 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Speech Recognition with Schrödinger Bridge-Based Speech Enhancement
May 07, 2025
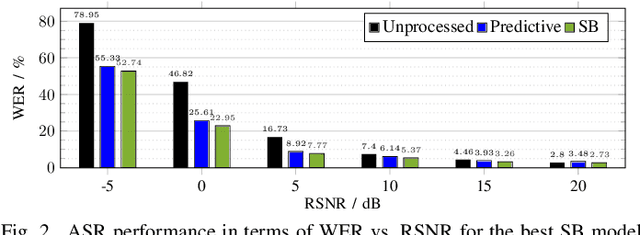


In this work, we investigate application of generative speech enhancement to improve the robustness of ASR models in noisy and reverberant conditions. We employ a recently-proposed speech enhancement model based on Schr\"odinger bridge, which has been shown to perform well compared to diffusion-based approaches. We analyze the impact of model scaling and different sampling methods on the ASR performance. Furthermore, we compare the considered model with predictive and diffusion-based baselines and analyze the speech recognition performance when using different pre-trained ASR models. The proposed approach significantly reduces the word error rate, reducing it by approximately 40% relative to the unprocessed speech signals and by approximately 8% relative to a similarly sized predictive approach.
* 5 pages. Published in ICASSP 2025
Generative Speech Foundation Model Pretraining for High-Quality Speech Extraction and Restoration
Sep 25, 2024



This paper proposes a generative pretraining foundation model for high-quality speech restoration tasks. By directly operating on complex-valued short-time Fourier transform coefficients, our model does not rely on any vocoders for time-domain signal reconstruction. As a result, our model simplifies the synthesis process and removes the quality upper-bound introduced by any mel-spectrogram vocoder compared to prior work SpeechFlow. The proposed method is evaluated on multiple speech restoration tasks, including speech denoising, bandwidth extension, codec artifact removal, and target speaker extraction. In all scenarios, finetuning our pretrained model results in superior performance over strong baselines. Notably, in the target speaker extraction task, our model outperforms existing systems, including those leveraging SSL-pretrained encoders like WavLM. The code and the pretrained checkpoints are publicly available in the NVIDIA NeMo framework.
Schrödinger Bridge for Generative Speech Enhancement
Jul 22, 2024



This paper proposes a generative speech enhancement model based on Schr\"odinger bridge (SB). The proposed model is employing a tractable SB to formulate a data-to-data process between the clean speech distribution and the observed noisy speech distribution. The model is trained with a data prediction loss, aiming to recover the complex-valued clean speech coefficients, and an auxiliary time-domain loss is used to improve training of the model. The effectiveness of the proposed SB-based model is evaluated in two different speech enhancement tasks: speech denoising and speech dereverberation. The experimental results demonstrate that the proposed SB-based outperforms diffusion-based models in terms of speech quality metrics and ASR performance, e.g., resulting in relative word error rate reduction of 20% for denoising and 6% for dereverberation compared to the best baseline model. The proposed model also demonstrates improved efficiency, achieving better quality than the baselines for the same number of sampling steps and with a reduced computational cost.
Text-only domain adaptation for end-to-end ASR using integrated text-to-mel-spectrogram generator
Feb 27, 2023



We propose an end-to-end ASR system that can be trained on transcribed speech data, text data, or a mixture of both. For text-only training, our extended ASR model uses an integrated auxiliary TTS block that creates mel spectrograms from the text. This block contains a conventional non-autoregressive text-to-mel-spectrogram generator augmented with a GAN enhancer to improve the spectrogram quality. The proposed system can improve the accuracy of the ASR model on a new domain by using text-only data, and allows to significantly surpass conventional audio-text training by using large text corpora.
You Do Not Need More Data: Improving End-To-End Speech Recognition by Text-To-Speech Data Augmentation
May 14, 2020
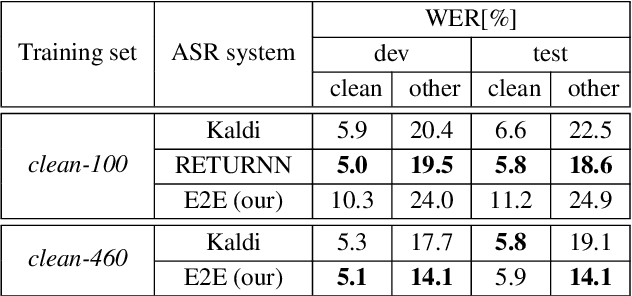
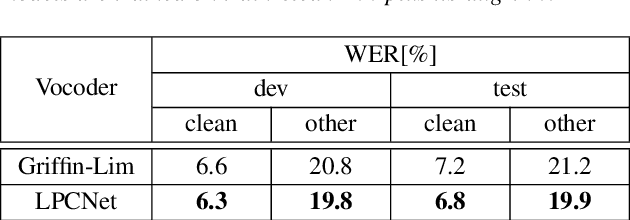
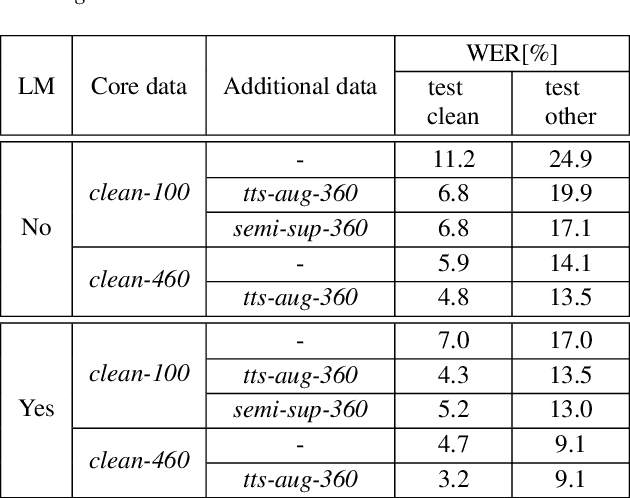
Data augmentation is one of the most effective ways to make end-to-end automatic speech recognition (ASR) perform close to the conventional hybrid approach, especially when dealing with low-resource tasks. Using recent advances in speech synthesis (text-to-speech, or TTS), we build our TTS system on an ASR training database and then extend the data with synthesized speech to train a recognition model. We argue that, when the training data amount is low, this approach can allow an end-to-end model to reach hybrid systems' quality. For an artificial low-resource setup, we compare the proposed augmentation with the semi-supervised learning technique. We also investigate the influence of vocoder usage on final ASR performance by comparing Griffin-Lim algorithm with our modified LPCNet. An external language model allows our approach to reach the quality of a comparable supervised setup and outperform a semi-supervised setup (both on test-clean). We establish a state-of-the-art result for end-to-end ASR trained on LibriSpeech train-clean-100 set with WER 4.3% on test-clean and 13.5% on test-other.