 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunk-wise Attention Transducers for Fast and Accurate Streaming Speech-to-Text
Feb 27, 2026We propose Chunk-wise Attention Transducer (CHAT), a novel extension to RNN-T models that processes audio in fixed-size chunks while employing cross-attention within each chunk. This hybrid approach maintains RNN-T's streaming capability while introducing controlled flexibility for local alignment modeling. CHAT significantly reduces the temporal dimension that RNN-T must handle, yielding substantial efficiency improvements: up to 46.2% reduction in peak training memory, up to 1.36X faster training, and up to 1.69X faster inference. Alongside these efficiency gains, CHAT achieves consistent accuracy improvements over RNN-T across multiple languages and tasks -- up to 6.3% relative WER reduction for speech recognition and up to 18.0% BLEU improvement for speech translation. The method proves particularly effective for speech translation, where RNN-T's strict monotonic alignment hurts performance. Our results demonstrate that the CHAT model offers a practical solution for deploying more capable streaming speech models without sacrificing real-time constraints.
FlexCTC: GPU-powered CTC Beam Decoding With Advanced Contextual Abilities
Aug 13, 2025
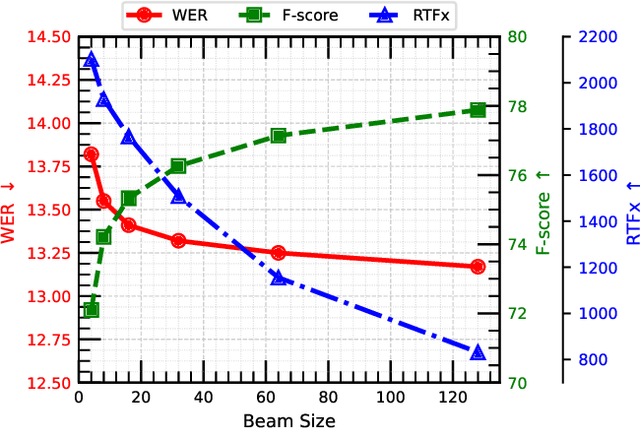


While beam search improves speech recognition quality over greedy decoding, standard implementations are slow, often sequential, and CPU-bound. To fully leverage modern hardware capabilities, we present a novel open-source FlexCTC toolkit for fully GPU-based beam decoding, designed for Connectionist Temporal Classification (CTC) models. Developed entirely in Python and PyTorch, it offers a fast, user-friendly, and extensible alternative to traditional C++, CUDA, or WFST-based decoders. The toolkit features a high-performance, fully batched GPU implementation with eliminated CPU-GPU synchronization and minimized kernel launch overhead via CUDA Graphs. It also supports advanced contextualization techniques, including GPU-powered N-gram language model fusion and phrase-level boosting. These features enable accurate and efficient decoding, making them suitable for both research and production use.
TurboBias: Universal ASR Context-Biasing powered by GPU-accelerated Phrase-Boosting Tree
Aug 12, 2025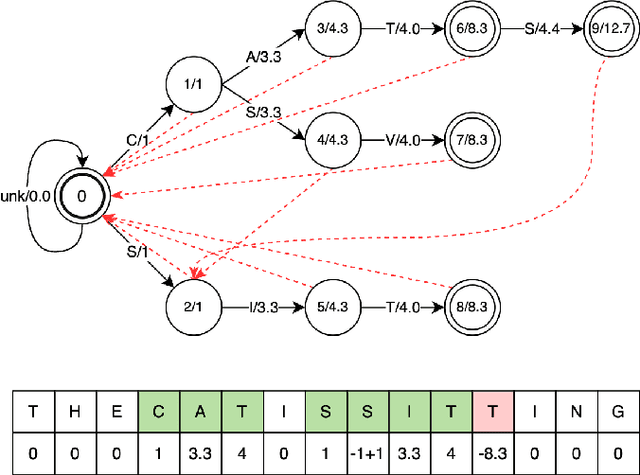
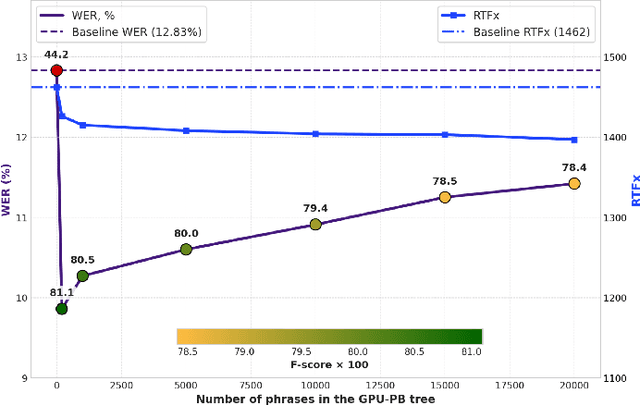
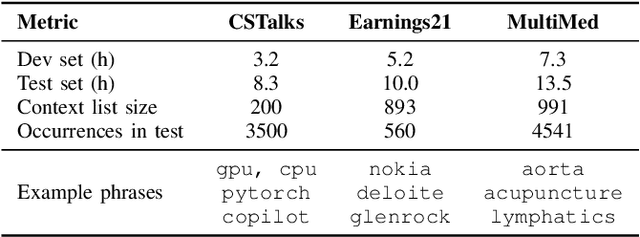
Recognizing specific key phrases is an essential task for contextualized Automatic Speech Recognition (ASR). However, most existing context-biasing approaches have limitations associated with the necessity of additional model training, significantly slow down the decoding process, or constrain the choice of the ASR system type. This paper proposes a universal ASR context-biasing framework that supports all major types: CTC, Transducers, and Attention Encoder-Decoder models. The framework is based on a GPU-accelerated word boosting tree, which enables it to be used in shallow fusion mode for greedy and beam search decoding without noticeable speed degradation, even with a vast number of key phrases (up to 20K items). The obtained results showed high efficiency of the proposed method, surpassing the considered open-source context-biasing approaches in accuracy and decoding speed. Our context-biasing framework is open-sourced as a part of the NeMo toolkit.
NGPU-LM: GPU-Accelerated N-Gram Language Model for Context-Biasing in Greedy ASR Decoding
May 28, 2025Statistical n-gram language models are widely used for context-biasing tasks in Automatic Speech Recognition (ASR). However, existing implementations lack computational efficiency due to poor parallelization, making context-biasing less appealing for industrial use. This work rethinks data structures for statistical n-gram language models to enable fast and parallel operations for GPU-optimized inference. Our approach, named NGPU-LM, introduces customizable greedy decoding for all major ASR model types - including transducers, attention encoder-decoder models, and CTC - with less than 7% computational overhead. The proposed approach can eliminate more than 50% of the accuracy gap between greedy and beam search for out-of-domain scenarios while avoiding significant slowdown caused by beam search. The implementation of the proposed NGPU-LM is open-sourced.
WIND: Accelerated RNN-T Decoding with Windowed Inference for Non-blank Detection
May 19, 2025We propose Windowed Inference for Non-blank Detection (WIND), a novel strategy that significantly accelerates RNN-T inference without compromising model accuracy. During model inference, instead of processing frames sequentially, WIND processes multiple frames simultaneously within a window in parallel, allowing the model to quickly locate non-blank predictions during decoding, resulting in significant speed-ups. We implement WIND for greedy decoding, batched greedy decoding with label-looping techniques, and also propose a novel beam-search decoding method. Experiments on multiple datasets with different conditions show that our method, when operating in greedy modes, speeds up as much as 2.4X compared to the baseline sequential approach while maintaining identical Word Error Rate (WER) performance. Our beam-search algorithm achieves slightly better accuracy than alternative methods, with significantly improved speed. We will open-source our WIND implementation.
RNN-Transducer-based Losses for Speech Recognition on Noisy Targets
Apr 09, 2025Training speech recognition systems on noisy transcripts is a significant challenge in industrial pipelines, where datasets are enormous and ensuring accurate transcription for every instance is difficult. In this work, we introduce novel loss functions to mitigate the impact of transcription errors in RNN-Transducer models. Our Star-Transducer loss addresses deletion errors by incorporating "skip frame" transitions in the loss lattice, restoring over 90% of the system's performance compared to models trained with accurate transcripts. The Bypass-Transducer loss uses "skip token" transitions to tackle insertion errors, recovering more than 60% of the quality. Finally, the Target-Robust Transducer loss merges these approaches, offering robust performance against arbitrary errors. Experimental results demonstrate that the Target-Robust Transducer loss significantly improves RNN-T performance on noisy data by restoring over 70% of the quality compared to well-transcribed data.
TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
Jan 10, 2025This work introduces TTS-Transducer - a novel architecture for text-to-speech, leveraging the strengths of audio codec models and neural transducers. Transducers, renowned for their superior quality and robustness in speech recognition, are employed to learn monotonic alignments and allow for avoiding using explicit duration predictors. Neural audio codecs efficiently compress audio into discrete codes, revealing the possibility of applying text modeling approaches to speech generation. However, the complexity of predicting multiple tokens per frame from several codebooks, as necessitated by audio codec models with residual quantizers, poses a significant challenge. The proposed system first uses a transducer architecture to learn monotonic alignments between tokenized text and speech codec tokens for the first codebook. Next, a non-autoregressive Transformer predicts the remaining codes using the alignment extracted from transducer loss. The proposed system is trained end-to-end. We show that TTS-Transducer is a competitive and robust alternative to contemporary TTS systems.
Three-in-One: Fast and Accurate Transducer for Hybrid-Autoregressive ASR
Oct 03, 2024



We present \textbf{H}ybrid-\textbf{A}utoregressive \textbf{IN}ference Tr\textbf{AN}sducers (HAINAN), a novel architecture for speech recognition that extends the Token-and-Duration Transducer (TDT) model. Trained with randomly masked predictor network outputs, HAINAN supports both autoregressive inference with all network components and non-autoregressive inference without the predictor. Additionally, we propose a novel semi-autoregressive inference paradigm that first generates an initial hypothesis using non-autoregressive inference, followed by refinement steps where each token prediction is regenerated using parallelized autoregression on the initial hypothesis. Experiments on multiple datasets across different languages demonstrate that HAINAN achieves efficiency parity with CTC in non-autoregressive mode and with TDT in autoregressive mode. In terms of accuracy, autoregressive HAINAN outperforms TDT and RNN-T, while non-autoregressive HAINAN significantly outperforms CTC. Semi-autoregressive inference further enhances the model's accuracy with minimal computational overhead, and even outperforms TDT results in some cases. These results highlight HAINAN's flexibility in balancing accuracy and speed, positioning it as a strong candidate for real-world speech recognition applications.
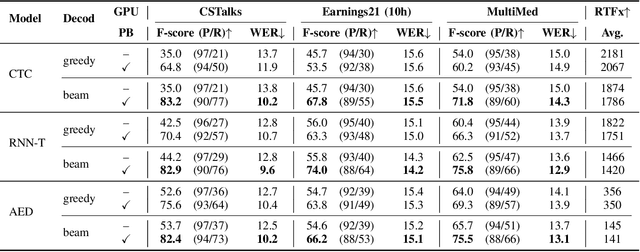
Fast Context-Biasing for CTC and Transducer ASR models with CTC-based Word Spotter
Jun 11, 2024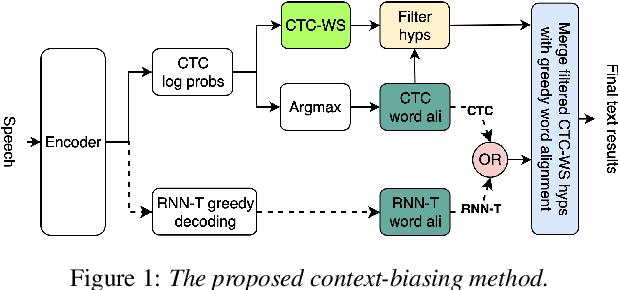
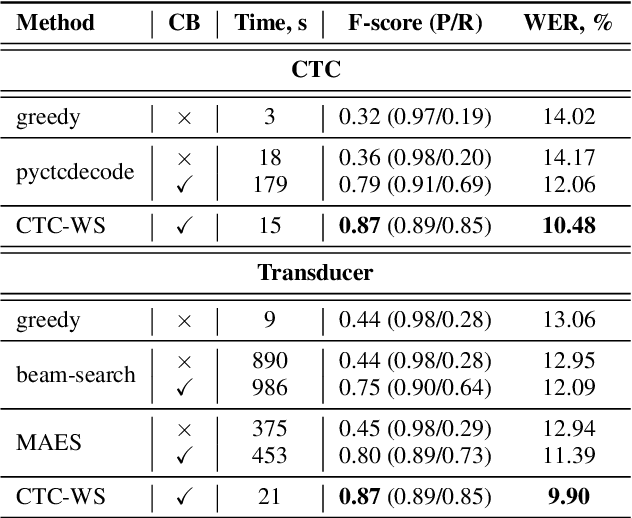
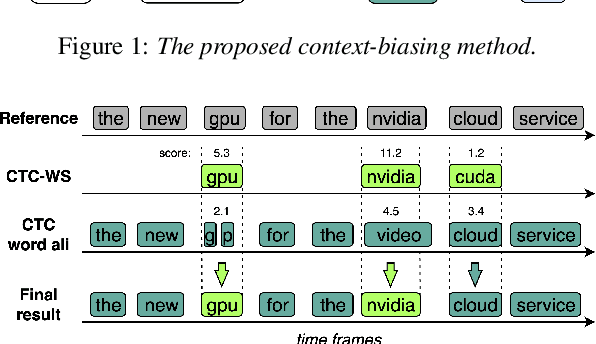
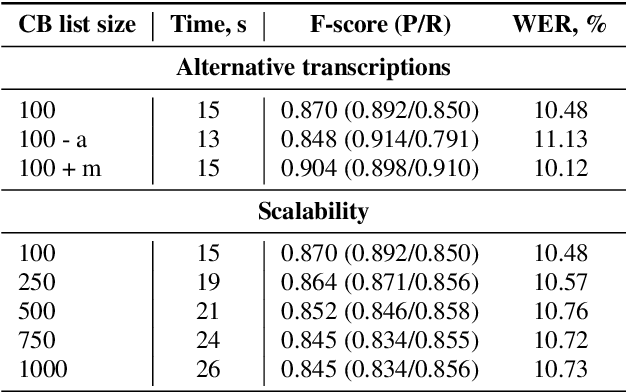
Accurate recognition of rare and new words remains a pressing problem for contextualized Automatic Speech Recognition (ASR) systems. Most context-biasing methods involve modification of the ASR model or the beam-search decoding algorithm, complicating model reuse and slowing down inference. This work presents a new approach to fast context-biasing with CTC-based Word Spotter (CTC-WS) for CTC and Transducer (RNN-T) ASR models. The proposed method matches CTC log-probabilities against a compact context graph to detect potential context-biasing candidates. The valid candidates then replace their greedy recognition counterparts in corresponding frame intervals. A Hybrid Transducer-CTC model enables the CTC-WS application for the Transducer model. The results demonstrate a significant acceleration of the context-biasing recognition with a simultaneous improvement in F-score and WER compared to baseline methods. The proposed method is publicly available in the NVIDIA NeMo toolkit.
Label-Looping: Highly Efficient Decoding for Transducers
Jun 10, 2024



This paper introduces a highly efficient greedy decoding algorithm for Transducer inference. We propose a novel data structure using CUDA tensors to represent partial hypotheses in a batch that supports parallelized hypothesis manipulations. During decoding, our algorithm maximizes GPU parallelism by adopting a nested-loop design, where the inner loop consumes all blank predictions, while non-blank predictions are handled in the outer loop. Our algorithm is general-purpose and can work with both conventional Transducers and Token-and-Duration Transducers. Experiments show that the label-looping algorithm can bring a speedup up to 2.0X compared to conventional batched decoding algorithms when using batch size 32, and can be combined with other compiler or GPU call-related techniques to bring more speedup. We will open-source our implementation to benefit the research community.