 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed of Light Exact Greedy Decoding for RNN-T Speech Recognition Models on GPU
Paper and Code
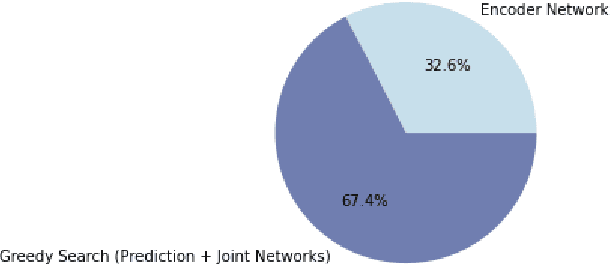
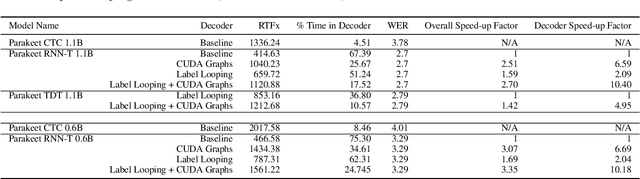

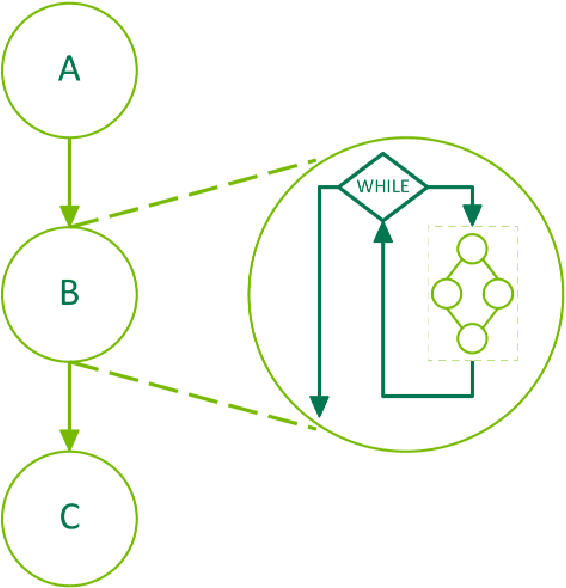
The vast majority of inference time for RNN Transducer (RNN-T) models today is spent on decoding. Current state-of-the-art RNN-T decoding implementations leave the GPU idle ~80% of the time. Leveraging a new CUDA 12.4 feature, CUDA graph conditional nodes, we present an exact GPU-based implementation of greedy decoding for RNN-T models that eliminates this idle time. Our optimizations speed up a 1.1 billion parameter RNN-T model end-to-end by a factor of 2.5x. This technique can applied to the "label looping" alternative greedy decoding algorithm as well, achieving 1.7x and 1.4x end-to-end speedups when applied to 1.1 billion parameter RNN-T and Token and Duration Transducer models respectively. This work enables a 1.1 billion parameter RNN-T model to run only 16% slower than a similarly sized CTC model, contradicting the common belief that RNN-T models are not suitable for high throughput inference. The implementation is available in NVIDIA NeMo.