 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastStamp: Accelerating Neural Steganography and Digital Watermarking of Images on FPGAs
Sep 26, 2022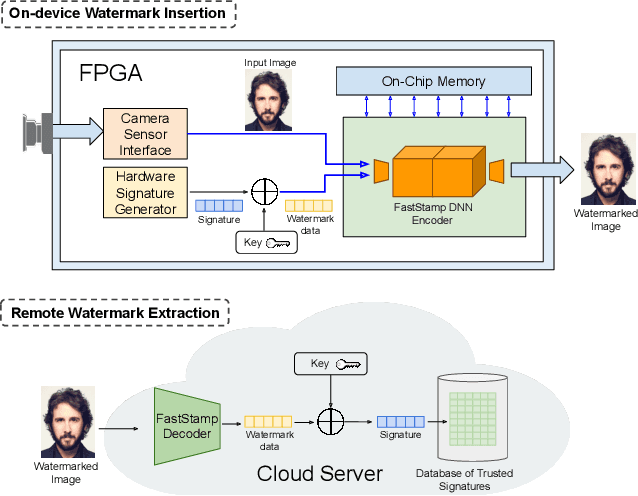

Steganography and digital watermarking are the tasks of hiding recoverable data in image pixels. Deep neural network (DNN) based image steganography and watermarking techniques are quickly replacing traditional hand-engineered pipelines. DNN based watermarking techniques have drastically improved the message capacity, imperceptibility and robustness of the embedded watermarks. However, this improvement comes at the cost of increased computational overhead of the watermark encoder neural network. In this work, we design the first accelerator platform FastStamp to perform DNN based steganography and digital watermarking of images on hardware. We first propose a parameter efficient DNN model for embedding recoverable bit-strings in image pixels. Our proposed model can match the success metrics of prior state-of-the-art DNN based watermarking methods while being significantly faster and lighter in terms of memory footprint. We then design an FPGA based accelerator framework to further improve the model throughput and power consumption by leveraging data parallelism and customized computation paths. FastStamp allows embedding hardware signatures into images to establish media authenticity and ownership of digital media. Our best design achieves 68 times faster inference as compared to GPU implementations of prior DNN based watermark encoder while consuming less power.
zPROBE: Zero Peek Robustness Checks for Federated Learning
Jun 24, 2022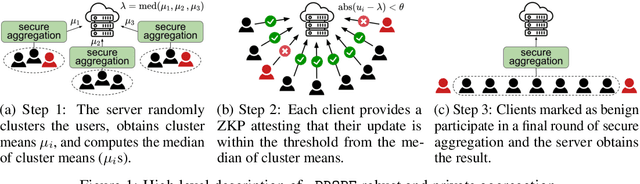
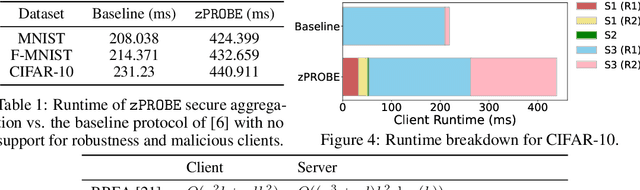
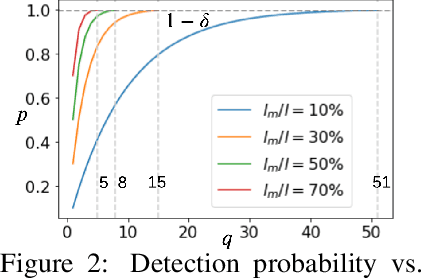
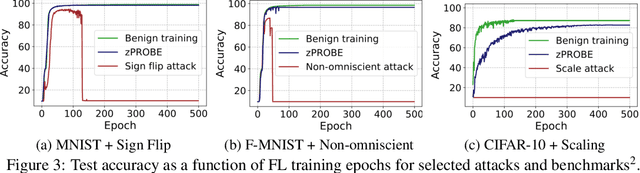
Privacy-preserving federated learning allows multiple users to jointly train a model with coordination of a central server. The server only learns the final aggregation result, thereby preventing leakage of the users' (private) training data from the individual model updates. However, keeping the individual updates private allows malicious users to perform Byzantine attacks and degrade the model accuracy without being detected. Best existing defenses against Byzantine workers rely on robust rank-based statistics, e.g., the median, to find malicious updates. However, implementing privacy-preserving rank-based statistics is nontrivial and unscalable in the secure domain, as it requires sorting of all individual updates. We establish the first private robustness check that uses high break point rank-based statistics on aggregated model updates. By exploiting randomized clustering, we significantly improve the scalability of our defense without compromising privacy. We leverage the derived statistical bounds in zero-knowledge proofs to detect and remove malicious updates without revealing the private user updates. Our novel framework, zPROBE, enables Byzantine resilient and secure federated learning. Empirical evaluations demonstrate that zPROBE provides a low overhead solution to defend against state-of-the-art Byzantine attacks while preserving privacy.
AdaTest:Reinforcement Learning and Adaptive Sampling for On-chip Hardware Trojan Detection
Apr 12, 2022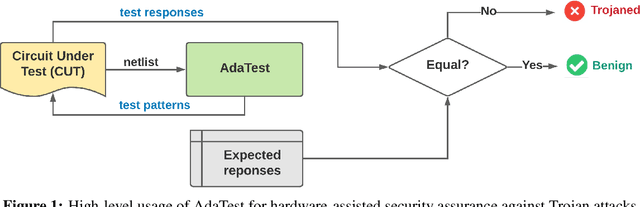
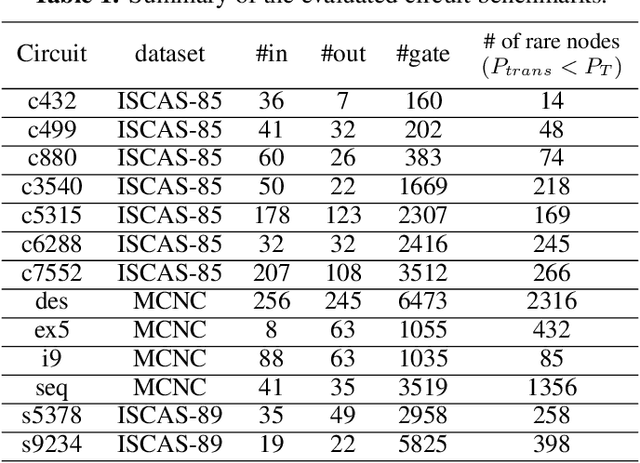
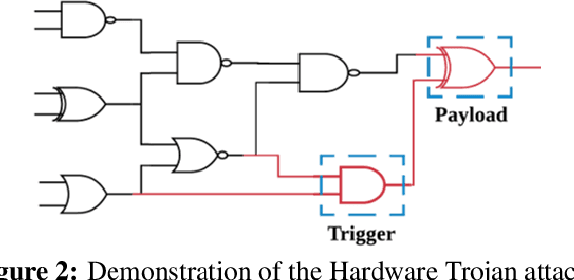
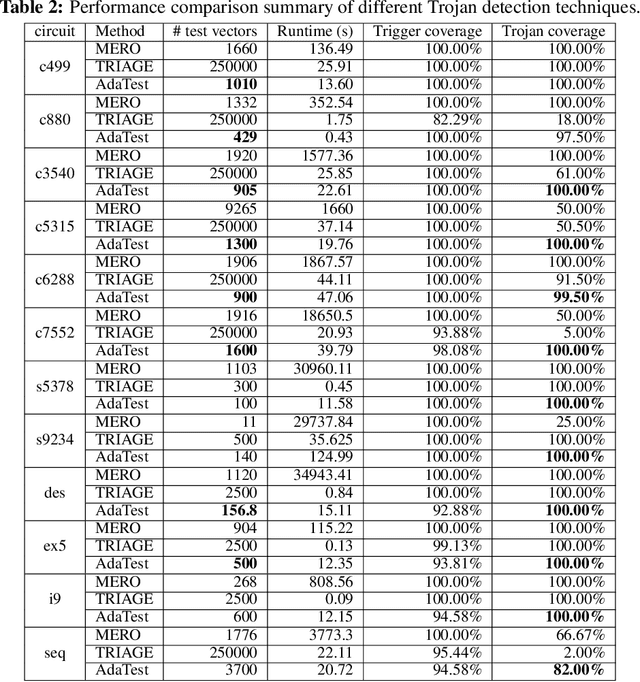
This paper proposes AdaTest, a novel adaptive test pattern generation framework for efficient and reliable Hardware Trojan (HT) detection. HT is a backdoor attack that tampers with the design of victim integrated circuits (ICs). AdaTest improves the existing HT detection techniques in terms of scalability and accuracy of detecting smaller Trojans in the presence of noise and variations. To achieve high trigger coverage, AdaTest leverages Reinforcement Learning (RL) to produce a diverse set of test inputs. Particularly, we progressively generate test vectors with high reward values in an iterative manner. In each iteration, the test set is evaluated and adaptively expanded as needed. Furthermore, AdaTest integrates adaptive sampling to prioritize test samples that provide more information for HT detection, thus reducing the number of samples while improving the sample quality for faster exploration. We develop AdaTest with a Software/Hardware co-design principle and provide an optimized on-chip architecture solution. AdaTest's architecture minimizes the hardware overhead in two ways:(i) Deploying circuit emulation on programmable hardware to accelerate reward evaluation of the test input; (ii) Pipelining each computation stage in AdaTest by automatically constructing auxiliary circuit for test input generation, reward evaluation, and adaptive sampling. We evaluate AdaTest's performance on various HT benchmarks and compare it with two prior works that use logic testing for HT detection. Experimental results show that AdaTest engenders up to two orders of test generation speedup and two orders of test set size reduction compared to the prior works while achieving the same level or higher Trojan detection rate.
An Adaptive Black-box Backdoor Detection Method for Deep Neural Networks
Apr 08, 2022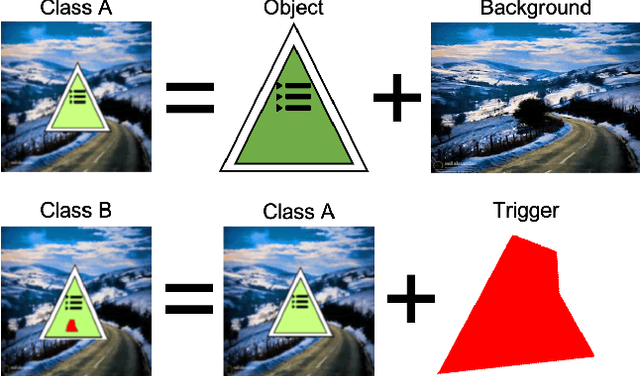


With the surge of Machine Learning (ML), An emerging amount of intelligent applications have been developed. Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by stealthy triggers. In this paper, we target to design a robust and adaptive Trojan detection scheme that inspects whether a pre-trained model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose the first trigger approximation based black-box Trojan detection framework that enables a fast and scalable search of the trigger in the input space. Furthermore, our approach can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of our approach across various datasets and ML models. Empirical results show that our approach achieves a ROC-AUC score of 0.93 on the public TrojAI dataset. Our code can be found at https://github.com/xinqiaozhang/adatrojan
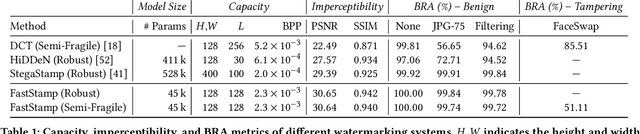
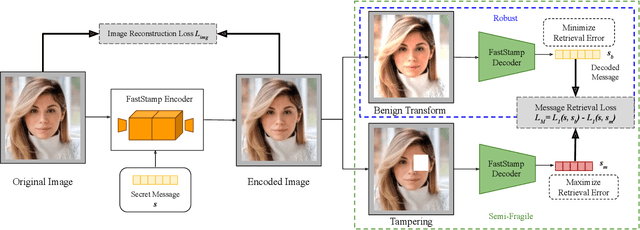
FaceSigns: Semi-Fragile Neural Watermarks for Media Authentication and Countering Deepfakes
Apr 05, 2022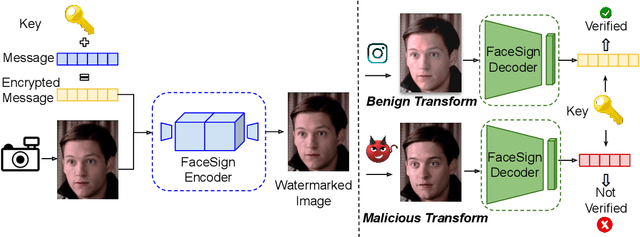
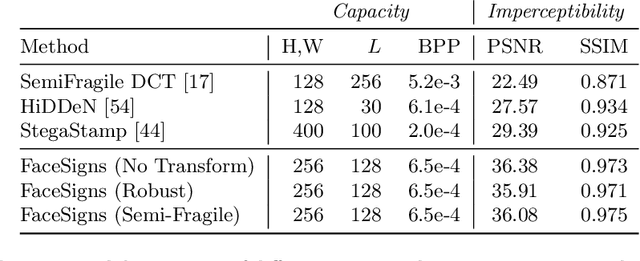
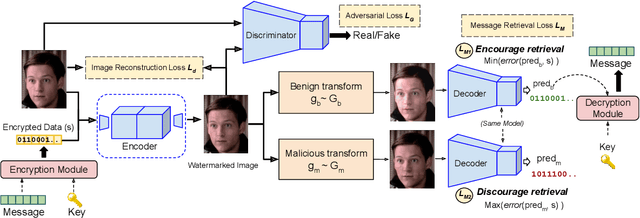
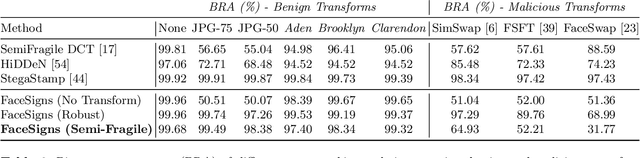
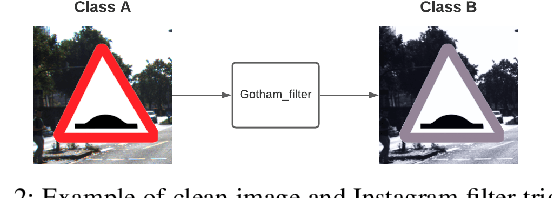
Deepfakes and manipulated media are becoming a prominent threat due to the recent advances in realistic image and video synthesis techniques. There have been several attempts at combating Deepfakes using machine learning classifiers. However, such classifiers do not generalize well to black-box image synthesis techniques and have been shown to be vulnerable to adversarial examples. To address these challenges, we introduce a deep learning based semi-fragile watermarking technique that allows media authentication by verifying an invisible secret message embedded in the image pixels. Instead of identifying and detecting fake media using visual artifacts, we propose to proactively embed a semi-fragile watermark into a real image so that we can prove its authenticity when needed. Our watermarking framework is designed to be fragile to facial manipulations or tampering while being robust to benign image-processing operations such as image compression, scaling, saturation, contrast adjustments etc. This allows images shared over the internet to retain the verifiable watermark as long as face-swapping or any other Deepfake modification technique is not applied. We demonstrate that FaceSigns can embed a 128 bit secret as an imperceptible image watermark that can be recovered with a high bit recovery accuracy at several compression levels, while being non-recoverable when unseen Deepfake manipulations are applied. For a set of unseen benign and Deepfake manipulations studied in our work, FaceSigns can reliably detect manipulated content with an AUC score of 0.996 which is significantly higher than prior image watermarking and steganography techniques.
TAD: Trigger Approximation based Black-box Trojan Detection for AI
Feb 24, 2021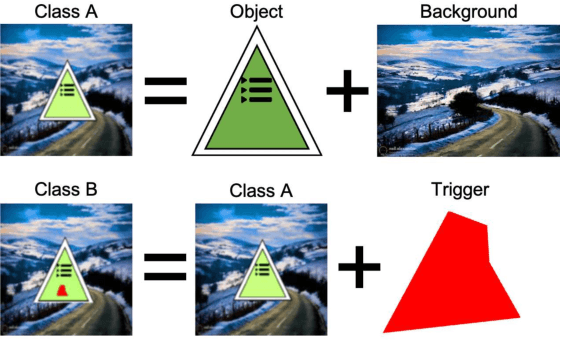

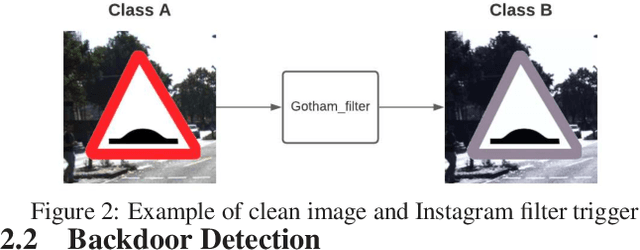
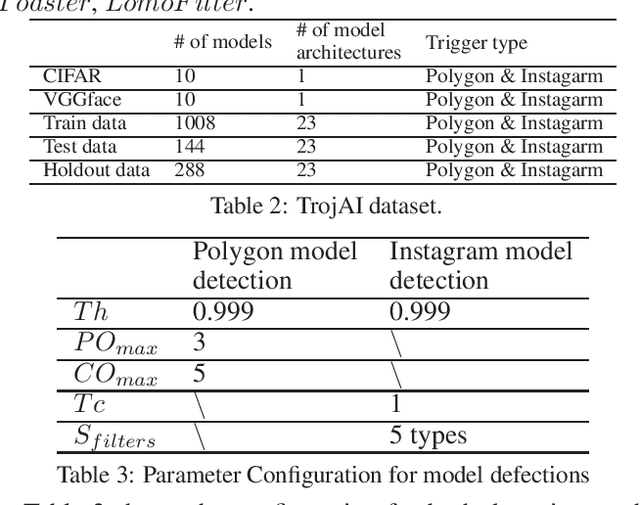
An emerging amount of intelligent applications have been developed with the surge of Machine Learning (ML). Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by the stealthy trigger. We call this vulnerable model adversarial artificial intelligence (AI). In this paper, we target to design a robust Trojan detection scheme that inspects whether a pre-trained AI model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose TAD, the first trigger approximation based Trojan detection framework that enables fast and scalable search of the trigger in the input space. Furthermore, TAD can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of the TAD across various datasets and ML models. Empirical results show that TAD achieves a ROC-AUC score of 0:91 on the public TrojAI dataset 1 and the average detection time per model is 7:1 minutes.