 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Codecs: Spectrogram-Based Audio Codecs for High Quality Speech Synthesis
Paper and Code
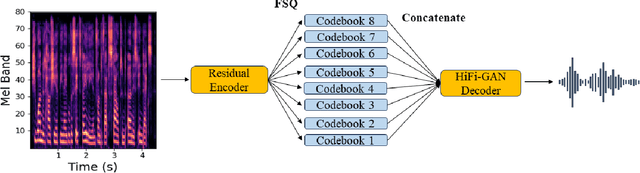

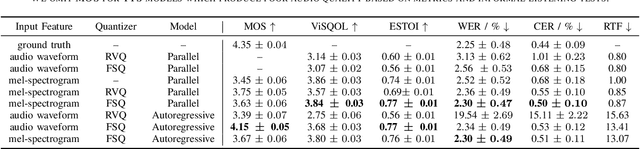
Historically, most speech models in machine-learning have used the mel-spectrogram as a speech representation. Recently, discrete audio tokens produced by neural audio codecs have become a popular alternate speech representation for speech synthesis tasks such as text-to-speech (TTS). However, the data distribution produced by such codecs is too complex for some TTS models to predict, hence requiring large autoregressive models to get reasonable quality. Typical audio codecs compress and reconstruct the time-domain audio signal. We propose a spectral codec which compresses the mel-spectrogram and reconstructs the time-domain audio signal. A study of objective audio quality metrics suggests that our spectral codec has comparable perceptual quality to equivalent audio codecs. Furthermore, non-autoregressive TTS models trained with the proposed spectral codec generate audio with significantly higher quality than when trained with mel-spectrograms or audio codecs.