 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Fake Reviewer Groups in Dynamic Networks: An Adaptive Graph Learning Method
Mar 09, 2026The proliferation of fake reviews, often produced by organized groups, undermines consumer trust and fair competition on online platforms. These groups employ sophisticated strategies that evade traditional detection methods, particularly in cold-start scenarios involving newly launched products with sparse data. To address this, we propose the \underline{D}iversity- and \underline{S}imilarity-aware \underline{D}ynamic \underline{G}raph \underline{A}ttention-enhanced \underline{G}raph \underline{C}onvolutional \underline{N}etwork (DS-DGA-GCN), a new graph learning model for detecting fake reviewer groups. DS-DGA-GCN achieves robust detection since it focuses on the joint relationships among products, reviews, and reviewers by modeling product-review-reviewer networks. DS-DGA-GCN also achieves adaptive detection by integrating a Network Feature Scoring (NFS) system and a new dynamic graph attention mechanism. The NFS system quantifies network attributes, including neighbor diversity, network self-similarity, as a unified feature score. The dynamic graph attention mechanism improves the adaptability and computational efficiency by captures features related to temporal information, node importance, and global network structure. Extensive experiments conducted on two real-world datasets derived from Amazon and Xiaohongshu demonstrate that DS-DGA-GCN significantly outperforms state-of-the-art baselines, achieving accuracies of up to \textbf{89.8\% and 88.3\%}, respectively.
RU4D-SLAM: Reweighting Uncertainty in Gaussian Splatting SLAM for 4D Scene Reconstruction
Feb 24, 2026Combining 3D Gaussian splatting with Simultaneous Localization and Mapping (SLAM) has gained popularity as it enables continuous 3D environment reconstruction during motion. However, existing methods struggle in dynamic environments, particularly moving objects complicate 3D reconstruction and, in turn, hinder reliable tracking. The emergence of 4D reconstruction, especially 4D Gaussian splatting, offers a promising direction for addressing these challenges, yet its potential for 4D-aware SLAM remains largely underexplored. Along this direction, we propose a robust and efficient framework, namely Reweighting Uncertainty in Gaussian Splatting SLAM (RU4D-SLAM) for 4D scene reconstruction, that introduces temporal factors into spatial 3D representation while incorporating uncertainty-aware perception of scene changes, blurred image synthesis, and dynamic scene reconstruction. We enhance dynamic scene representation by integrating motion blur rendering, and improve uncertainty-aware tracking by extending per-pixel uncertainty modeling, which is originally designed for static scenarios, to handle blurred images. Furthermore, we propose a semantic-guided reweighting mechanism for per-pixel uncertainty estimation in dynamic scenes, and introduce a learnable opacity weight to support adaptive 4D mapping. Extensive experiments on standard benchmarks demonstrate that our method substantially outperforms state-of-the-art approaches in both trajectory accuracy and 4D scene reconstruction, particularly in dynamic environments with moving objects and low-quality inputs. Code available: https://ru4d-slam.github.io
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
Generalization and Risk Bounds for Recurrent Neural Networks
Nov 05, 2024Recurrent Neural Networks (RNNs) have achieved great success in the prediction of sequential data. However, their theoretical studies are still lagging behind because of their complex interconnected structures. In this paper, we establish a new generalization error bound for vanilla RNNs, and provide a unified framework to calculate the Rademacher complexity that can be applied to a variety of loss functions. When the ramp loss is used, we show that our bound is tighter than the existing bounds based on the same assumptions on the Frobenius and spectral norms of the weight matrices and a few mild conditions. Our numerical results show that our new generalization bound is the tightest among all existing bounds in three public datasets. Our bound improves the second tightest one by an average percentage of 13.80% and 3.01% when the $\tanh$ and ReLU activation functions are used, respectively. Moreover, we derive a sharp estimation error bound for RNN-based estimators obtained through empirical risk minimization (ERM) in multi-class classification problems when the loss function satisfies a Bernstein condition.
SleepEGAN: A GAN-enhanced Ensemble Deep Learning Model for Imbalanced Classification of Sleep Stages
Jul 04, 2023



Deep neural networks have played an important role in automatic sleep stage classification because of their strong representation and in-model feature transformation abilities. However, class imbalance and individual heterogeneity which typically exist in raw EEG signals of sleep data can significantly affect the classification performance of any machine learning algorithms. To solve these two problems, this paper develops a generative adversarial network (GAN)-powered ensemble deep learning model, named SleepEGAN, for the imbalanced classification of sleep stages. To alleviate class imbalance, we propose a new GAN (called EGAN) architecture adapted to the features of EEG signals for data augmentation. The generated samples for the minority classes are used in the training process. In addition, we design a cost-free ensemble learning strategy to reduce the model estimation variance caused by the heterogeneity between the validation and test sets, so as to enhance the accuracy and robustness of prediction performance. We show that the proposed method can improve classification accuracy compared to several existing state-of-the-art methods using three public sleep datasets.
Multi-Projection Fusion and Refinement Network for Salient Object Detection in 360° Omnidirectional Image
Dec 23, 2022
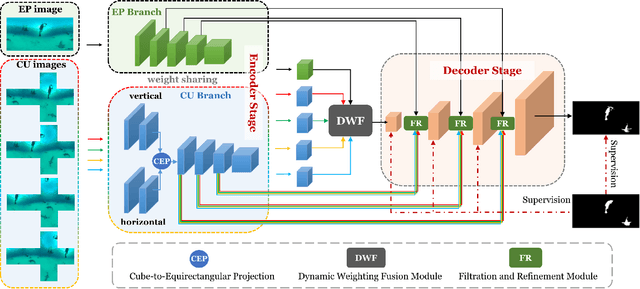
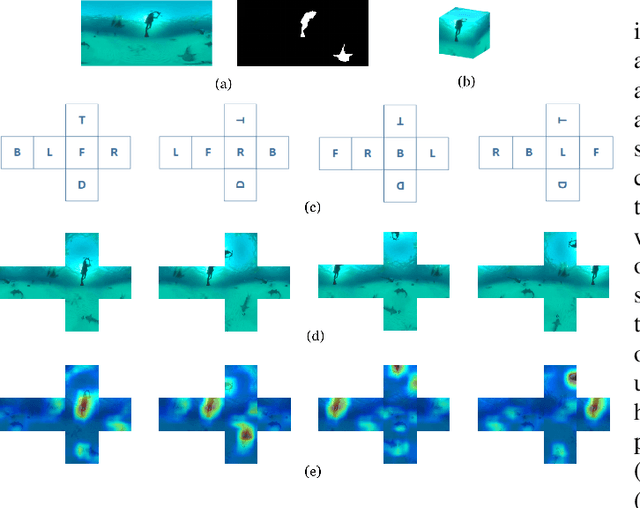
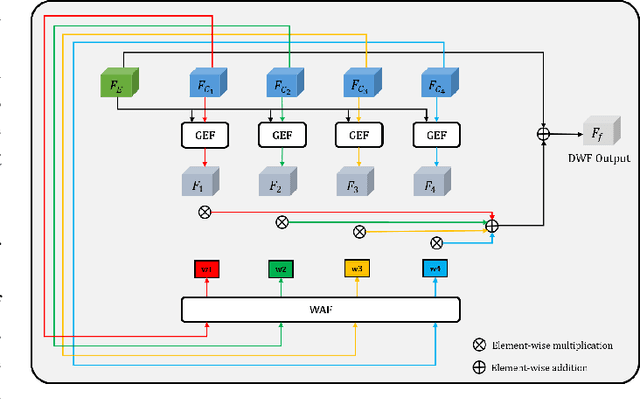
Salient object detection (SOD) aims to determine the most visually attractive objects in an image. With the development of virtual reality technology, 360{\deg} omnidirectional image has been widely used, but the SOD task in 360{\deg} omnidirectional image is seldom studied due to its severe distortions and complex scenes. In this paper, we propose a Multi-Projection Fusion and Refinement Network (MPFR-Net) to detect the salient objects in 360{\deg} omnidirectional image. Different from the existing methods, the equirectangular projection image and four corresponding cube-unfolding images are embedded into the network simultaneously as inputs, where the cube-unfolding images not only provide supplementary information for equirectangular projection image, but also ensure the object integrity of the cube-map projection. In order to make full use of these two projection modes, a Dynamic Weighting Fusion (DWF) module is designed to adaptively integrate the features of different projections in a complementary and dynamic manner from the perspective of inter and intra features. Furthermore, in order to fully explore the way of interaction between encoder and decoder features, a Filtration and Refinement (FR) module is designed to suppress the redundant information between the feature itself and the feature. Experimental results on two omnidirectional datasets demonstrate that the proposed approach outperforms the state-of-the-art methods both qualitatively and quantitatively.
zPROBE: Zero Peek Robustness Checks for Federated Learning
Jun 24, 2022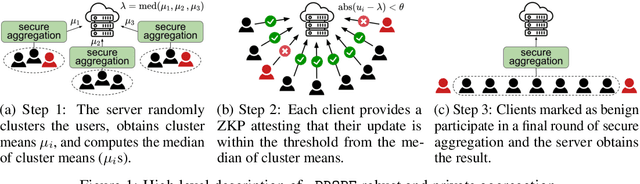
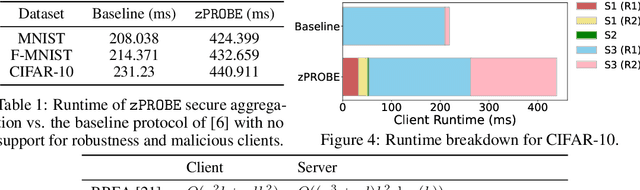
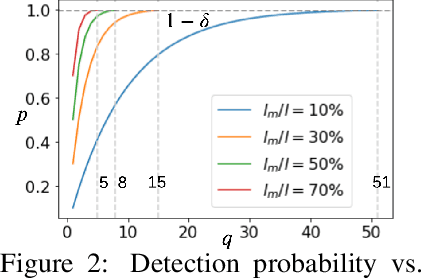
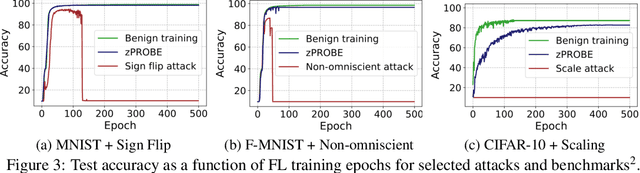
Privacy-preserving federated learning allows multiple users to jointly train a model with coordination of a central server. The server only learns the final aggregation result, thereby preventing leakage of the users' (private) training data from the individual model updates. However, keeping the individual updates private allows malicious users to perform Byzantine attacks and degrade the model accuracy without being detected. Best existing defenses against Byzantine workers rely on robust rank-based statistics, e.g., the median, to find malicious updates. However, implementing privacy-preserving rank-based statistics is nontrivial and unscalable in the secure domain, as it requires sorting of all individual updates. We establish the first private robustness check that uses high break point rank-based statistics on aggregated model updates. By exploiting randomized clustering, we significantly improve the scalability of our defense without compromising privacy. We leverage the derived statistical bounds in zero-knowledge proofs to detect and remove malicious updates without revealing the private user updates. Our novel framework, zPROBE, enables Byzantine resilient and secure federated learning. Empirical evaluations demonstrate that zPROBE provides a low overhead solution to defend against state-of-the-art Byzantine attacks while preserving privacy.
AdaTest:Reinforcement Learning and Adaptive Sampling for On-chip Hardware Trojan Detection
Apr 12, 2022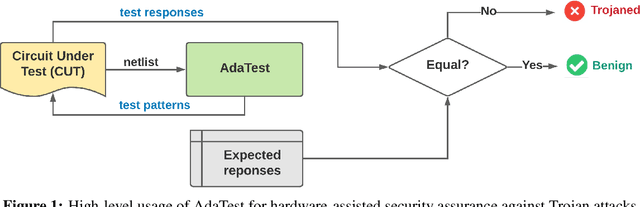
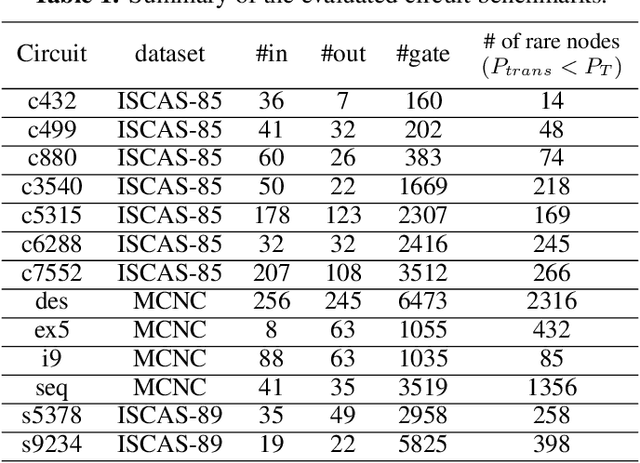
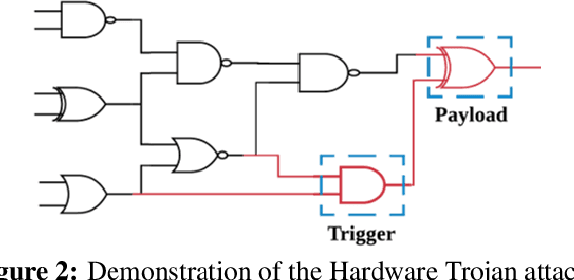
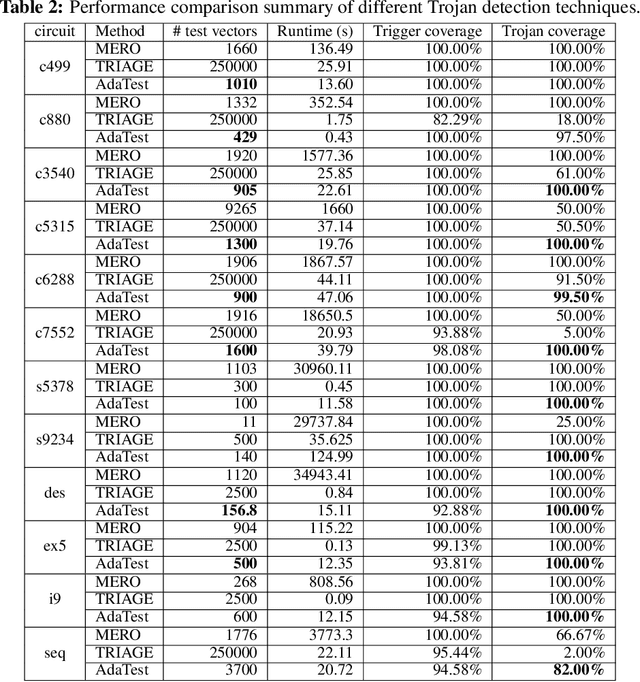
This paper proposes AdaTest, a novel adaptive test pattern generation framework for efficient and reliable Hardware Trojan (HT) detection. HT is a backdoor attack that tampers with the design of victim integrated circuits (ICs). AdaTest improves the existing HT detection techniques in terms of scalability and accuracy of detecting smaller Trojans in the presence of noise and variations. To achieve high trigger coverage, AdaTest leverages Reinforcement Learning (RL) to produce a diverse set of test inputs. Particularly, we progressively generate test vectors with high reward values in an iterative manner. In each iteration, the test set is evaluated and adaptively expanded as needed. Furthermore, AdaTest integrates adaptive sampling to prioritize test samples that provide more information for HT detection, thus reducing the number of samples while improving the sample quality for faster exploration. We develop AdaTest with a Software/Hardware co-design principle and provide an optimized on-chip architecture solution. AdaTest's architecture minimizes the hardware overhead in two ways:(i) Deploying circuit emulation on programmable hardware to accelerate reward evaluation of the test input; (ii) Pipelining each computation stage in AdaTest by automatically constructing auxiliary circuit for test input generation, reward evaluation, and adaptive sampling. We evaluate AdaTest's performance on various HT benchmarks and compare it with two prior works that use logic testing for HT detection. Experimental results show that AdaTest engenders up to two orders of test generation speedup and two orders of test set size reduction compared to the prior works while achieving the same level or higher Trojan detection rate.
An Adaptive Black-box Backdoor Detection Method for Deep Neural Networks
Apr 08, 2022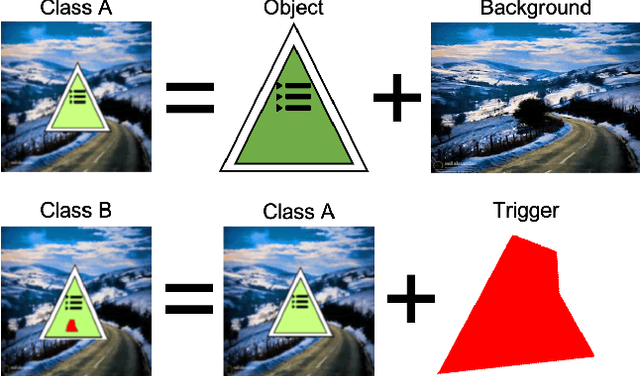

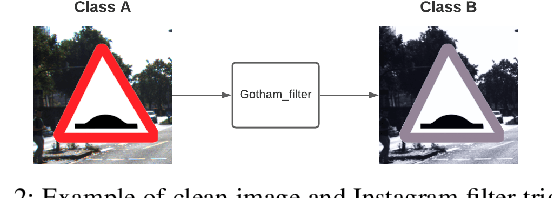

With the surge of Machine Learning (ML), An emerging amount of intelligent applications have been developed. Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by stealthy triggers. In this paper, we target to design a robust and adaptive Trojan detection scheme that inspects whether a pre-trained model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose the first trigger approximation based black-box Trojan detection framework that enables a fast and scalable search of the trigger in the input space. Furthermore, our approach can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of our approach across various datasets and ML models. Empirical results show that our approach achieves a ROC-AUC score of 0.93 on the public TrojAI dataset. Our code can be found at https://github.com/xinqiaozhang/adatrojan