 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Trojan Detection Competitions with Linear Weight Classification
Nov 05, 2024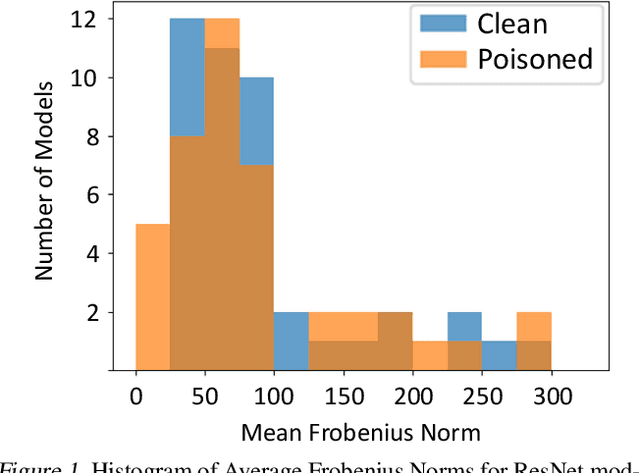
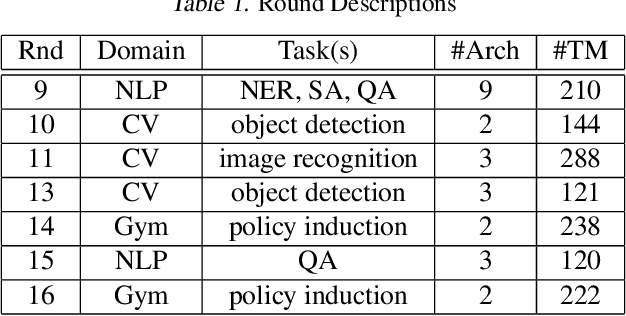
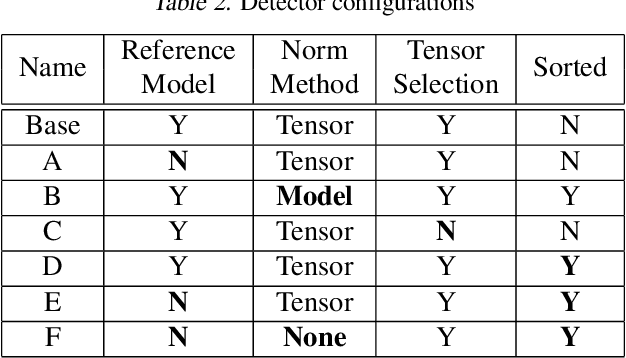
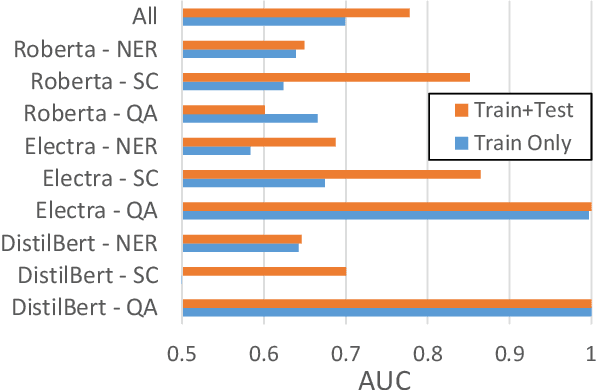
Neural networks can conceal malicious Trojan backdoors that allow a trigger to covertly change the model behavior. Detecting signs of these backdoors, particularly without access to any triggered data, is the subject of ongoing research and open challenges. In one common formulation of the problem, we are given a set of clean and poisoned models and need to predict whether a given test model is clean or poisoned. In this paper, we introduce a detector that works remarkably well across many of the existing datasets and domains. It is obtained by training a binary classifier on a large number of models' weights after performing a few different pre-processing steps including feature selection and standardization, reference model weights subtraction, and model alignment prior to detection. We evaluate this algorithm on a diverse set of Trojan detection benchmarks and domains and examine the cases where the approach is most and least effective.
Limitations of the Lipschitz constant as a defense against adversarial examples
Jul 25, 2018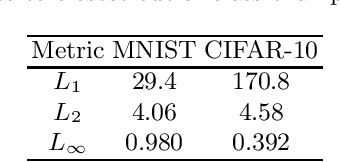
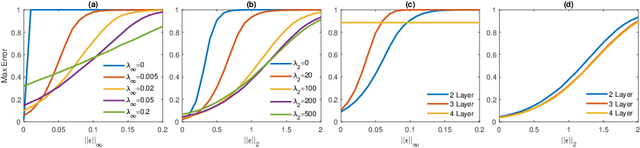
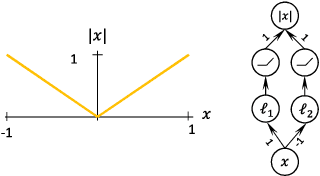
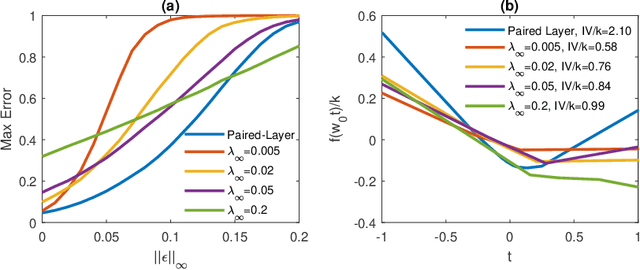
Several recent papers have discussed utilizing Lipschitz constants to limit the susceptibility of neural networks to adversarial examples. We analyze recently proposed methods for computing the Lipschitz constant. We show that the Lipschitz constant may indeed enable adversarially robust neural networks. However, the methods currently employed for computing it suffer from theoretical and practical limitations. We argue that addressing this shortcoming is a promising direction for future research into certified adversarial defenses.