on entangled speech representations derived from self-supervised learning and speaker verification models. First, we develop techniques to derive prosodic information from the audio signal and SSL representations to train predictive submodules in the synthesis model. Next, we propose a training strategy to iteratively improve the synthesis model for voice conversion, by creating a challenging training objective using self-synthesized examples. In this training approach, the current state of the synthesis model is used to generate voice-converted variations of an utterance, which serve as inputs for the reconstruction task, ensuring a continuous and purposeful refinement of the model. We demonstrate that incorporating such self-synthesized examples during training improves the speaker similarity of generated speech as compared to a baseline voice conversion model trained solely on heuristically perturbed inputs. SelfVC is trained without any text and is applicable to a range of tasks such as zero-shot voice conversion, cross-lingual voice conversion, and controllable speech synthesis with pitch and pace modifications. SelfVC achieves state-of-the-art results in zero-shot voice conversion on metrics evaluating naturalness, speaker similarity, and intelligibility of synthesized audio.
ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-supervised Speech Representations
Feb 16, 2023In this work, we propose a zero-shot voice conversion method using speech representations trained with self-supervised learning. First, we develop a multi-task model to decompose a speech utterance into features such as linguistic content, speaker characteristics, and speaking style. To disentangle content and speaker representations, we propose a training strategy based on Siamese networks that encourages similarity between the content representations of the original and pitch-shifted audio. Next, we develop a synthesis model with pitch and duration predictors that can effectively reconstruct the speech signal from its decomposed representation. Our framework allows controllable and speaker-adaptive synthesis to perform zero-shot any-to-any voice conversion achieving state-of-the-art results on metrics evaluating speaker similarity, intelligibility, and naturalness. Using just 10 seconds of data for a target speaker, our framework can perform voice swapping and achieves a speaker verification EER of 5.5% for seen speakers and 8.4% for unseen speakers.
FastStamp: Accelerating Neural Steganography and Digital Watermarking of Images on FPGAs
Sep 26, 2022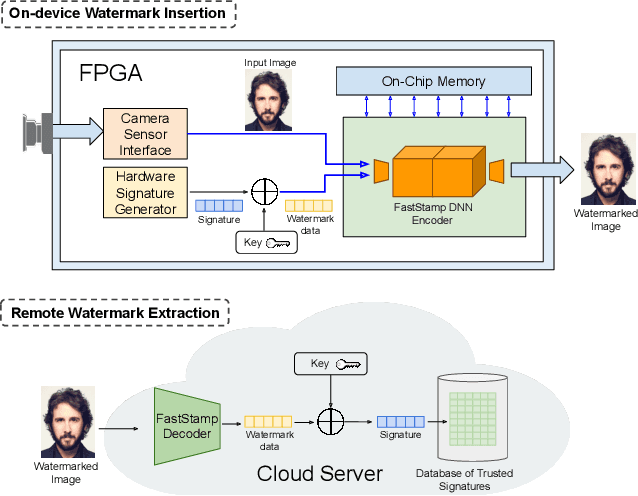
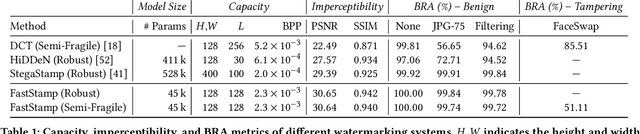

Steganography and digital watermarking are the tasks of hiding recoverable data in image pixels. Deep neural network (DNN) based image steganography and watermarking techniques are quickly replacing traditional hand-engineered pipelines. DNN based watermarking techniques have drastically improved the message capacity, imperceptibility and robustness of the embedded watermarks. However, this improvement comes at the cost of increased computational overhead of the watermark encoder neural network. In this work, we design the first accelerator platform FastStamp to perform DNN based steganography and digital watermarking of images on hardware. We first propose a parameter efficient DNN model for embedding recoverable bit-strings in image pixels. Our proposed model can match the success metrics of prior state-of-the-art DNN based watermarking methods while being significantly faster and lighter in terms of memory footprint. We then design an FPGA based accelerator framework to further improve the model throughput and power consumption by leveraging data parallelism and customized computation paths. FastStamp allows embedding hardware signatures into images to establish media authenticity and ownership of digital media. Our best design achieves 68 times faster inference as compared to GPU implementations of prior DNN based watermark encoder while consuming less power.
ReFace: Real-time Adversarial Attacks on Face Recognition Systems
Jun 09, 2022
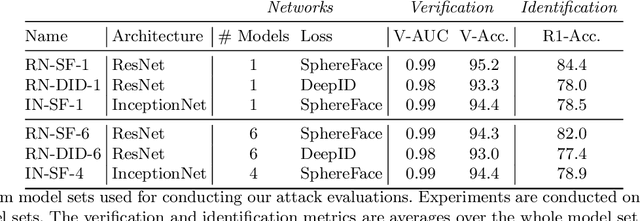
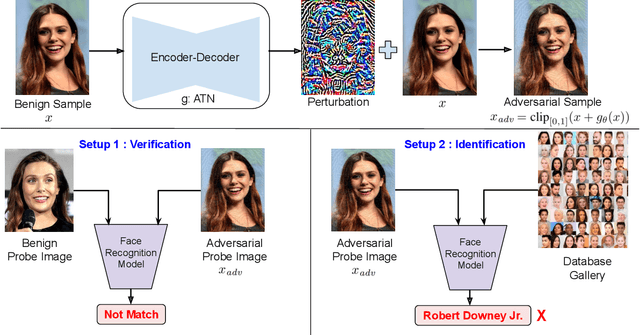
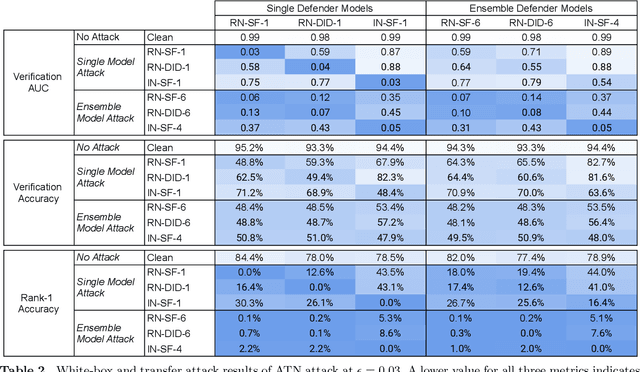
Deep neural network based face recognition models have been shown to be vulnerable to adversarial examples. However, many of the past attacks require the adversary to solve an input-dependent optimization problem using gradient descent which makes the attack impractical in real-time. These adversarial examples are also tightly coupled to the attacked model and are not as successful in transferring to different models. In this work, we propose ReFace, a real-time, highly-transferable attack on face recognition models based on Adversarial Transformation Networks (ATNs). ATNs model adversarial example generation as a feed-forward neural network. We find that the white-box attack success rate of a pure U-Net ATN falls substantially short of gradient-based attacks like PGD on large face recognition datasets. We therefore propose a new architecture for ATNs that closes this gap while maintaining a 10000x speedup over PGD. Furthermore, we find that at a given perturbation magnitude, our ATN adversarial perturbations are more effective in transferring to new face recognition models than PGD. ReFace attacks can successfully deceive commercial face recognition services in a transfer attack setting and reduce face identification accuracy from 82% to 16.4% for AWS SearchFaces API and Azure face verification accuracy from 91% to 50.1%.
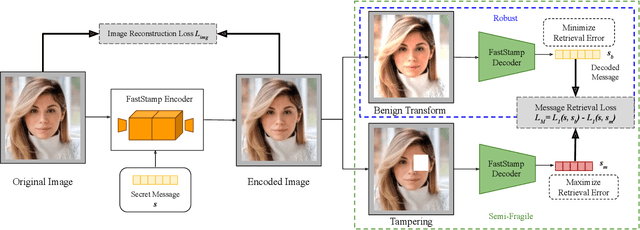
FaceSigns: Semi-Fragile Neural Watermarks for Media Authentication and Countering Deepfakes
Apr 05, 2022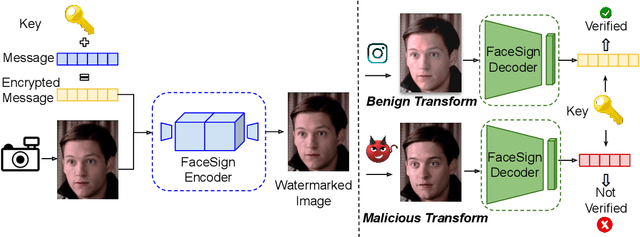
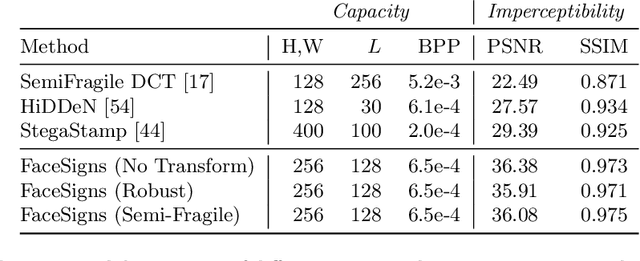
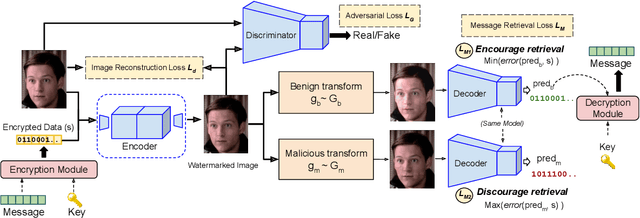
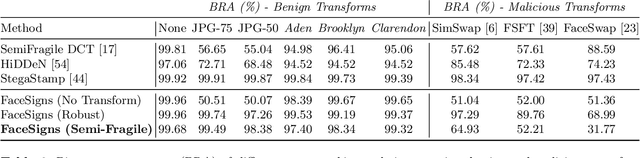
Deepfakes and manipulated media are becoming a prominent threat due to the recent advances in realistic image and video synthesis techniques. There have been several attempts at combating Deepfakes using machine learning classifiers. However, such classifiers do not generalize well to black-box image synthesis techniques and have been shown to be vulnerable to adversarial examples. To address these challenges, we introduce a deep learning based semi-fragile watermarking technique that allows media authentication by verifying an invisible secret message embedded in the image pixels. Instead of identifying and detecting fake media using visual artifacts, we propose to proactively embed a semi-fragile watermark into a real image so that we can prove its authenticity when needed. Our watermarking framework is designed to be fragile to facial manipulations or tampering while being robust to benign image-processing operations such as image compression, scaling, saturation, contrast adjustments etc. This allows images shared over the internet to retain the verifiable watermark as long as face-swapping or any other Deepfake modification technique is not applied. We demonstrate that FaceSigns can embed a 128 bit secret as an imperceptible image watermark that can be recovered with a high bit recovery accuracy at several compression levels, while being non-recoverable when unseen Deepfake manipulations are applied. For a set of unseen benign and Deepfake manipulations studied in our work, FaceSigns can reliably detect manipulated content with an AUC score of 0.996 which is significantly higher than prior image watermarking and steganography techniques.