 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiLaDiff: Distilled Latent-Augmented Diffusion for Language Modeling
May 22, 2026Diffusion language models intrinsically fail to capture correlations between decoded tokens, which leads to a harsh trade-off between sampling quality and throughput. To solve this issue, we propose DiLaDiff, a variant of masked diffusion language models with three components: (1) a continuous latent space with semantic capabilities, learned by an auto-encoder fine-tuned from an existing masked diffusion language model; (2) a latent diffusion model learning the prior over the encoder distribution; (3) a consistency model distilling the learned prior into a few-step latent generative model. We show that, even without distillation, our latent-guided diffusion model outperforms the masked diffusion baseline while significantly accelerating inference. Consistency distillation further lowers the computational overhead of continuous diffusion, such that the latent is generated in negligible time compared to discrete decoding.
MDM-ASR: Bridging Accuracy and Efficiency in ASR with Diffusion-Based Non-Autoregressive Decoding
Feb 24, 2026In sequence-to-sequence Transformer ASR, autoregressive (AR) models achieve strong accuracy but suffer from slow decoding, while non-autoregressive (NAR) models enable parallel decoding at the cost of degraded performance. We propose a principled NAR ASR framework based on Masked Diffusion Models to reduce this gap. A pre-trained speech encoder is coupled with a Transformer diffusion decoder conditioned on acoustic features and partially masked transcripts for parallel token prediction. To mitigate the training-inference mismatch, we introduce Iterative Self-Correction Training that exposes the model to its own intermediate predictions. We also design a Position-Biased Entropy-Bounded Confidence-based sampler with positional bias to further boost results. Experiments across multiple benchmarks demonstrate consistent gains over prior NAR models and competitive performance with strong AR baselines, while retaining parallel decoding efficiency.
Universal Speech Enhancement with Regression and Generative Mamba
May 27, 2025



The Interspeech 2025 URGENT Challenge aimed to advance universal, robust, and generalizable speech enhancement by unifying speech enhancement tasks across a wide variety of conditions, including seven different distortion types and five languages. We present Universal Speech Enhancement Mamba (USEMamba), a state-space speech enhancement model designed to handle long-range sequence modeling, time-frequency structured processing, and sampling frequency-independent feature extraction. Our approach primarily relies on regression-based modeling, which performs well across most distortions. However, for packet loss and bandwidth extension, where missing content must be inferred, a generative variant of the proposed USEMamba proves more effective. Despite being trained on only a subset of the full training data, USEMamba achieved 2nd place in Track 1 during the blind test phase, demonstrating strong generalization across diverse conditions.
Robust Speech Recognition with Schrödinger Bridge-Based Speech Enhancement
May 07, 2025
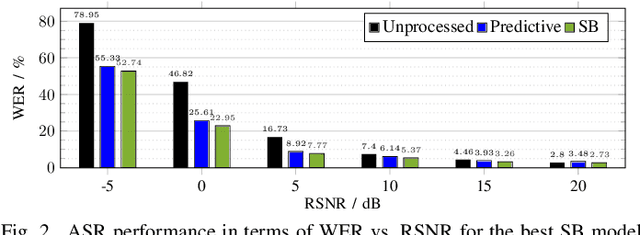


In this work, we investigate application of generative speech enhancement to improve the robustness of ASR models in noisy and reverberant conditions. We employ a recently-proposed speech enhancement model based on Schr\"odinger bridge, which has been shown to perform well compared to diffusion-based approaches. We analyze the impact of model scaling and different sampling methods on the ASR performance. Furthermore, we compare the considered model with predictive and diffusion-based baselines and analyze the speech recognition performance when using different pre-trained ASR models. The proposed approach significantly reduces the word error rate, reducing it by approximately 40% relative to the unprocessed speech signals and by approximately 8% relative to a similarly sized predictive approach.
* 5 pages. Published in ICASSP 2025
Generative Speech Foundation Model Pretraining for High-Quality Speech Extraction and Restoration
Sep 25, 2024



This paper proposes a generative pretraining foundation model for high-quality speech restoration tasks. By directly operating on complex-valued short-time Fourier transform coefficients, our model does not rely on any vocoders for time-domain signal reconstruction. As a result, our model simplifies the synthesis process and removes the quality upper-bound introduced by any mel-spectrogram vocoder compared to prior work SpeechFlow. The proposed method is evaluated on multiple speech restoration tasks, including speech denoising, bandwidth extension, codec artifact removal, and target speaker extraction. In all scenarios, finetuning our pretrained model results in superior performance over strong baselines. Notably, in the target speaker extraction task, our model outperforms existing systems, including those leveraging SSL-pretrained encoders like WavLM. The code and the pretrained checkpoints are publicly available in the NVIDIA NeMo framework.
Low Frame-rate Speech Codec: a Codec Designed for Fast High-quality Speech LLM Training and Inference
Sep 18, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modeling techniques to audio data. However, audio codecs often operate at high frame rates, resulting in slow training and inference, especially for autoregressive models. To address this challenge, we present the Low Frame-rate Speech Codec (LFSC): a neural audio codec that leverages finite scalar quantization and adversarial training with large speech language models to achieve high-quality audio compression with a 1.89 kbps bitrate and 21.5 frames per second. We demonstrate that our novel codec can make the inference of LLM-based text-to-speech models around three times faster while improving intelligibility and producing quality comparable to previous models.
Schrödinger Bridge for Generative Speech Enhancement
Jul 22, 2024



This paper proposes a generative speech enhancement model based on Schr\"odinger bridge (SB). The proposed model is employing a tractable SB to formulate a data-to-data process between the clean speech distribution and the observed noisy speech distribution. The model is trained with a data prediction loss, aiming to recover the complex-valued clean speech coefficients, and an auxiliary time-domain loss is used to improve training of the model. The effectiveness of the proposed SB-based model is evaluated in two different speech enhancement tasks: speech denoising and speech dereverberation. The experimental results demonstrate that the proposed SB-based outperforms diffusion-based models in terms of speech quality metrics and ASR performance, e.g., resulting in relative word error rate reduction of 20% for denoising and 6% for dereverberation compared to the best baseline model. The proposed model also demonstrates improved efficiency, achieving better quality than the baselines for the same number of sampling steps and with a reduced computational cost.
Codec-ASR: Training Performant Automatic Speech Recognition Systems with Discrete Speech Representations
Jul 03, 2024
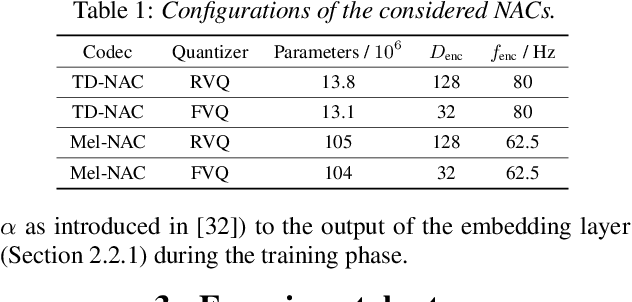

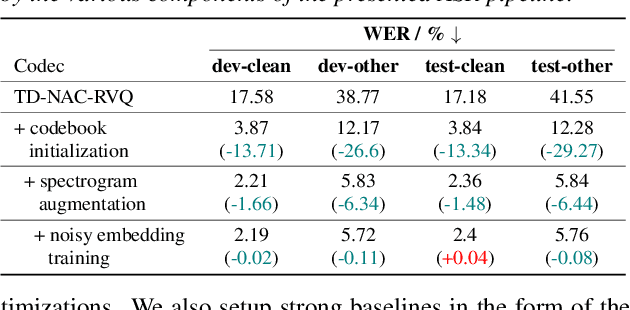
Discrete speech representations have garnered recent attention for their efficacy in training transformer-based models for various speech-related tasks such as automatic speech recognition (ASR), translation, speaker verification, and joint speech-text foundational models. In this work, we present a comprehensive analysis on building ASR systems with discrete codes. We investigate different methods for codec training such as quantization schemes and time-domain vs spectral feature encodings. We further explore ASR training techniques aimed at enhancing performance, training efficiency, and noise robustness. Drawing upon our findings, we introduce a codec ASR pipeline that outperforms Encodec at similar bit-rate. Remarkably, it also surpasses the state-of-the-art results achieved by strong self-supervised models on the 143 languages ML-SUPERB benchmark despite being smaller in size and pretrained on significantly less data.
Spectral Codecs: Spectrogram-Based Audio Codecs for High Quality Speech Synthesis
Jun 07, 2024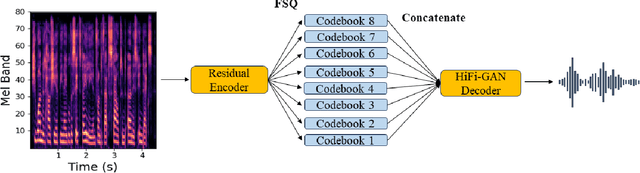

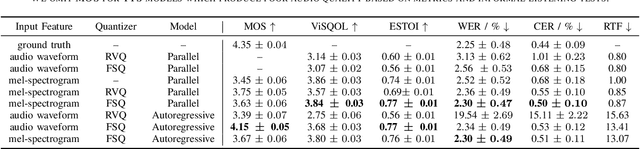
Historically, most speech models in machine-learning have used the mel-spectrogram as a speech representation. Recently, discrete audio tokens produced by neural audio codecs have become a popular alternate speech representation for speech synthesis tasks such as text-to-speech (TTS). However, the data distribution produced by such codecs is too complex for some TTS models to predict, hence requiring large autoregressive models to get reasonable quality. Typical audio codecs compress and reconstruct the time-domain audio signal. We propose a spectral codec which compresses the mel-spectrogram and reconstructs the time-domain audio signal. A study of objective audio quality metrics suggests that our spectral codec has comparable perceptual quality to equivalent audio codecs. Furthermore, non-autoregressive TTS models trained with the proposed spectral codec generate audio with significantly higher quality than when trained with mel-spectrograms or audio codecs.
Flexible Multichannel Speech Enhancement for Noise-Robust Frontend
Jun 06, 2024



This paper proposes a flexible multichannel speech enhancement system with the main goal of improving robustness of automatic speech recognition (ASR) in noisy conditions. The proposed system combines a flexible neural mask estimator applicable to different channel counts and configurations and a multichannel filter with automatic reference selection. A transform-attend-concatenate layer is proposed to handle cross-channel information in the mask estimator, which is shown to be effective for arbitrary microphone configurations. The presented evaluation demonstrates the effectiveness of the flexible system for several seen and unseen compact array geometries, matching the performance of fixed configuration-specific systems. Furthermore, a significantly improved ASR performance is observed for configurations with randomly-placed microphones.