 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEEC: Semantic Vector Federation across Edge Computing Environments
Aug 30, 2020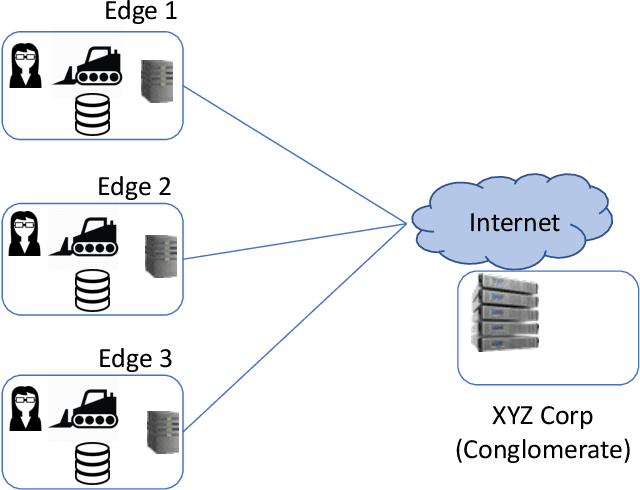
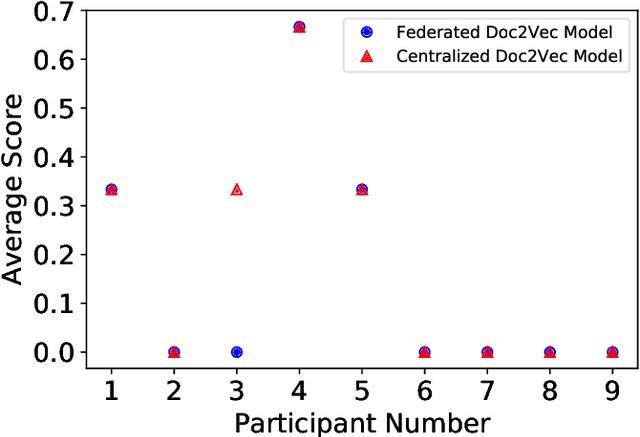


Semantic vector embedding techniques have proven useful in learning semantic representations of data across multiple domains. A key application enabled by such techniques is the ability to measure semantic similarity between given data samples and find data most similar to a given sample. State-of-the-art embedding approaches assume all data is available on a single site. However, in many business settings, data is distributed across multiple edge locations and cannot be aggregated due to a variety of constraints. Hence, the applicability of state-of-the-art embedding approaches is limited to freely shared datasets, leaving out applications with sensitive or mission-critical data. This paper addresses this gap by proposing novel unsupervised algorithms called \emph{SEEC} for learning and applying semantic vector embedding in a variety of distributed settings. Specifically, for scenarios where multiple edge locations can engage in joint learning, we adapt the recently proposed federated learning techniques for semantic vector embedding. Where joint learning is not possible, we propose novel semantic vector translation algorithms to enable semantic query across multiple edge locations, each with its own semantic vector-space. Experimental results on natural language as well as graph datasets show that this may be a promising new direction.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020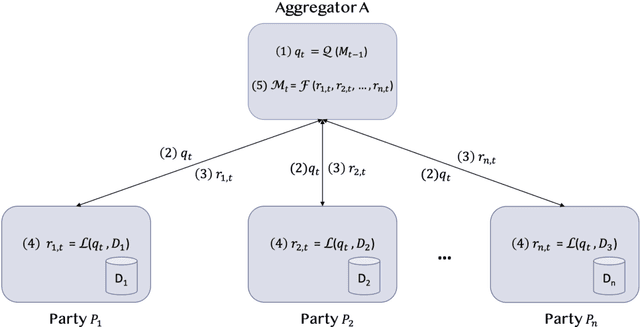
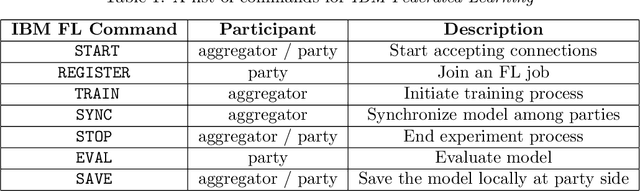
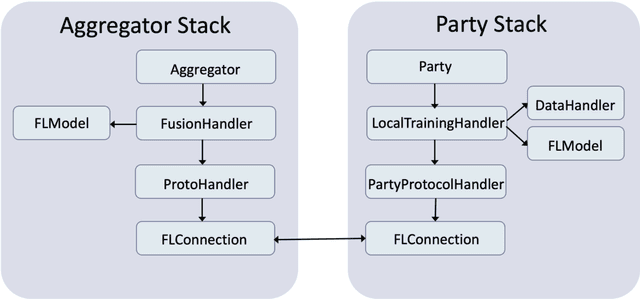
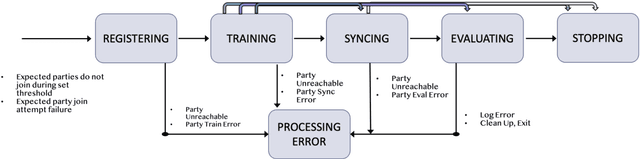
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.