 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
Feb 07, 2025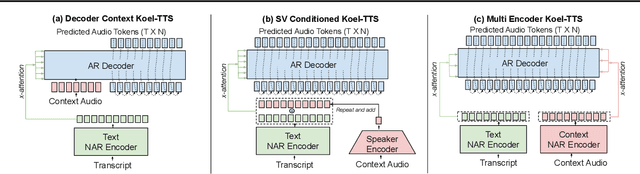
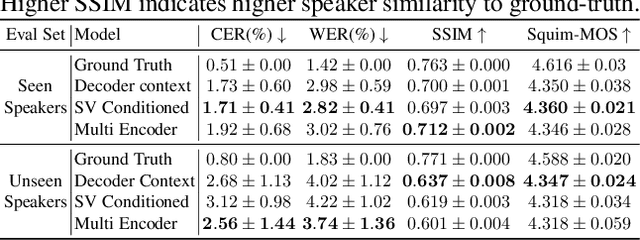
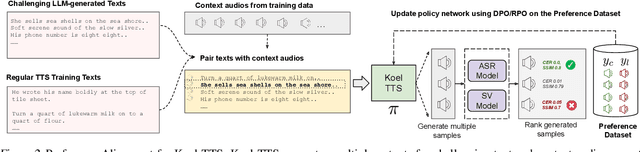
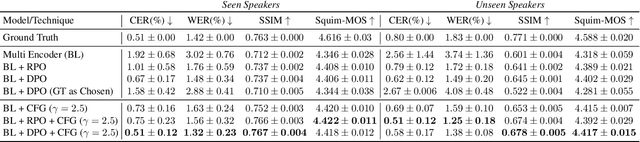
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
Object-based reasoning in VQA
Jan 29, 2018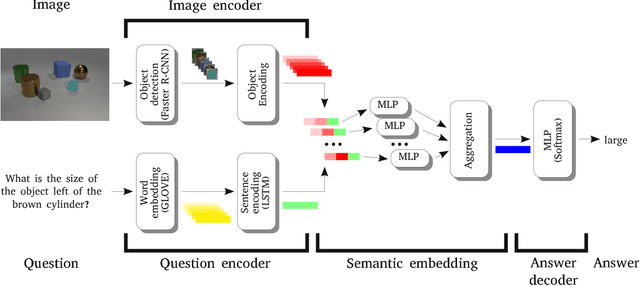
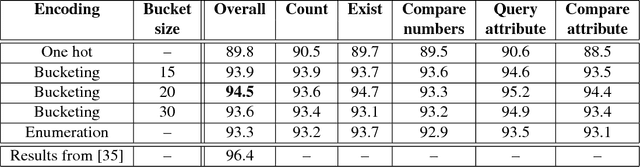
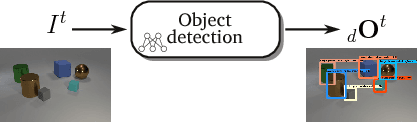
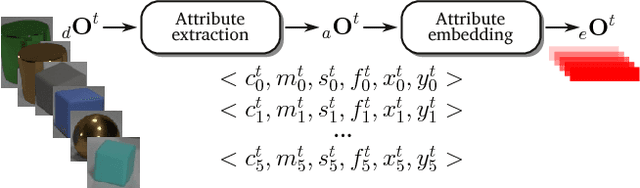
Visual Question Answering (VQA) is a novel problem domain where multi-modal inputs must be processed in order to solve the task given in the form of a natural language. As the solutions inherently require to combine visual and natural language processing with abstract reasoning, the problem is considered as AI-complete. Recent advances indicate that using high-level, abstract facts extracted from the inputs might facilitate reasoning. Following that direction we decided to develop a solution combining state-of-the-art object detection and reasoning modules. The results, achieved on the well-balanced CLEVR dataset, confirm the promises and show significant, few percent improvements of accuracy on the complex "counting" task.