 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaled-Time-Attention Robust Edge Network
Jul 09, 2021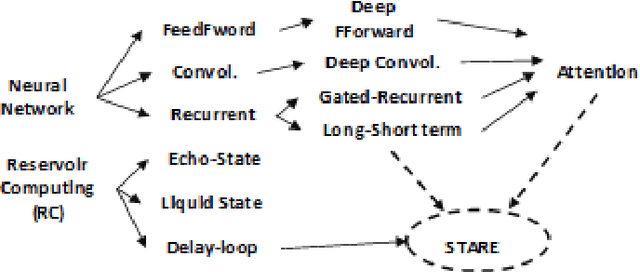
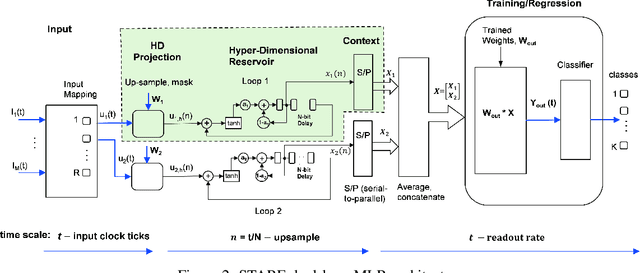
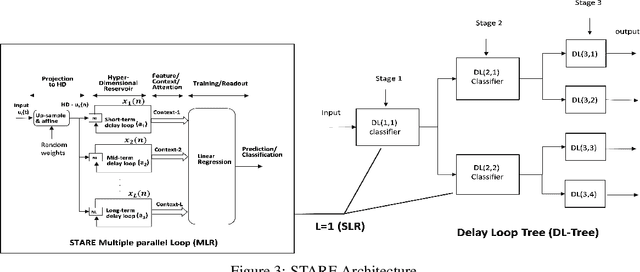
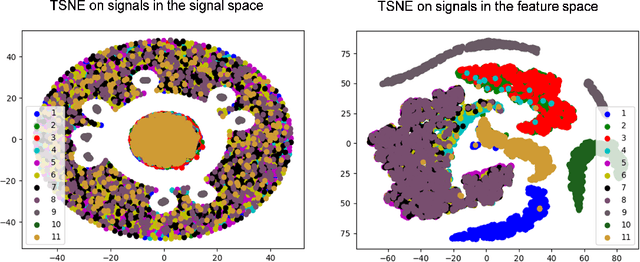
This paper describes a systematic approach towards building a new family of neural networks based on a delay-loop version of a reservoir neural network. The resulting architecture, called Scaled-Time-Attention Robust Edge (STARE) network, exploits hyper dimensional space and non-multiply-and-add computation to achieve a simpler architecture, which has shallow layers, is simple to train, and is better suited for Edge applications, such as Internet of Things (IoT), over traditional deep neural networks. STARE incorporates new AI concepts such as Attention and Context, and is best suited for temporal feature extraction and classification. We demonstrate that STARE is applicable to a variety of applications with improved performance and lower implementation complexity. In particular, we showed a novel way of applying a dual-loop configuration to detection and identification of drone vs bird in a counter Unmanned Air Systems (UAS) detection application by exploiting both spatial (video frame) and temporal (trajectory) information. We also demonstrated that the STARE performance approaches that of a State-of-the-Art deep neural network in classifying RF modulations, and outperforms Long Short-term Memory (LSTM) in a special case of Mackey Glass time series prediction. To demonstrate hardware efficiency, we designed and developed an FPGA implementation of the STARE algorithm to demonstrate its low-power and high-throughput operations. In addition, we illustrate an efficient structure for integrating a massively parallel implementation of the STARE algorithm for ASIC implementation.
Graph Spectral Embedding for Parsimonious Transmission of Multivariate Time Series
Oct 10, 2019



We propose a graph spectral representation of time series data that 1) is parsimoniously encoded to user-demanded resolution; 2) is unsupervised and performant in data-constrained scenarios; 3) captures event and event-transition structure within the time series; and 4) has near-linear computational complexity in both signal length and ambient dimension. This representation, which we call Laplacian Events Signal Segmentation (LESS), can be computed on time series of arbitrary dimension and originating from sensors of arbitrary type. Hence, time series originating from sensors of heterogeneous type can be compressed to levels demanded by constrained-communication environments, before being fused at a common center. Temporal dynamics of the data is summarized without explicit partitioning or probabilistic modeling. As a proof-of-principle, we apply this technique on high dimensional wavelet coefficients computed from the Free Spoken Digit Dataset to generate a memory efficient representation that is interpretable. Due to its unsupervised and non-parametric nature, LESS representations remain performant in the digit classification task despite the absence of labels and limited data.