 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Symbolic Open Source Information Discovery
Aug 20, 2024Combined, joint, intra-governmental, inter-agency and multinational (CJIIM) operations require rapid data sharing without the bottlenecks of metadata curation and alignment. Curation and alignment is particularly infeasible for external open source information (OSINF), e.g., social media, which has become increasingly valuable in understanding unfolding situations. Large language models (transformers) facilitate semantic data and metadata alignment but are inefficient in CJIIM settings characterised as denied, degraded, intermittent and low bandwidth (DDIL). Vector symbolic architectures (VSA) support semantic information processing using highly compact binary vectors, typically 1-10k bits, suitable in a DDIL setting. We demonstrate a novel integration of transformer models with VSA, combining the power of the former for semantic matching with the compactness and representational structure of the latter. The approach is illustrated via a proof-of-concept OSINF data discovery portal that allows partners in a CJIIM operation to share data sources with minimal metadata curation and low communications bandwidth. This work was carried out as a bridge between previous low technology readiness level (TRL) research and future higher-TRL technology demonstration and deployment.
SEEC: Semantic Vector Federation across Edge Computing Environments
Aug 30, 2020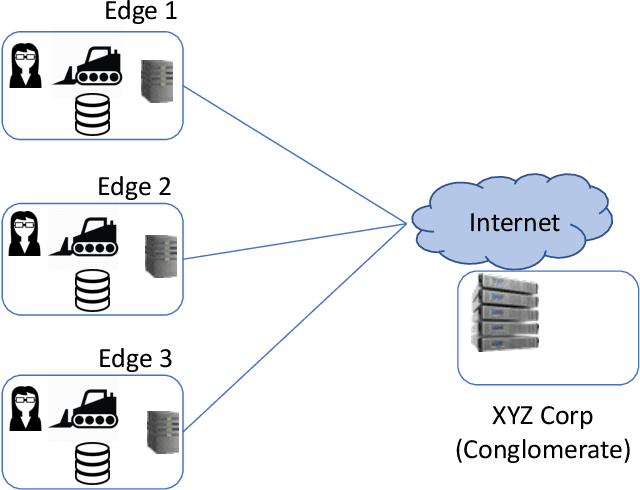
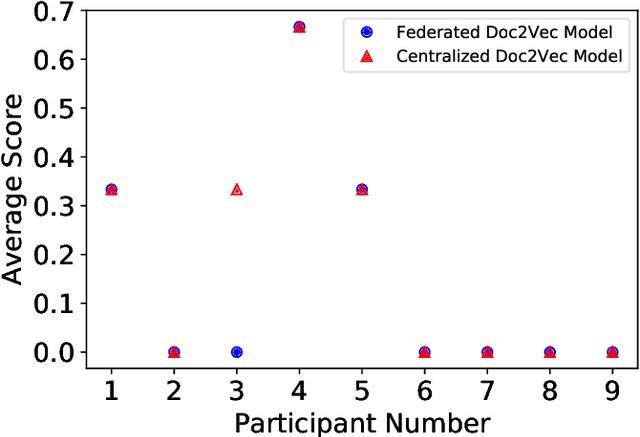


Semantic vector embedding techniques have proven useful in learning semantic representations of data across multiple domains. A key application enabled by such techniques is the ability to measure semantic similarity between given data samples and find data most similar to a given sample. State-of-the-art embedding approaches assume all data is available on a single site. However, in many business settings, data is distributed across multiple edge locations and cannot be aggregated due to a variety of constraints. Hence, the applicability of state-of-the-art embedding approaches is limited to freely shared datasets, leaving out applications with sensitive or mission-critical data. This paper addresses this gap by proposing novel unsupervised algorithms called \emph{SEEC} for learning and applying semantic vector embedding in a variety of distributed settings. Specifically, for scenarios where multiple edge locations can engage in joint learning, we adapt the recently proposed federated learning techniques for semantic vector embedding. Where joint learning is not possible, we propose novel semantic vector translation algorithms to enable semantic query across multiple edge locations, each with its own semantic vector-space. Experimental results on natural language as well as graph datasets show that this may be a promising new direction.
SENSE: Semantically Enhanced Node Sequence Embedding
Nov 07, 2019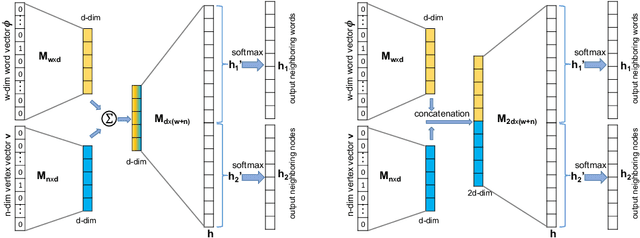
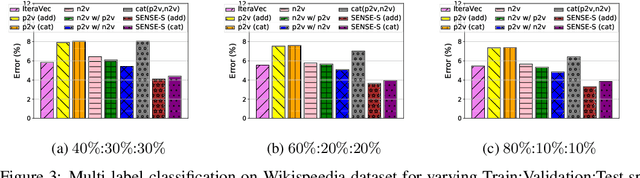
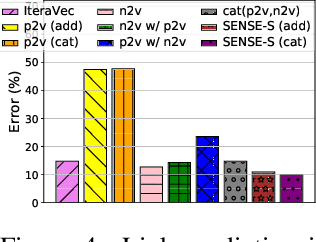
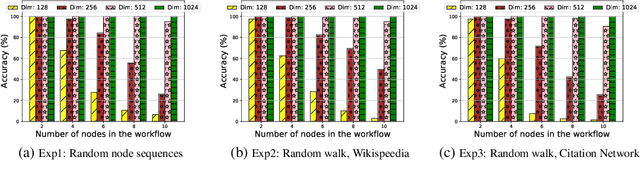
Effectively capturing graph node sequences in the form of vector embeddings is critical to many applications. We achieve this by (i) first learning vector embeddings of single graph nodes and (ii) then composing them to compactly represent node sequences. Specifically, we propose SENSE-S (Semantically Enhanced Node Sequence Embedding - for Single nodes), a skip-gram based novel embedding mechanism, for single graph nodes that co-learns graph structure as well as their textual descriptions. We demonstrate that SENSE-S vectors increase the accuracy of multi-label classification tasks by up to 50% and link-prediction tasks by up to 78% under a variety of scenarios using real datasets. Based on SENSE-S, we next propose generic SENSE to compute composite vectors that represent a sequence of nodes, where preserving the node order is important. We prove that this approach is efficient in embedding node sequences, and our experiments on real data confirm its high accuracy in node order decoding.