 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodec-ASR: Training Performant Automatic Speech Recognition Systems with Discrete Speech Representations
Paper and Code

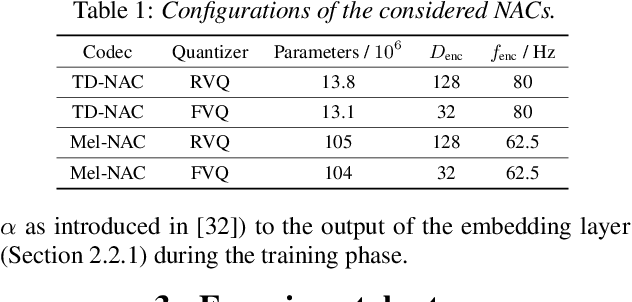

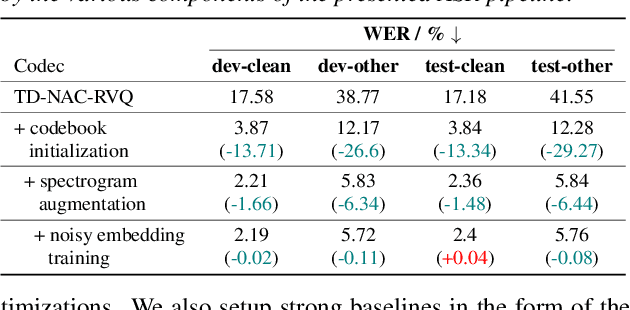
Discrete speech representations have garnered recent attention for their efficacy in training transformer-based models for various speech-related tasks such as automatic speech recognition (ASR), translation, speaker verification, and joint speech-text foundational models. In this work, we present a comprehensive analysis on building ASR systems with discrete codes. We investigate different methods for codec training such as quantization schemes and time-domain vs spectral feature encodings. We further explore ASR training techniques aimed at enhancing performance, training efficiency, and noise robustness. Drawing upon our findings, we introduce a codec ASR pipeline that outperforms Encodec at similar bit-rate. Remarkably, it also surpasses the state-of-the-art results achieved by strong self-supervised models on the 143 languages ML-SUPERB benchmark despite being smaller in size and pretrained on significantly less data.