 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Mamba-SAM Architecture for Efficient 3D Medical Image Segmentation
Jan 31, 2026Accurate segmentation of 3D medical images such as MRI and CT is essential for clinical diagnosis and treatment planning. Foundation models like the Segment Anything Model (SAM) provide powerful general-purpose representations but struggle in medical imaging due to domain shift, their inherently 2D design, and the high computational cost of fine-tuning. To address these challenges, we propose Mamba-SAM, a novel and efficient hybrid architecture that combines a frozen SAM encoder with the linear-time efficiency and long-range modeling capabilities of Mamba-based State Space Models (SSMs). We investigate two parameter-efficient adaptation strategies. The first is a dual-branch architecture that explicitly fuses general features from a frozen SAM encoder with domain-specific representations learned by a trainable VMamba encoder using cross-attention. The second is an adapter-based approach that injects lightweight, 3D-aware Tri-Plane Mamba (TPMamba) modules into the frozen SAM ViT encoder to implicitly model volumetric context. Within this framework, we introduce Multi-Frequency Gated Convolution (MFGC), which enhances feature representation by jointly analyzing spatial and frequency-domain information via 3D discrete cosine transforms and adaptive gating. Extensive experiments on the ACDC cardiac MRI dataset demonstrate the effectiveness of the proposed methods. The dual-branch Mamba-SAM-Base model achieves a mean Dice score of 0.906, comparable to UNet++ (0.907), while outperforming all baselines on Myocardium (0.910) and Left Ventricle (0.971) segmentation. The adapter-based TP MFGC variant offers superior inference speed (4.77 FPS) with strong accuracy (0.880 Dice). These results show that hybridizing foundation models with efficient SSM-based architectures provides a practical and effective solution for 3D medical image segmentation.
AgileNet: Lightweight Dictionary-based Few-shot Learning
May 21, 2018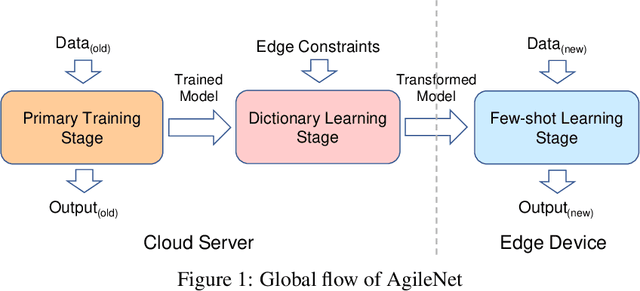
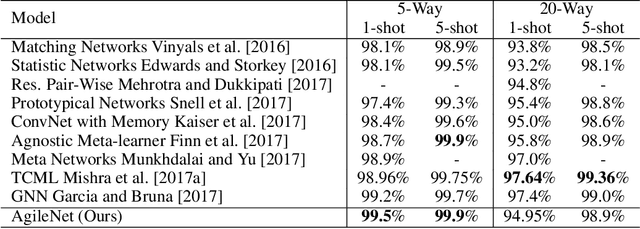
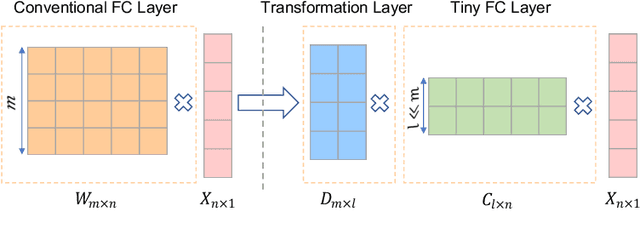
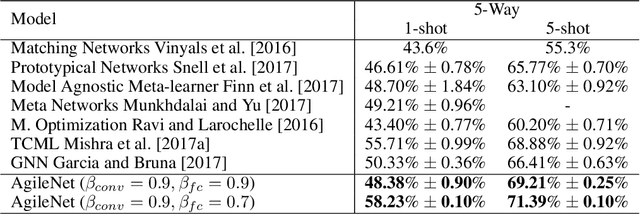
The success of deep learning models is heavily tied to the use of massive amount of labeled data and excessively long training time. With the emergence of intelligent edge applications that use these models, the critical challenge is to obtain the same inference capability on a resource-constrained device while providing adaptability to cope with the dynamic changes in the data. We propose AgileNet, a novel lightweight dictionary-based few-shot learning methodology which provides reduced complexity deep neural network for efficient execution at the edge while enabling low-cost updates to capture the dynamics of the new data. Evaluations of state-of-the-art few-shot learning benchmarks demonstrate the superior accuracy of AgileNet compared to prior arts. Additionally, AgileNet is the first few-shot learning approach that prevents model updates by eliminating the knowledge obtained from the primary training. This property is ensured through the dictionaries learned by our novel end-to-end structured decomposition, which also reduces the memory footprint and computation complexity to match the edge device constraints.
ReBNet: Residual Binarized Neural Network
Mar 27, 2018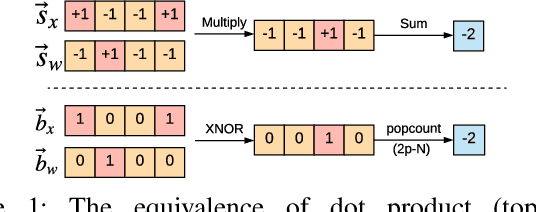

This paper proposes ReBNet, an end-to-end framework for training reconfigurable binary neural networks on software and developing efficient accelerators for execution on FPGA. Binary neural networks offer an intriguing opportunity for deploying large-scale deep learning models on resource-constrained devices. Binarization reduces the memory footprint and replaces the power-hungry matrix-multiplication with light-weight XnorPopcount operations. However, binary networks suffer from a degraded accuracy compared to their fixed-point counterparts. We show that the state-of-the-art methods for optimizing binary networks accuracy, significantly increase the implementation cost and complexity. To compensate for the degraded accuracy while adhering to the simplicity of binary networks, we devise the first reconfigurable scheme that can adjust the classification accuracy based on the application. Our proposition improves the classification accuracy by representing features with multiple levels of residual binarization. Unlike previous methods, our approach does not exacerbate the area cost of the hardware accelerator. Instead, it provides a tradeoff between throughput and accuracy while the area overhead of multi-level binarization is negligible.