 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Your Metric Telling You? Evaluating Classifier Calibration under Context-Specific Definitions of Reliability
May 23, 2022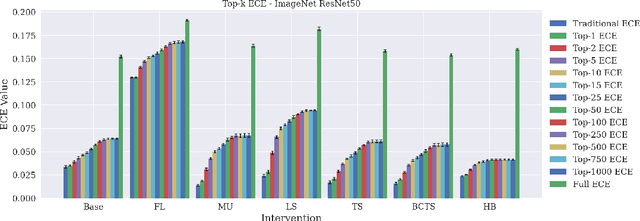
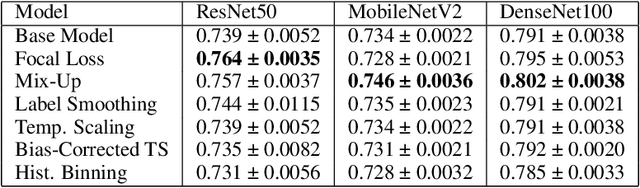
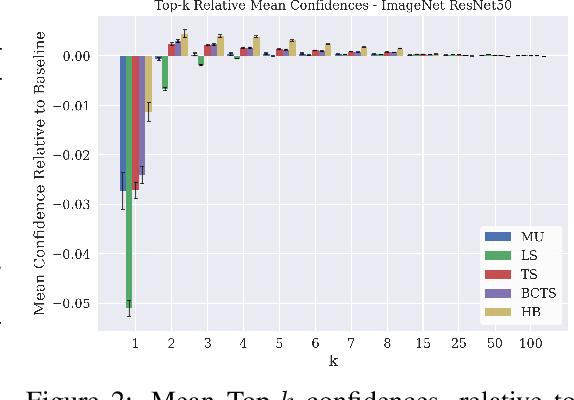
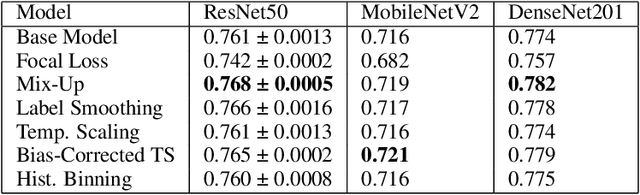
Classifier calibration has received recent attention from the machine learning community due both to its practical utility in facilitating decision making, as well as the observation that modern neural network classifiers are poorly calibrated. Much of this focus has been towards the goal of learning classifiers such that their output with largest magnitude (the "predicted class") is calibrated. However, this narrow interpretation of classifier outputs does not adequately capture the variety of practical use cases in which classifiers can aid in decision making. In this work, we argue that more expressive metrics must be developed that accurately measure calibration error for the specific context in which a classifier will be deployed. To this end, we derive a number of different metrics using a generalization of Expected Calibration Error (ECE) that measure calibration error under different definitions of reliability. We then provide an extensive empirical evaluation of commonly used neural network architectures and calibration techniques with respect to these metrics. We find that: 1) definitions of ECE that focus solely on the predicted class fail to accurately measure calibration error under a selection of practically useful definitions of reliability and 2) many common calibration techniques fail to improve calibration performance uniformly across ECE metrics derived from these diverse definitions of reliability.